现在很多AI Infra的工作都会用到Tensor Core做加速或性能优化,看的论文里也经常会出现mma的字眼、以及mma指令对应的Fragment Layout图(原来的矩阵如何被拆成另一种布局方式)等等。在Tensor Core的计算过程,数据会频繁流动的地方——显存、共享内存、L1、L2等等,他们又是如何协调的,这些比较抽象的过程总是困扰我很久,所以就想好好探讨一下这些知识。
在搜索资料时发现 旷视MegEngine TensorCore 卷积算子实现原理这一篇讲得比较详细的,我想在其基础上再梳理一下。文章的后续大部分内容来自这篇文章。
1 Tensor Core能解决什么
先简短介绍Tensor Core:
Tensor Core是专门实现小块矩阵乘法$D=A×B+C$的硬件单元,相比CUDA Core,虽然功能单一,但是速度极快。
这里有两个概念,Tensor Core和Cuda Core,下面就解释一下他们的特点以及应用场景。
部分内容来源:
1.1 GPU的核心
GPU的核心有三种:
- CUDA Core:
- Tensor Core
- RT Core
1.1.1 CUDA Core
CUDA的基本计算单元是SM(Streaming Multiprocessor,流式多处理器),从硬件组织的角度看,多个CUDA Core被集成到1个SM中,而1个SM可以同时调度和执行数百个线程。这就是CUDA高吞吐量、并行计算能力特点的基础来源。
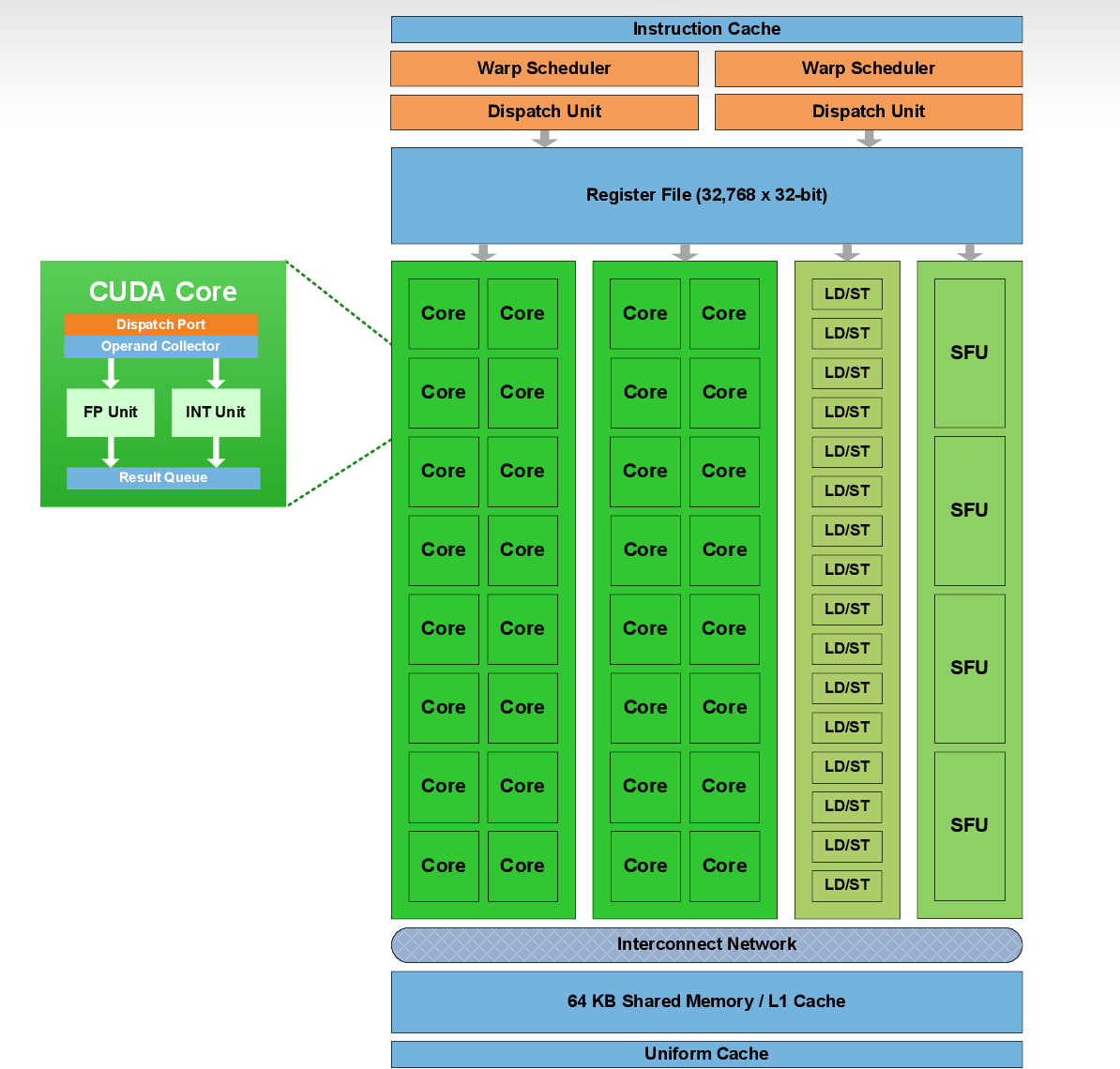
上图这张图是Fermi架构下,CUDA的基本计算单元SM,包含了两个Warp Scheduler(线程束调度器),32K个32位寄存器,32个CUDA Core。
- 每个Cuda Core由1个浮点数单元FPU和1个逻辑运算单元ALU组成
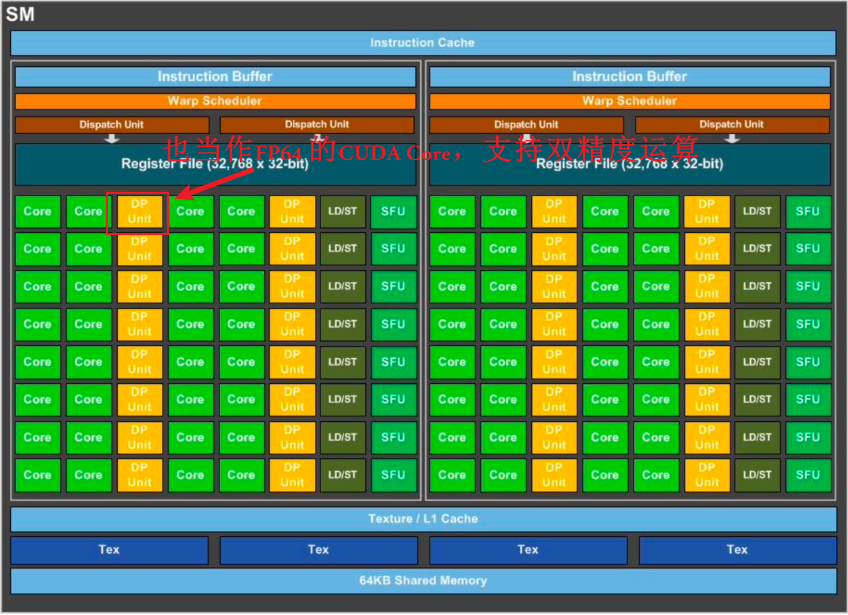
- 浮点数单元FPU一般是FP32,Pascal SM内部出现了DP Unit,即FP64的CUDA Core。
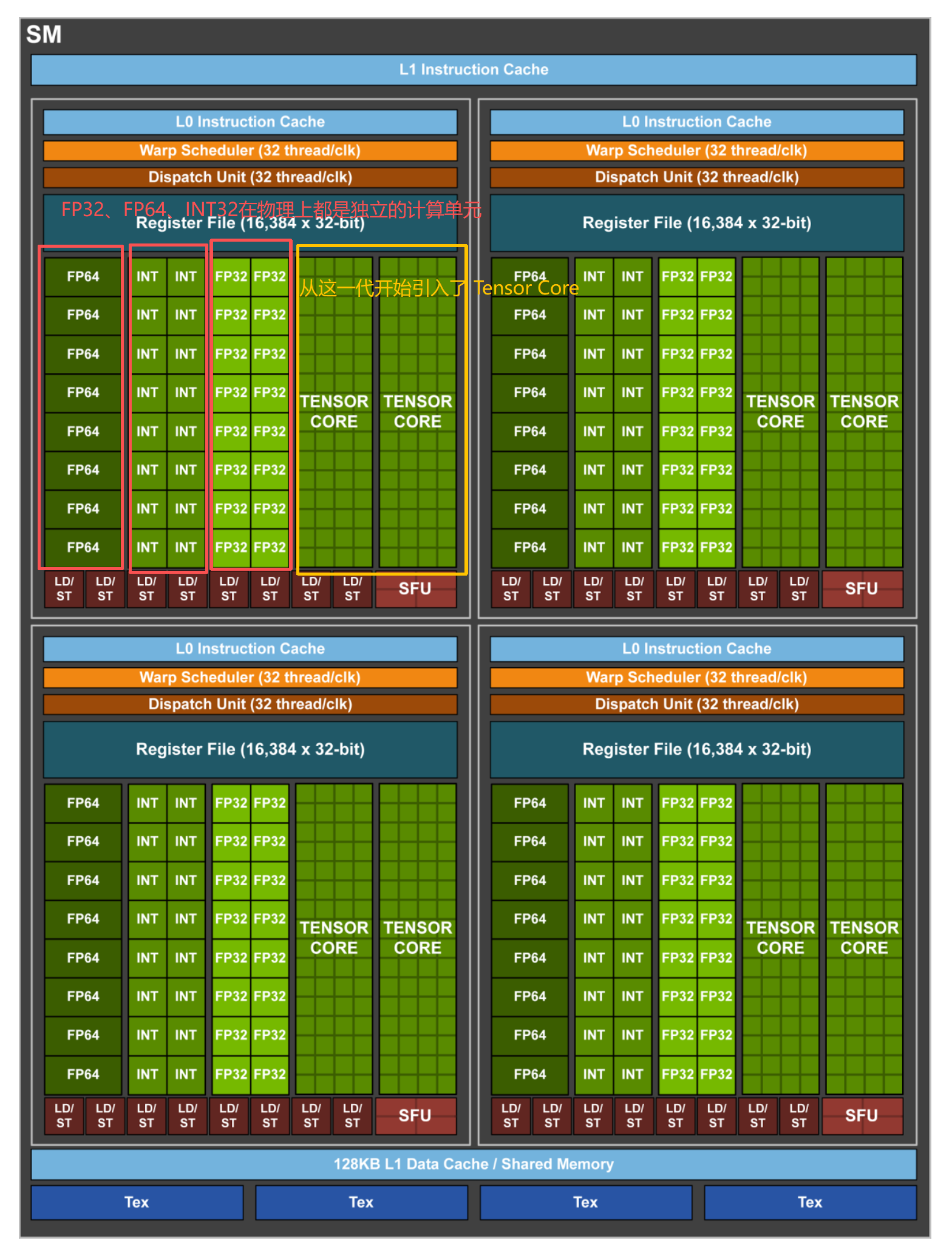
- 逻辑运算单元ALU是INT32,Volta架构的SM里的INT32实现与FP32的物理隔离。
- (Fermi架构下)在同一个时钟周期里,要么FPU干活,要么ALU干活,不能同时开工,之后的新架构(Volta/Turnig之后)就改变了这一状态,让二者分开。
- CUDA Core可以进行FMA(fused multiply-add),即加乘操作的融合$y=wx+b$,单指令就可以完成,这些CUDA Core在显卡里并行计算,如果CUDA Core越多,算力也会越强。
1.1.2 Tensor Core
在上面的图中,Volta架构的SM引入了Tensor Core。
CUDA Core在一个时钟周期里,只能接收三个数字$w$、$x$、$b$,做一次FMA(乘加运算),如果要计算4×4的矩阵乘法,就需要调用大量CUDA Core,通过循环去算行列的点积。
Tensor Core专门处理矩阵计算,并且支持混合精度,就是输入矩阵的精度是FP16,但是最终输出结果可以是FP16或者FP32,计算量减少但是保证了输出的精度。
Tensor Core在一个时钟周期内能执行4×4×4的GEMM(general matrix multiply,矩阵乘加)运算,相当于同时进行64个FMA计算。
可以看出,相比CUDA Core,Tensor Core在计算量、精度、指令数上都有很大的优化。
2 TensorCore做计算的过程
这一部分的内容主要是探讨基于Tensor Core的mma指令底层计算机制,并梳理了数据在Global Memory、Shared Memory与寄存器如何实现swizzle(内存交错)、物理排布优化。
在阅读本部分之前,读者需要了解的CUDA知识有:
- 访问全局内存时,同一warp中的相邻线程访问连续的地址时,或者说一个warp对全局内存的一次访问使用了最少的数据传输时,就称为合并访存,能最大化全局内存的吞吐。
- 访问全局内存时,尽可能使用最宽的数据类型(float4)进行访问,可以最大化访存指令的利用率。下面是分别用float和float4做内存拷贝时的性能(rtx3050)
- [float] Time: 4.36634 ms, Bandwidth: 183.22 GB/s
- [float4]Time: 4.27924 ms, Bandwidth: 186.949 GB/s
- 可见float4还是比float快一点的,查看其ptx代码,
ld.global.f32 %f1, [%rd5];和`ld.global.v4.u32



