现在很多AI Infra的工作都会用到Tensor Core做加速或性能优化,看的论文里也经常会出现mma的字眼、以及mma指令对应的Fragment Layout图(原来的矩阵如何被拆成另一种布局方式)等等。在Tensor Core的计算过程,数据会频繁流动的地方——显存、共享内存、L1、L2等等,他们又是如何协调的,这些比较抽象的过程总是困扰我很久,所以就想好好探讨一下这些知识。
在搜索资料时发现 旷视MegEngine TensorCore 卷积算子实现原理这一篇讲得比较详细的,我想在其基础上再梳理一下。文章的后续大部分内容来自这篇文章。
1 Tensor Core能解决什么
先简短介绍Tensor Core:
Tensor Core是专门实现小块矩阵乘法$D=A×B+C$的硬件单元,相比CUDA Core,虽然功能单一,但是速度极快。
这里有两个概念,Tensor Core和Cuda Core,下面就解释一下他们的特点以及应用场景。
部分内容来源:
1.1 GPU的核心
GPU的核心有三种:
- CUDA Core:
- Tensor Core
- RT Core
1.1.1 CUDA Core
CUDA的基本计算单元是SM(Streaming Multiprocessor,流式多处理器),从硬件组织的角度看,多个CUDA Core被集成到1个SM中,而1个SM可以同时调度和执行数百个线程。这就是CUDA高吞吐量、并行计算能力特点的基础来源。
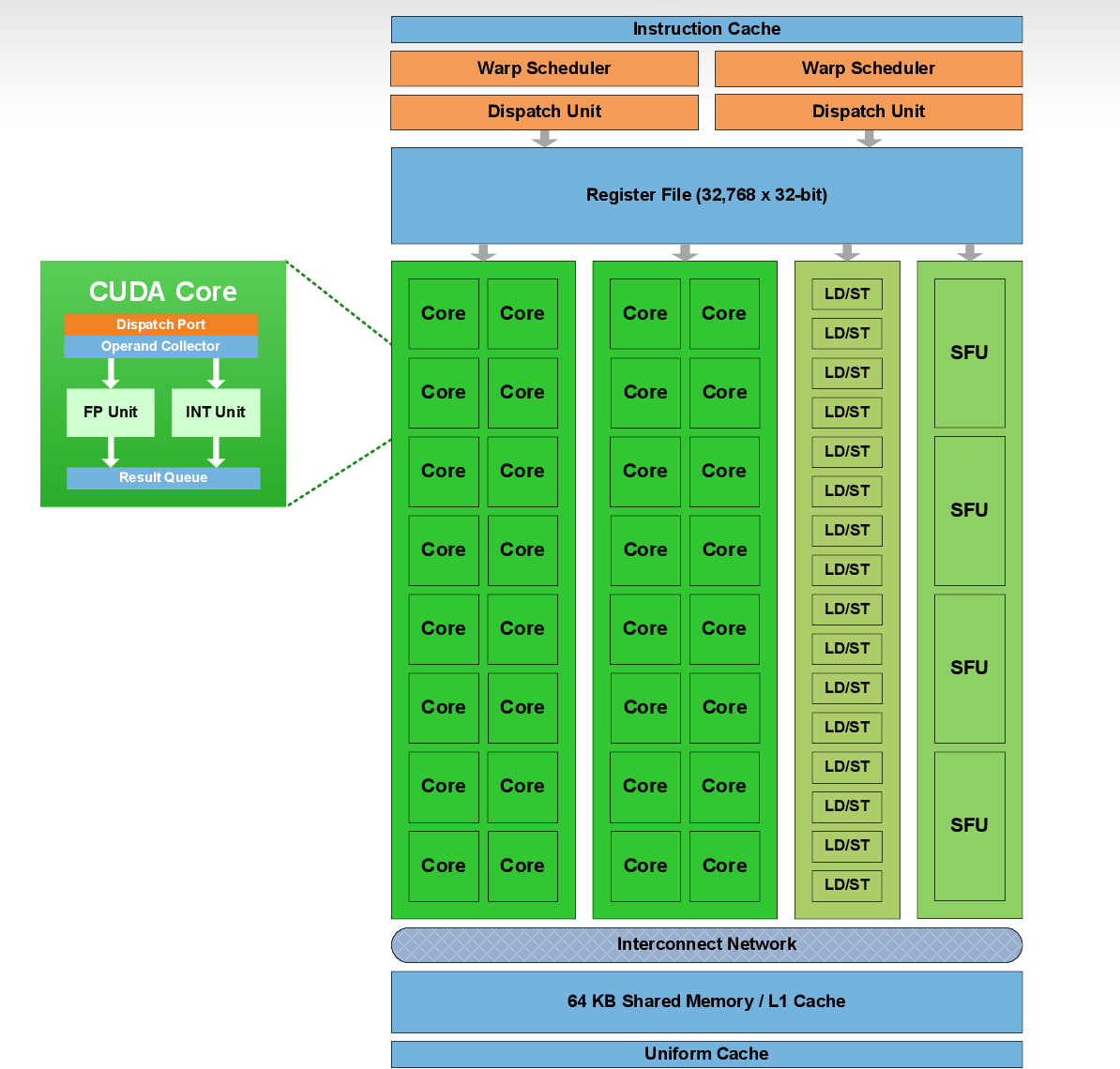
上图这张图是Fermi架构下,CUDA的基本计算单元SM,包含了两个Warp Scheduler(线程束调度器),32K个32位寄存器,32个CUDA Core。
- 每个Cuda Core由1个浮点数单元FPU和1个逻辑运算单元ALU组成
- 浮点数单元FPU一般是FP32,Pascal SM内部出现了DP Unit,即FP64的CUDA Core。
- 逻辑运算单元ALU是INT32,Volta架构的SM里的INT32实现与FP32的物理隔离。
- (Fermi架构下)在同一个时钟周期里,要么FPU干活,要么ALU干活,不能同时开工,之后的新架构(Volta/Turnig之后)就改变了这一状态,让二者分开。
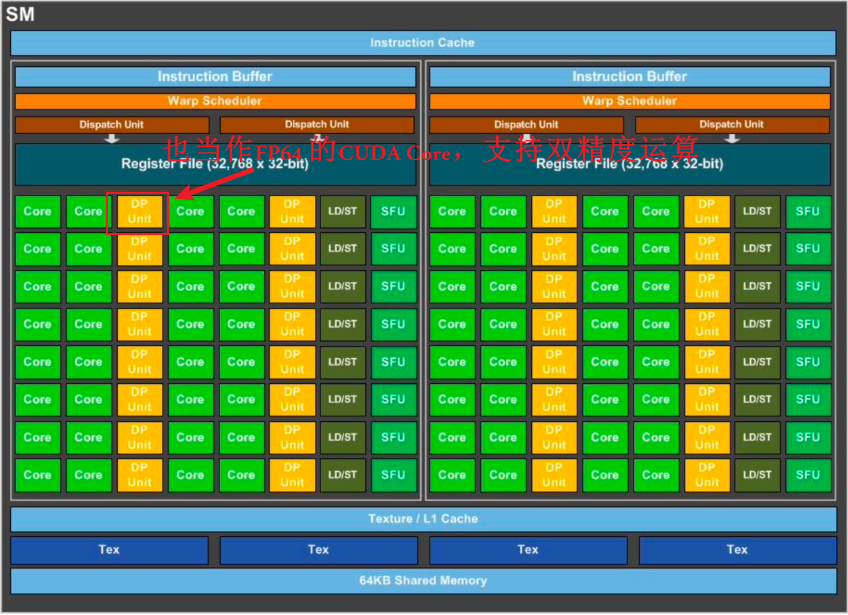
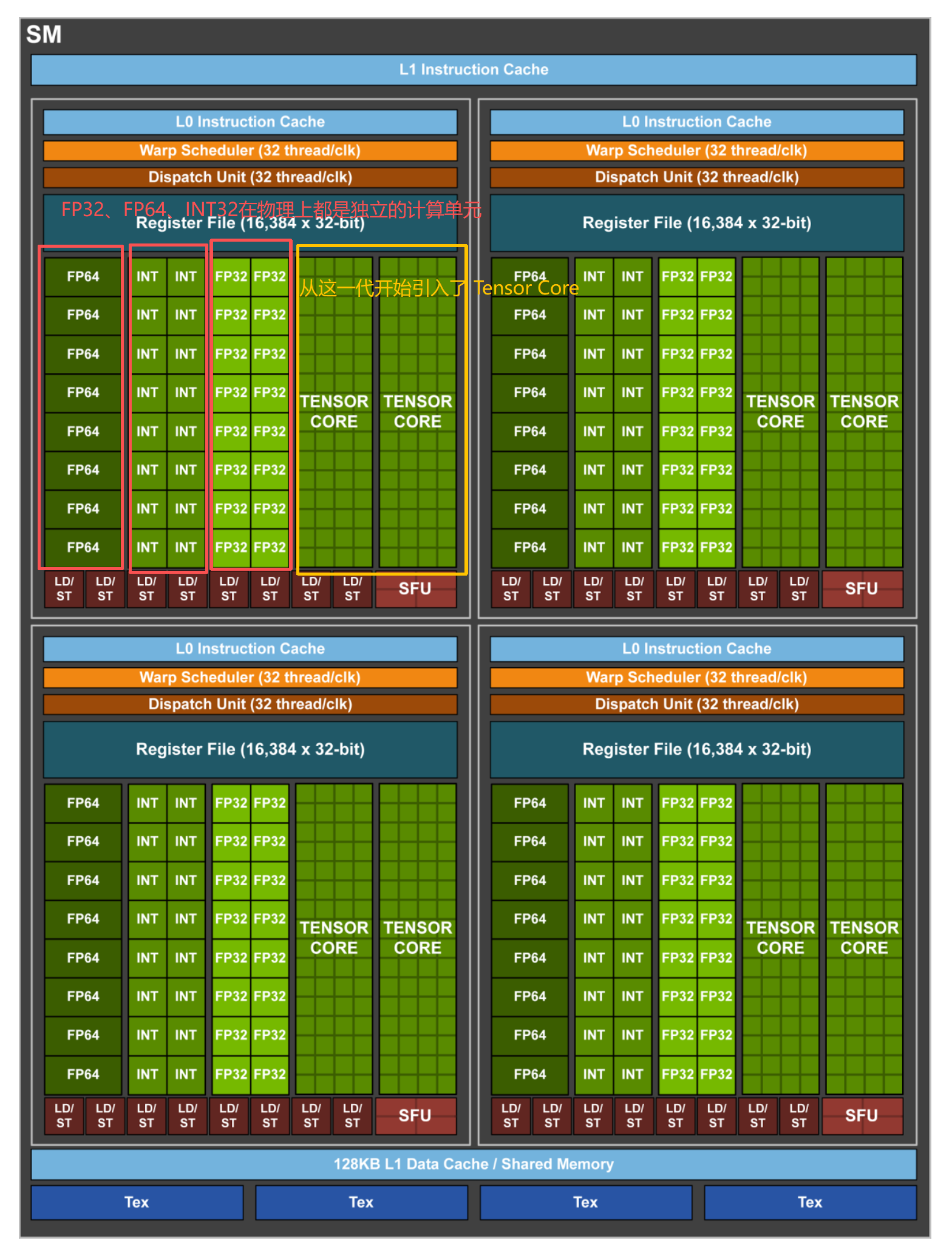
- CUDA Core可以进行FMA(fused multiply-add),即加乘操作的融合$y=wx+b$,单指令就可以完成,这些CUDA Core在显卡里并行计算,如果CUDA Core越多,算力也会越强。
1.1.2 Tensor Core
在上面的图中,Volta架构的SM引入了Tensor Core。
CUDA Core在一个时钟周期里,只能接收三个数字$w$、$x$、$b$,做一次FMA(乘加运算),如果要计算4×4的矩阵乘法,就需要调用大量CUDA Core,通过循环去算行列的点积。
Tensor Core专门处理矩阵计算,并且支持混合精度,就是输入矩阵的精度是FP16,但是最终输出结果可以是FP16或者FP32,计算量减少但是保证了输出的精度。
Tensor Core在一个时钟周期内能执行4×4×4的GEMM(general matrix multiply,矩阵乘加)运算,相当于同时进行64个FMA计算。
可以看出,相比CUDA Core,Tensor Core在计算量、精度、指令数上都有很大的优化。
2 TensorCore做计算的过程
这一部分的内容主要是探讨基于Tensor Core的mma指令底层计算机制,并梳理了数据在Global Memory、Shared Memory与寄存器如何实现swizzle(内存交错)、物理排布优化。
在阅读本部分之前,读者需要了解的CUDA知识有:
- 访问全局内存时,同一warp中的相邻线程访问连续的地址时,或者说一个warp对全局内存的一次访问使用了最少的数据传输时,就称为合并访存,能最大化全局内存的吞吐。
- 访问全局内存时,尽可能使用最宽的数据类型(float4)进行访问,可以最大化访存指令的利用率。下面是分别用float和float4做内存拷贝时的性能(rtx3050)
- [float] Time: 4.36634 ms, Bandwidth: 183.22 GB/s
- [float4]Time: 4.27924 ms, Bandwidth: 186.949 GB/s
- 可见float4还是比float快一点的,查看其ptx代码
ld.global.f32 %f1, [%rd5];和ld.global.v4.u32 {%r6, %r7, %r8, %r9}, [%rd7];前者一次只取32位(f32),后者一次取128位(u32)分别放到4个寄存器里,充分利用带宽。
- 共享内存按照每4个bytes划分为一个bank,共分为32个bank,一个bank之所以是4bytes是因为一个float或int数据都是4bytes,当申请共享内存时,数据会被依次发放给32个bank,刚好把bank填充完。当同一warp的线程访问同一bank的不同地址时会发生banck conflit(bank 冲突),如果访问同一bank的相同地址,不会发生冲突,因为有broacast(广播)机制。只有不发生bank conflit才能最大化共享内存的吞吐。
- GPU有显存(Global Memory)、L2、L1(Shared Memory)、寄存器4个层次的存储,直接访问显存的延迟很高,在优化GEMM这种计算型密集的算子时,需要:
- 通过Shared Memory和寄存器减少访存请求次数
- 通过大量计算触发多线程并发机制或双缓冲机制隐藏访存延迟
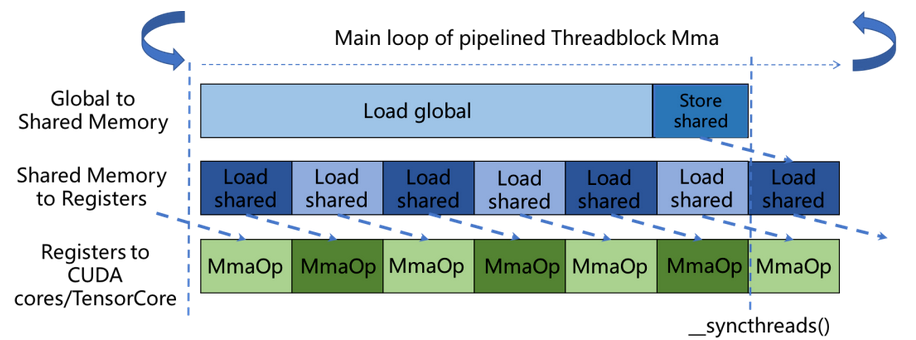
数据在真正参与运算前,通常会按照Global Memory -> Shared Memory -> Register的层级路径进行逐级搬运。下面的介绍均以完成m8n8k16的GEMM为例。
2.1 GMEM→SMEM
2.1.1 GMEM下的数据布局
根据2.2.1,每个线程处理16个int8类型的数据,每16个元素被当作1个vector。下图是同一个warp中每个线程读取Global Memory的数据的逻辑布局: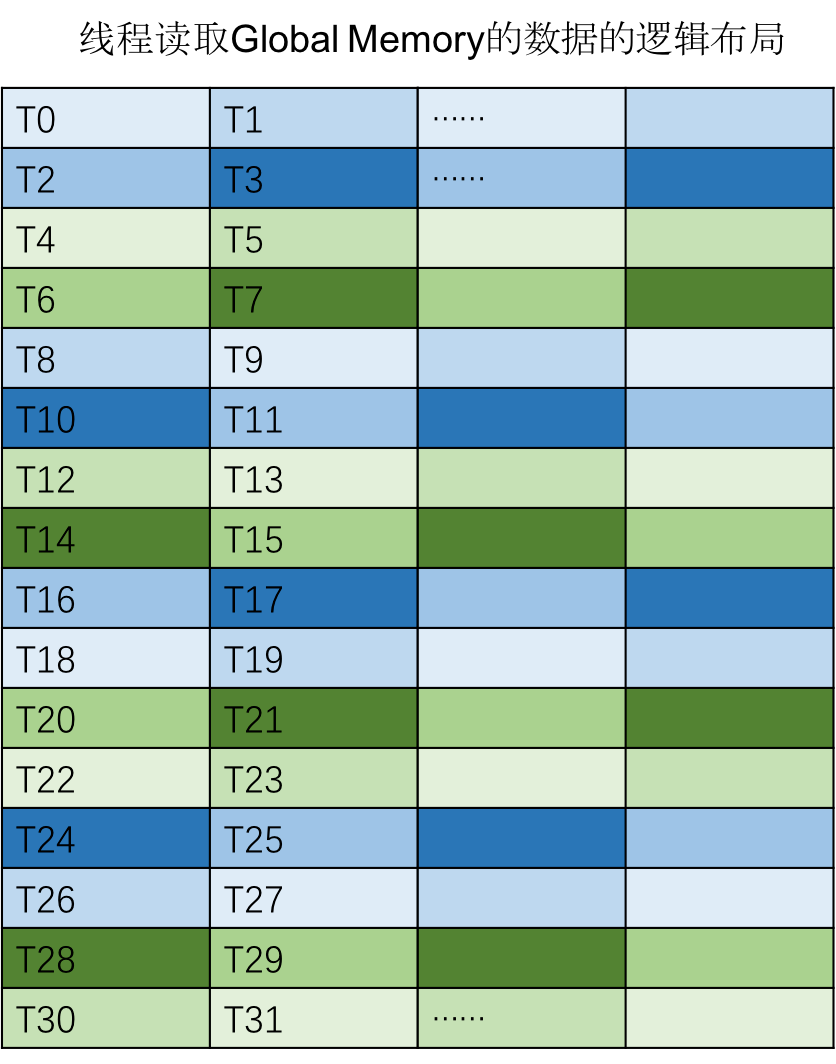
- 【❓】为什么逻辑布局是这样的
而实际的物理布局是:
- 每个线程负责16个int8元素,一共128bits
- 相邻的线程读取的数据在物理上是连续的,可以满足合并访存需求
从Global Memory写入Shared Memory时,物理布局如下: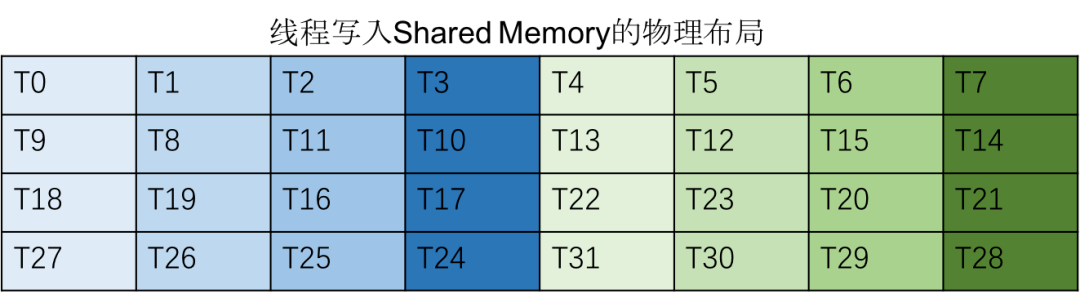
- 每8个线程向Shared Memory写入128bits的数据,刚好落在Shared Memory的32个不同的bank中
- 同一warp的访存分为四个阶段完成,T0~T7为第一阶段,T8~T15为第二阶段,T16~T23为第三阶段,T24~T23为第三阶段
- 物理布局下线程的排布是交错的,这和Shared Memory的bank conflict有关
2.1.2 SMEM下的数据布局
前面已经简要介绍了Shared Memory下的bank及其对访存效率的影响,通常为了避免Shared Memory的bank conflict,会对Shared Memory的数据进行padding,让同一warp下的线程访问的数据错开,避免落在同一bank中。但是这样做的问题是会使得kernel需要Shared Memory的Size变大,但是SM上的L1 cache(Shared Memory)又是有限的,所以padding会降低kernel的occupancy,进而就会降低kernel的性能。
因此CUTLASS设计了一种Shared Memory的交错布局方式,它能够在不进行padding的前提下,使得线程访存的地址没有bank conflict。接下来,我们以64x64的矩阵为例来详细介绍数据在Shared Memory中的布局。
此时线程读取的数据粒度都是128bits,即16个int8类型的数据,所以下面的每个格子都是以16个数据为一组,也称为一个vector。下面是Shared Memory的数据的逻辑布局: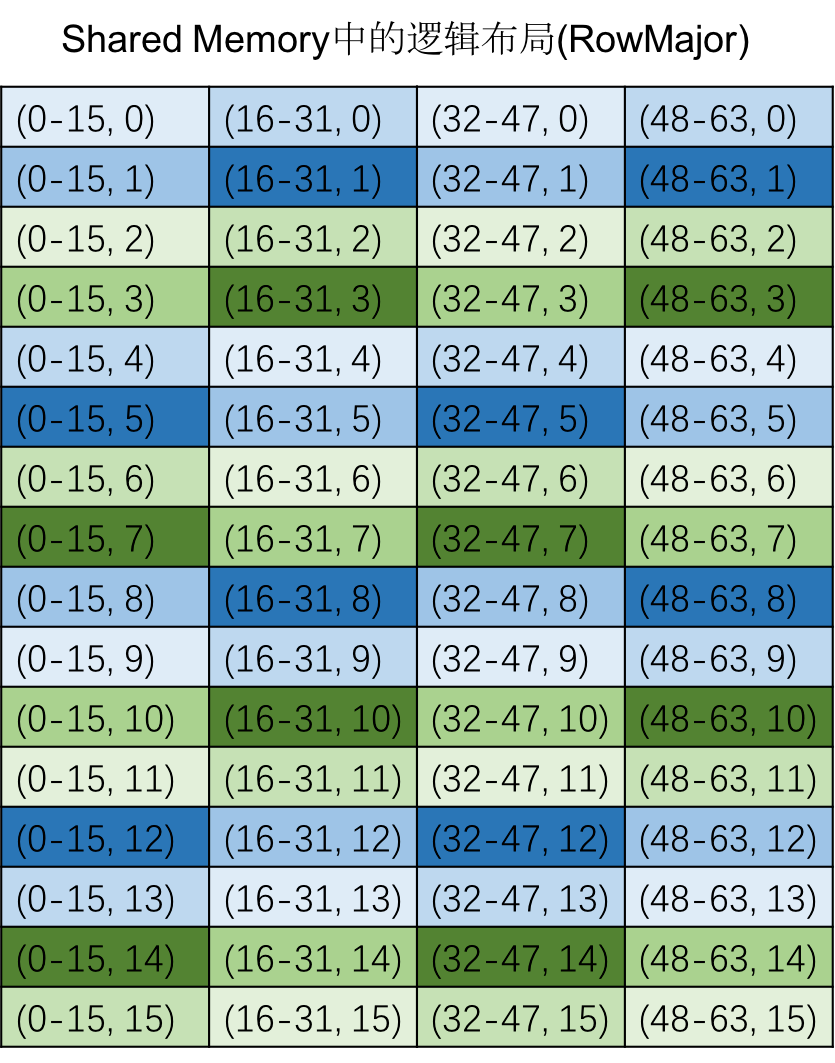
- 16个int8类型的数据为一组,被称为一个vector,是不同颜色的格子
- 每行相邻的32个元素被称为一个crosswise,是NCHW32里一组channel的数据(背景是Tensor Core卷积算子吞吐优化,采用32个通道对齐的存储格式)
ldmatrix以矩阵块形式读取数据,而不是在一行里从头读到尾,所以要把需要读取的数据重新排序,下面是Shared Memory的数据的物理布局: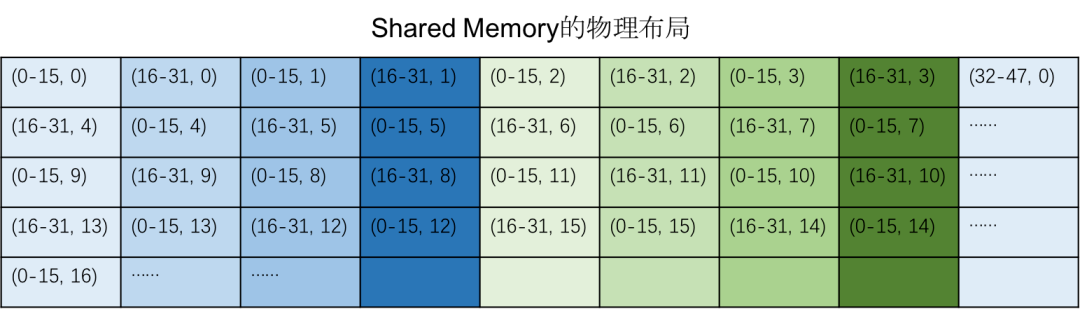
- 逻辑布局的每4行的一个crosswise数据为一组,连续存放在Shared Memory中,然后存放这四行的下一个crosswise数据
- 每组数据包含8个vector,8×16×8bits÷8 = 128bytes,恰好对应Shared Memory的32个bank,能填满一次bank的最大吞吐量
- 每组数据在排列中交错,保证ldmatreix时不发生bank conflict。假设没有这种错位,第 0 行的 (0-15, 0) 和第4行的 (0-15, 4) 会被存放在完全相同编号的 Bank 里(因为内存地址相差正好是 128 字节的倍数,Bank 循环了一圈又对齐了)。当 Warp 中的不同线程使用 ldmatrix 同时去要第 0 行和第 4 行的数据时,它们就会挤在同一个 Bank 柜员面前,发生惨烈的Bank Conflict。
2.2 SMEM→R
在执行warp级别的GEMM运算时,核心依赖于两条Warp-level指令的紧密协同:ldmatrix指令负责将矩阵数据从Shared Memory高效加载并重新排布到线程的Fragment寄存器中;而mma 指令则直接驱动Tensor Core,对这些排布好的数据进行高速的张量乘加计算。
- warp级别的GEMM运算,有别于CUDA Core计算矩阵乘法时一个线程负责输出结果矩阵的一个元素或几个元素的模式,它打破了线程间的隔离,强制要求一个warp内的32个线程进行底层的数据共享与严格同步,协同算出一整个矩阵块。
mma.sync指令就体现了同步的特点。
2.2.1 ldmatrix指令
ldmatrix是PTX指令,从Shared Memory读取数据,把数据打包成warp-level的矩阵片段,将数据搬运到registers里。
当同一个warp执行空间上连续的两个8×8×16的GEMM时,数据要从Global Memory搬运到Shared Memory然后再使用ldmatrix指令读取数据,如果按照以上mma指令下矩阵的布局布来读取顺序,那么每个线程读取数据时都只能读32bits的数据,跳过一段内存之后再读取下一个32bits的数据,这样的带宽利用率很低。而ldmatrix能够让warp一次性读取4个8×16的矩阵到寄存器里,这样warp里的每个线程读取4×8×16×8bit/32=128bit的数据。
ldmatrix.sync.aligned.x4.m8n8.shared.b16这个指令刚好可以读取4个8×16矩阵,笔者一开始疑惑这为什么不是处理4个8×8矩阵呢?直到注意到b16的存在,总数据量=4×8×8×16bits=4096bits,因为矩阵的数据类型是int8,所以一个16bit单元里有2个int8元素,物理列数是8,逻辑列数是16,所以就符合4个8×(8×2)矩阵了。
下面的图的三个阶段分别是线程做数据读取、线程之间数据交换、最终线程读取的数据(以线程0为例)。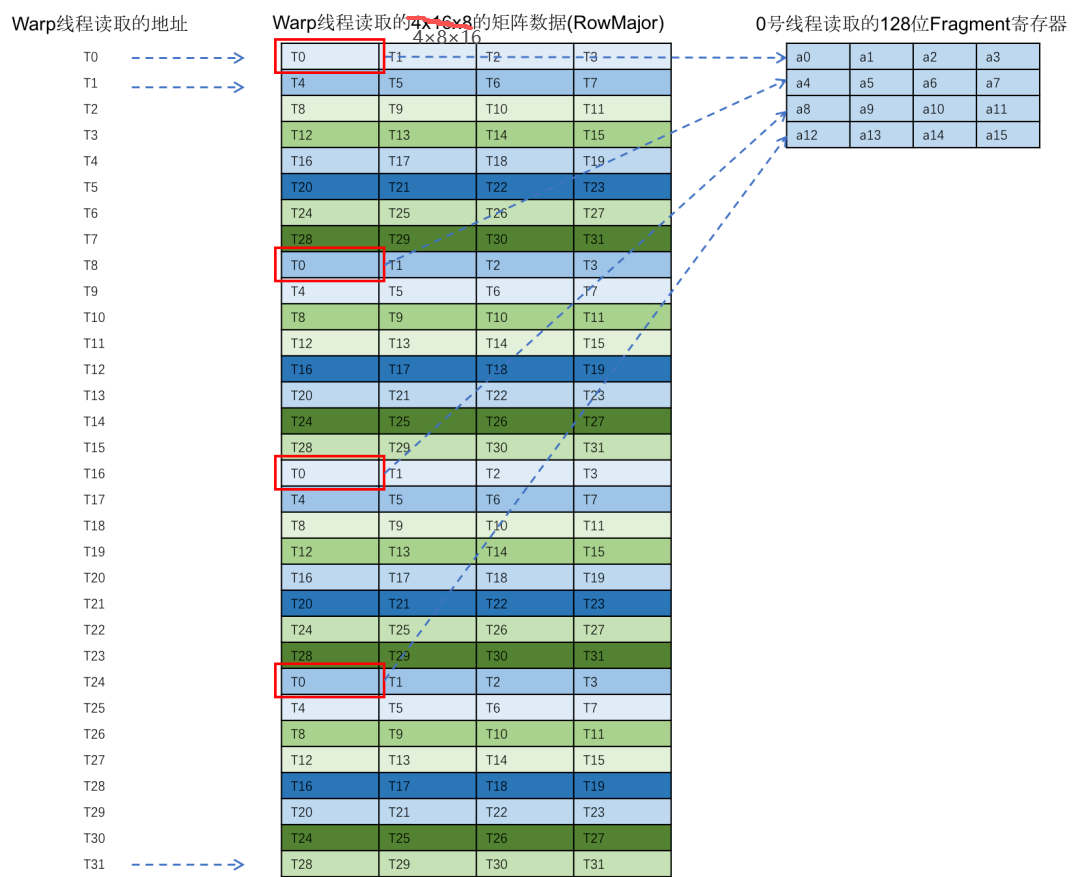
- 32个线程都分别加载(即读取)一行数据,一行有4×4个int8类型的数据,一共128bits
- 数据加载时的每个线程与对应数据的分布,并不是最终在寄存器里的排布,加载后线程之间做数据交换,线程0最后分配到的数据是由线程0、8、16、24加载而来的
同一warp在每一轮迭代过程会读取4个8x16的矩阵到寄存器中,每个线程会读取一行的数据。例如第一轮迭代时,线程读取的数据在逻辑上的布局如下图所示: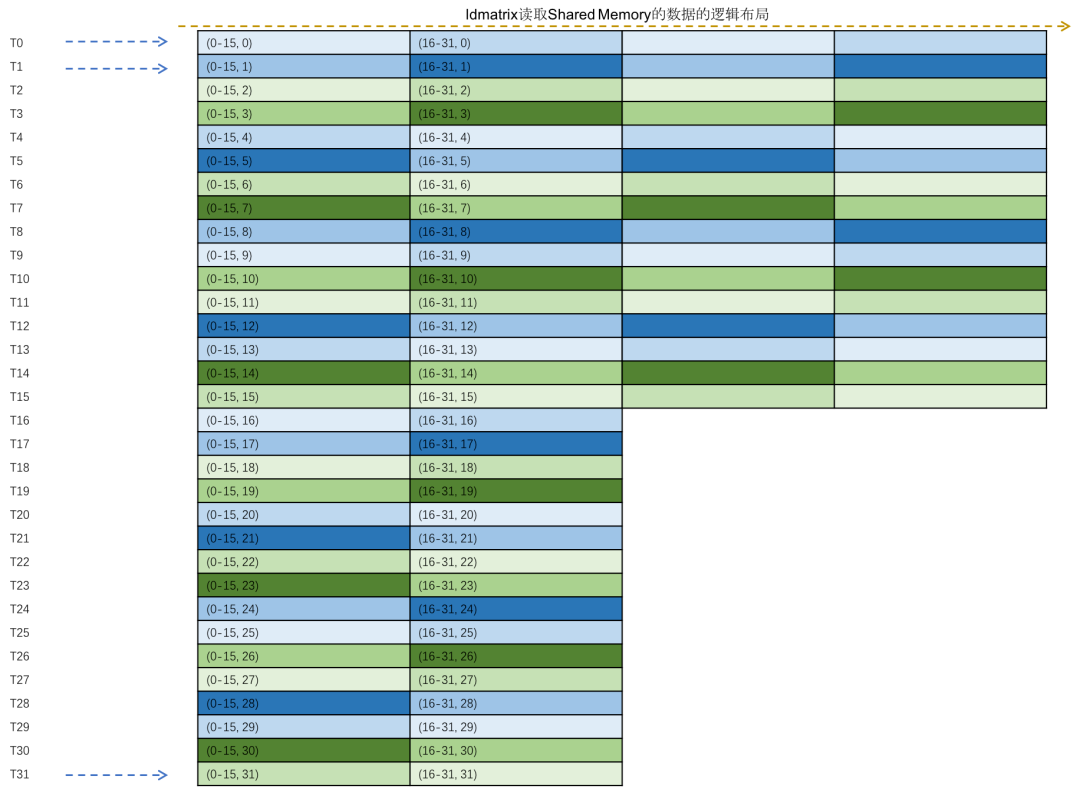
而实际上数据在Shared Memory里的物理布局如下图: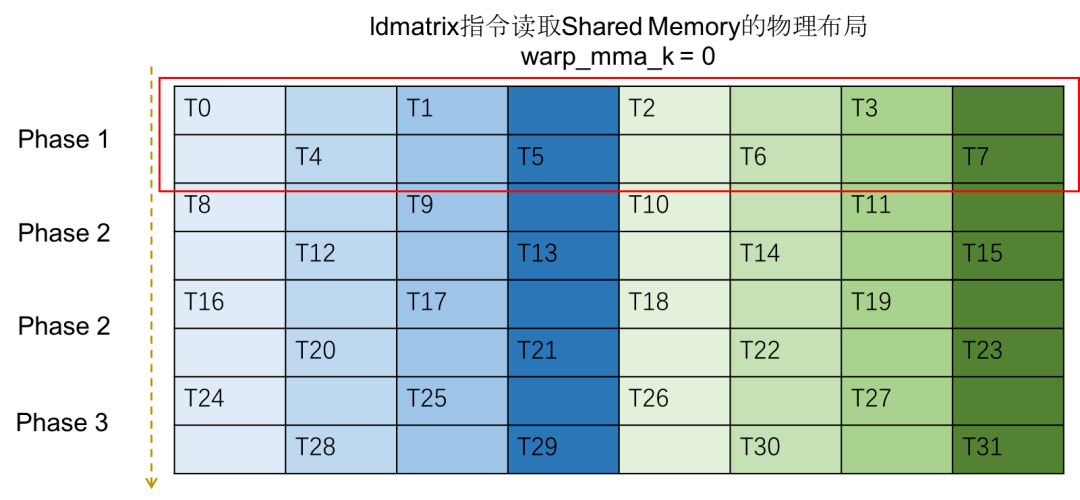
- 参照下面的两幅图,可以理解成这里在取Shared Memory逻辑布局里最左边一列的数据
- 每个线程读取了128位的数据,因此访存分为四个阶段来进行。
- 每一阶段的8个线程读取的数据恰好落在了Shared Memory的32个bank中,并且线程访存的数据之间不存在冲突。
- Shared Memory的逻辑排布和上面ldmatrix读取时的排布一样
当进行到第二轮迭代时,每个线程访问的数据的物理布局如下图: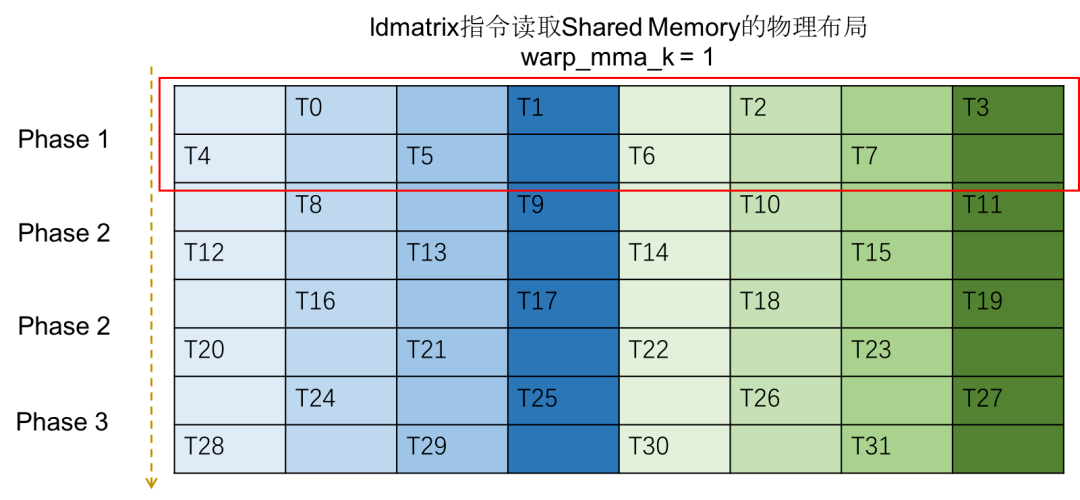
- 可以理解成这里在取Shared Memory逻辑布局里第二列的数据
将数据搬运完成后就用mma指令做计算了。
2.2.2 mma指令
以mma.sync.aligned.m8n8k16.row.col.satfinite.s32.s8.s8.s32为例,它是一个PTX汇编指令,由一个warp的32个线程同步地完成m8n8k16的$D=A×B+C$的GEMM。
其中A矩阵大小为8×16、B矩阵大小为16×8、C和D矩阵大小为8×8,这些数据分布在同一个warp里的32个线程中。
矩阵A的布局如下:
- Txx表示id为xx的线程,a0~a3表示这个线程负责的4个数据,每4个线程负责读取8×16矩阵的一行
矩阵B的布局如下: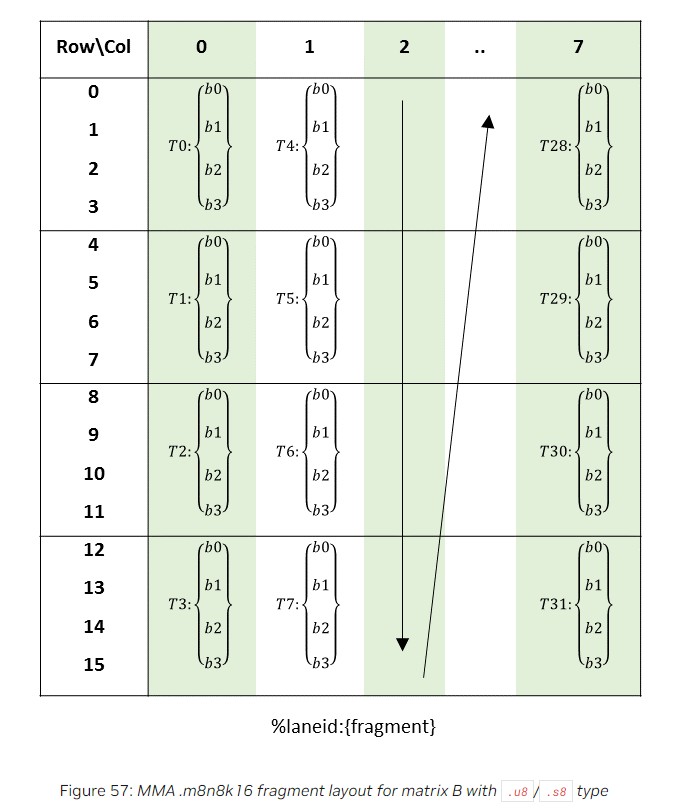
- 每4个线程负责读取矩阵的一列
对于矩阵A和矩阵B,一共有8×16=128个数据,且两个输入矩阵的类型都是signed 8-bit integer(即int8),32个线程里的每个线程处理4个数据,4×8bits=32bits,实际声明A或B寄存器大小时只需要1个32位unsigned int就可以。

对于矩阵C和矩阵D,一共有8×8=64个数据,且两个矩阵的类型都是signed 32-bit integer(即int32),32个线程里每个线程处理2个数据,2×32bits=64bits,实际声明C或D寄存器大小需要2个int32。



