【CUDA进阶】Cutlass软件抽象分层与源码浅析 - bilibili
1 Hierarchical分级的概念
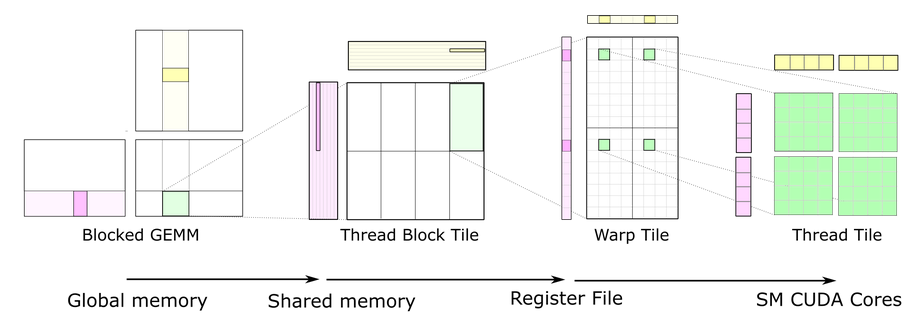
cutlass里分级的概念在数据搬运和线程层次结构
- 数据搬运:GMEM、SMEM、Register
- cutlass能解决算子合并的问题,做算子合并的关键就是在数据搬运回GMEM之前,所有的算子都计算完,而不是一个算子计算完成后写回GMEM再计算下一个GMEM
- 线程层次结构:block、warp、thread
- 在整个GEMM的流程中,数据的移动轨迹是这样的:
- Global memory -> Register -> Shared Memory -> Register -> Compute -> Shared Memory -> Register -> Gloable memory
- 这里讨论几个数据移动的问题:
- 计算前,数据为什么要进SMEM:同一个CTA的不同warp在处理C中相同行/列时,会需要相同的数据,如果都在GMEM里读取,就会很慢,于是让CTA将所有warp需要的数据一次性读到SMEM中,每个warp去读自己需要的部分
- 数据从GMEM读取到SMEM时,thread的分工里读和算是否统一:CTA需要的A、B数据的搬运量平分到thread,但是对于每个thread而言,搬运中要负责的部分和mma要负责的部分是不一样的
- 当SMEM一次装不下CTA需要的全部A、B时怎么办:沿着K方向进行多次计算,再累加到C的对应位置,这种方法叫IterationK,当SMEM的数据没办法一次放到Register时也用同样的方法。
- 但是IterationK在K比较大而MN比较小的时候,每个thread都要进行K次计算,可以对每个C块的计算拆分到不同的thread里执行,”第一个思路是把原本的一个warp,在K方向上拆成若干个warp,也就是说这若干个warp负责C中的同一部分。这么做可以解决问题,但需要额外增加一个环节——把这个几个warp得到的结果做累加。CUTLASS把这个环节放在了Kernel的Epilogue的部分。这就是SlicedK“。
- 还有一个叫SplitK的操作,“SplitK的思路与SlicedK类似,只不过方法是把原本的一个CTA,在K方向上拆成若干个CTA。那么这若干个CTA之间也需要做累加。CUTLASS选择额外launch一个新的CUDA Kernel来完成CTA的结果之间的Reduction。”
- 最后计算完毕后数据的读写过程,为什么不直接把结果从Register写到GMEM中:
- Register里的数据排布是不连续的,需要在SMEM里重排
- 如果不是一个线程负责一个矩阵块,且用到了SlicedK,线程之间就需要计算累加和,就要用到SMEM进行数据交换
08_turing_tensorop_gemm:
- host memory和device memory的维护
- 用CUTLASS 自带的Reference GEMM比较,确保Tensor Core的计算结果是正确的
std::vector<StorageUnit> host_; device_memory::allocation<StorageUnit> device_;
2 编译期的thread_size
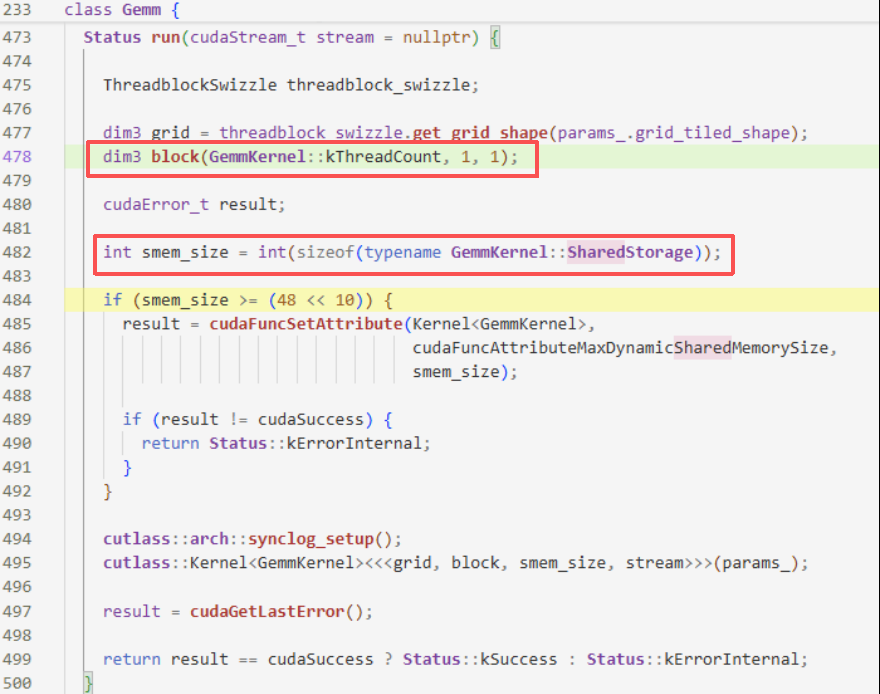
想知道thread_size,就是看kThreadCount的大小,那么就要看GemmKernel的定义
- 链接到
Gemmkernel,发现他实际上是DefaultGemm<>::GemmKernel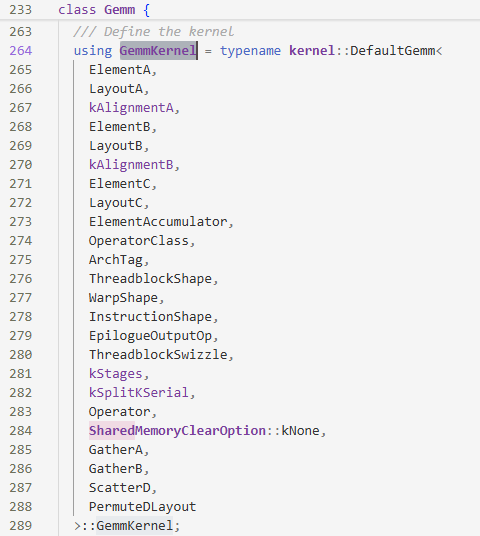
DefaultGemm下的GemmKernel的定义如下,发现和kernel::Gemm有关联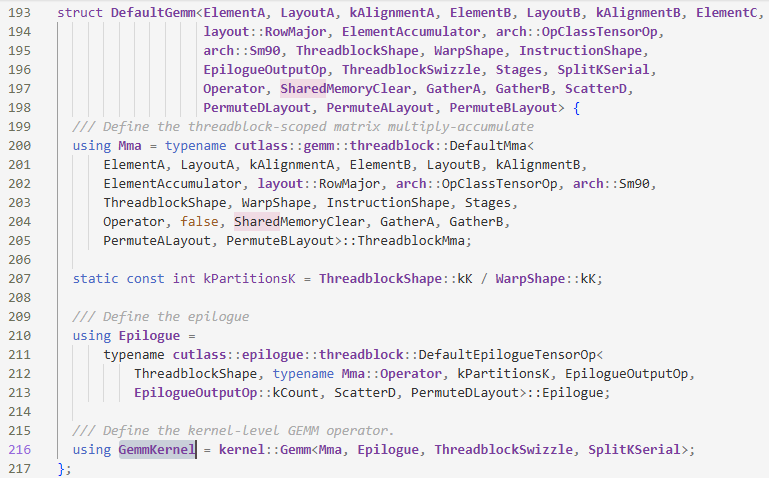
- 进入
kernel::Gemm,发现我们kThreadCount与WarpCount::kCount的大小有关,但是WarpCount也只是Mma下的一个类型别名,而Mma和ThreadblockMma有关,但是进入到ThreadblockMma也找不到和kCount有关的信息了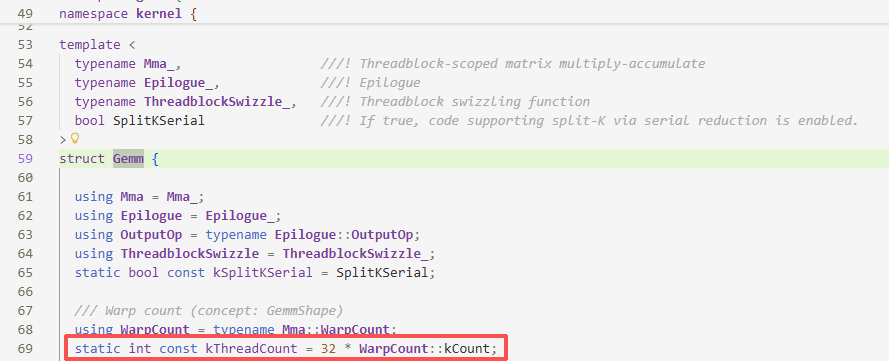
- 于是直接搜索
kCount存在哪些文件中,然后就找到和WarpCount有关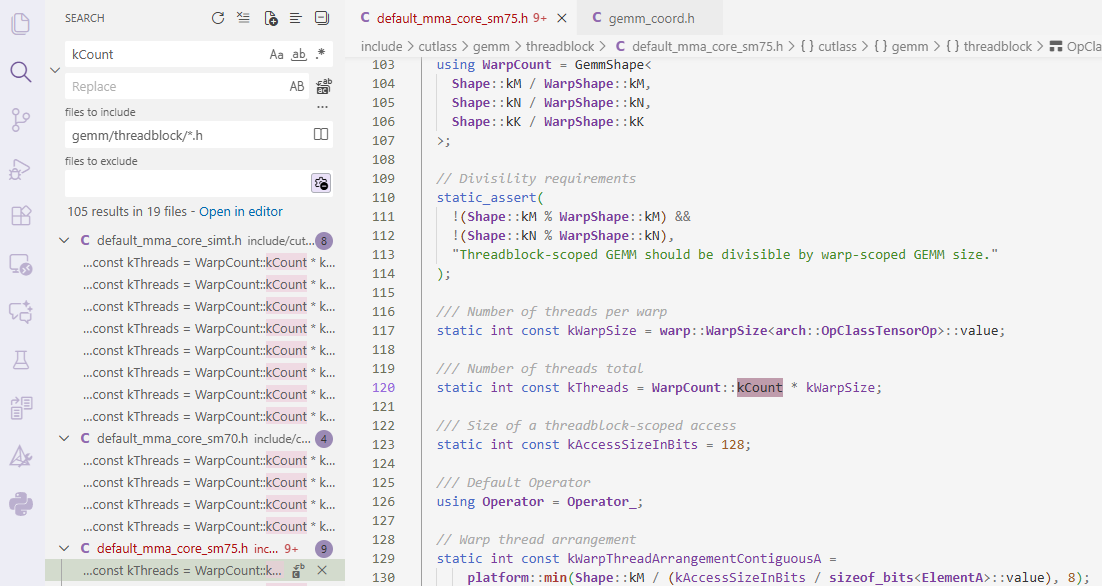
- 猜测
GemmShape里的Shape指的是数据大小,WarpShape是warp的大小,这里求的是warp在M、N、K方向上的个数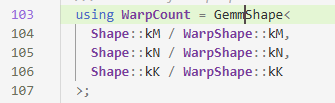
- 然后再进到
GemmShape里,发现kCount其实是warp个数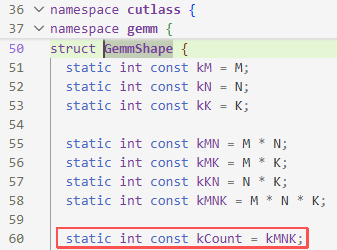
根据static int const kThreadCount = 32 * WarpCount::kCount;,线程数就等于32*warp个数,这也很符合常理。
3 kernel内部执行情况

cutlass:Kernel是Launch的地方,而Kernel内部的重点是Operator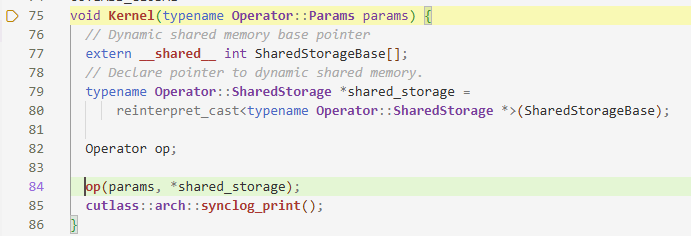
以上都是在device层实现,它对外提供API的接口类,对内完成对Kernel的调用。
下面的kernel层做gemm和epilogue的解耦,让计算逻辑和内存访问逻辑分离,并提供SpliteK模式下threadblock之间的数据和同步需求
3.1 mma之前
get_tile_offset:计算逻辑的tile分块坐标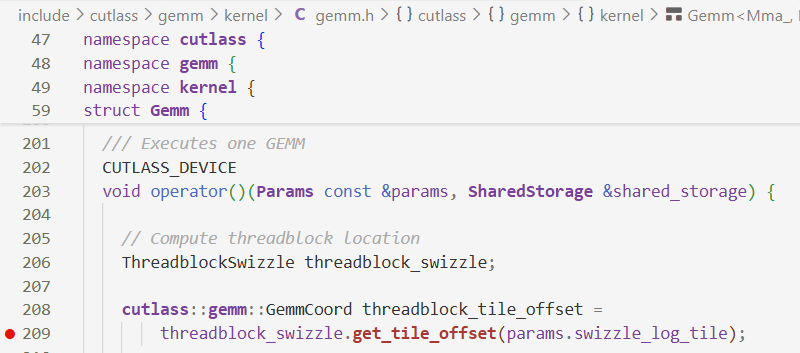
get_tile_offset的定义
将上面计算得到的逻辑块坐标转换为物理位置的坐标(全局内存坐标)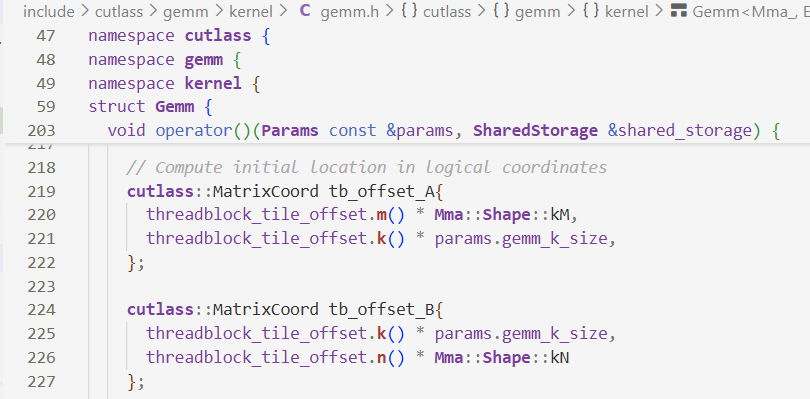
计算沿着k方向循环多少次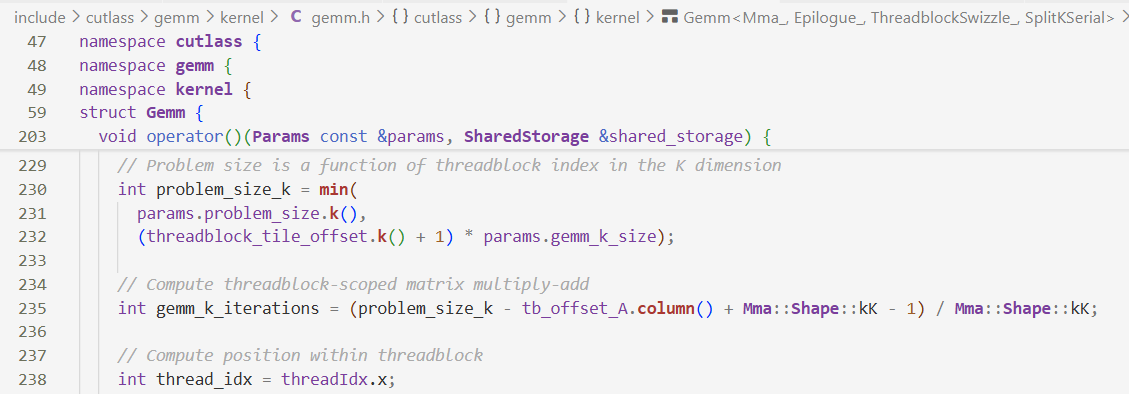
使用Iterator封装GMEM读取数据这一过程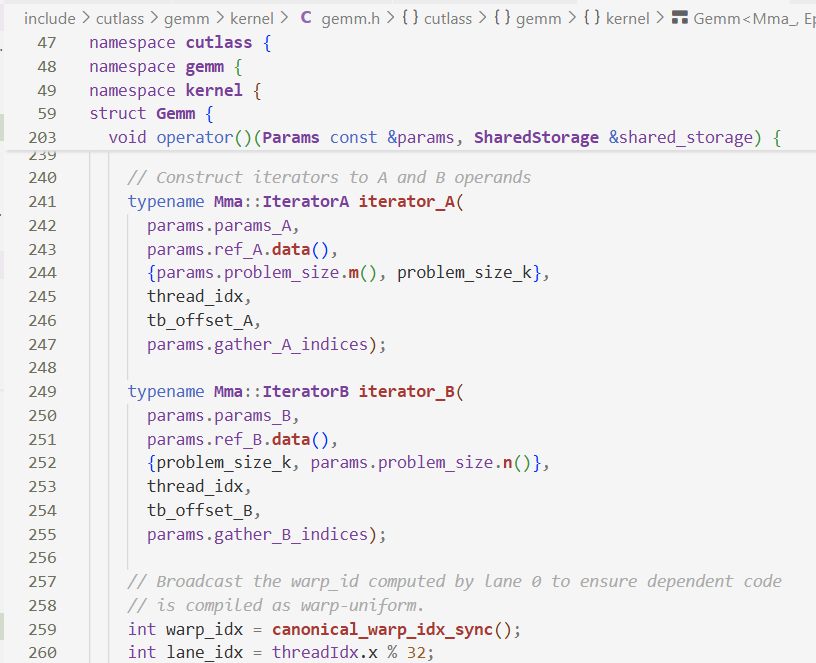
- TensrRef:对GMEM或SMEM的指针的封装
创建mma、累加器accumulators,根据k维度迭代次数做计算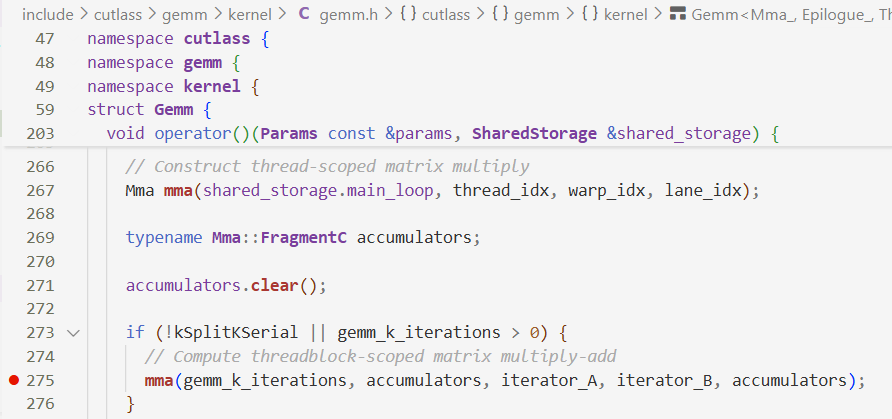
- Fragment:将Register资源抽象成一个定长一维数组
关于mma部分,在threadblock执行,执行完毕后再执行下面的epilogue
3.2 mma之后
Epilogue:完成$D=\alpha AB+\beta C$
这一段大概是根据swizzle重新定位数据,因为不考虑spliteK所以不看if(kSplitKSerial…)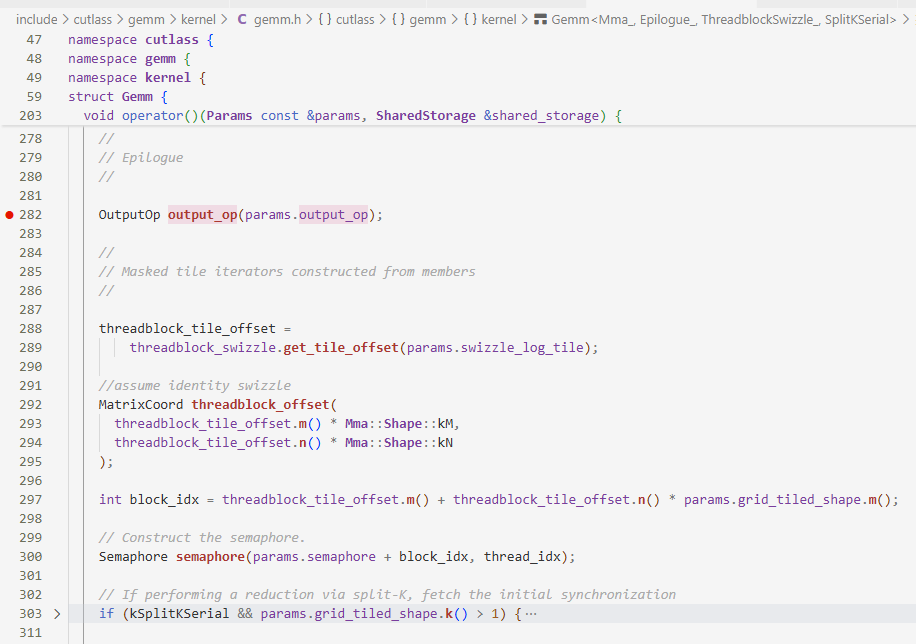
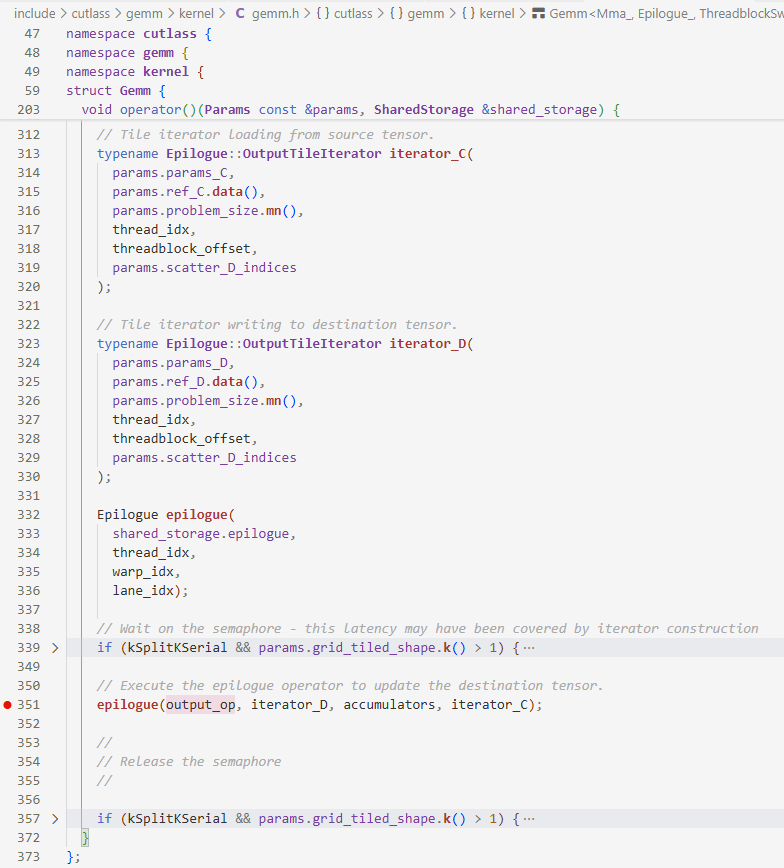
- 构建了
C和D的iterator epilogue实现$D=\alpha AB+\beta C$
epilogue首先判断是否需要source_iterator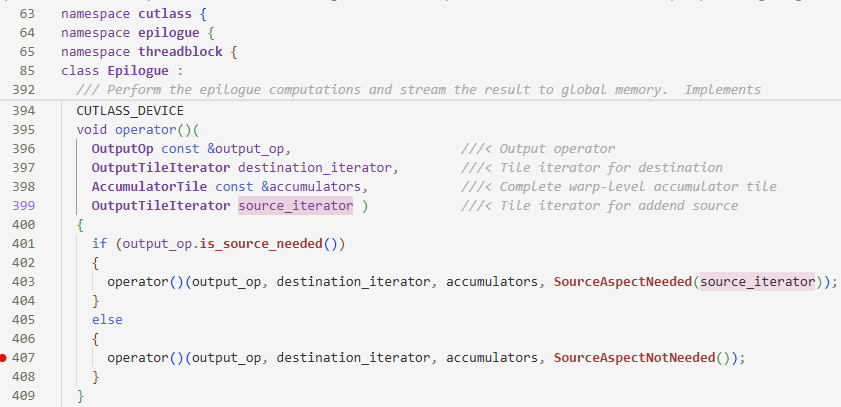
判断依据在: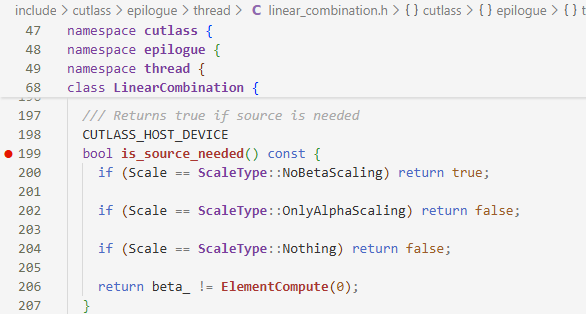
- 如果只有$\alpha$,即$\beta=0$,就不需要$\beta C$这一项了,所以也不需要$C$了,返回
false,进入else的一环不需要souce_iterator也就是$C$
然后直接看含有output_op的部分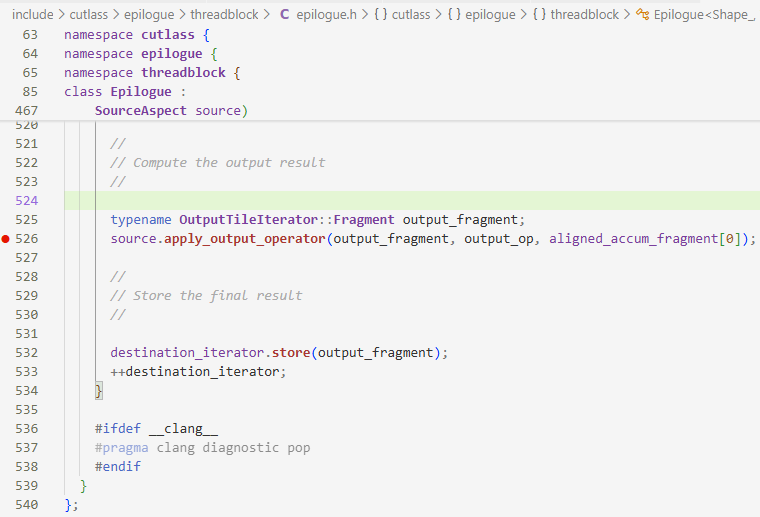
aligned_accum_fragment[0]是$AB$的结果output_fragment是存放结果的寄存器,最后结果返回GMEM- 关于
aligned_accum_fragment[0],数据是从SMEM→Register,shared_load_iterator_有点凭空产生了,猜测它应该和accumulator有关系(即Register→SMEM这一环,第四步),但是没找到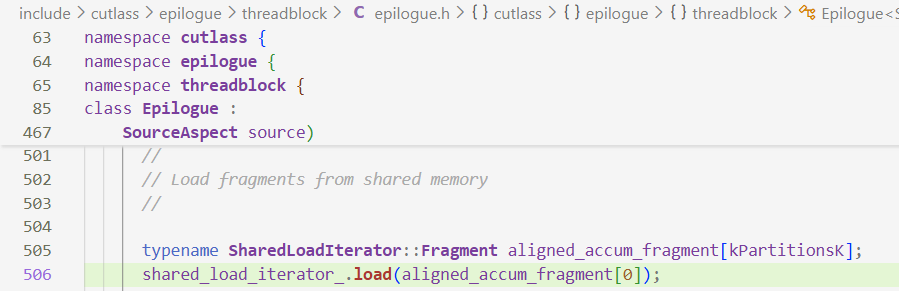
- 附上
accumulator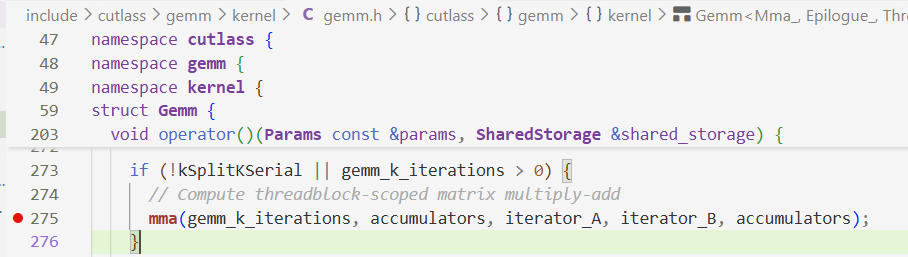
- 附上
看apply_output_operator这一环做了什么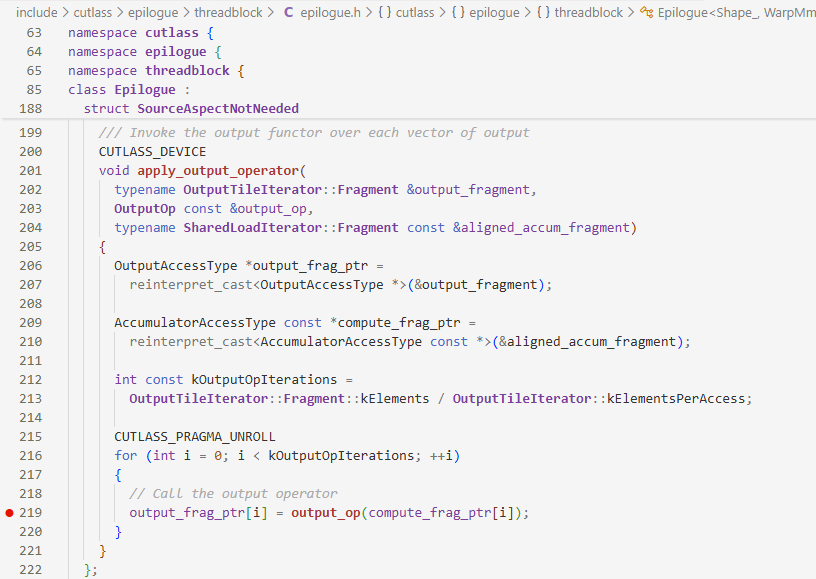
关键的部分在output_op()
转跳到这里,发现output_op实际上是直接计算$D=\alpha AB$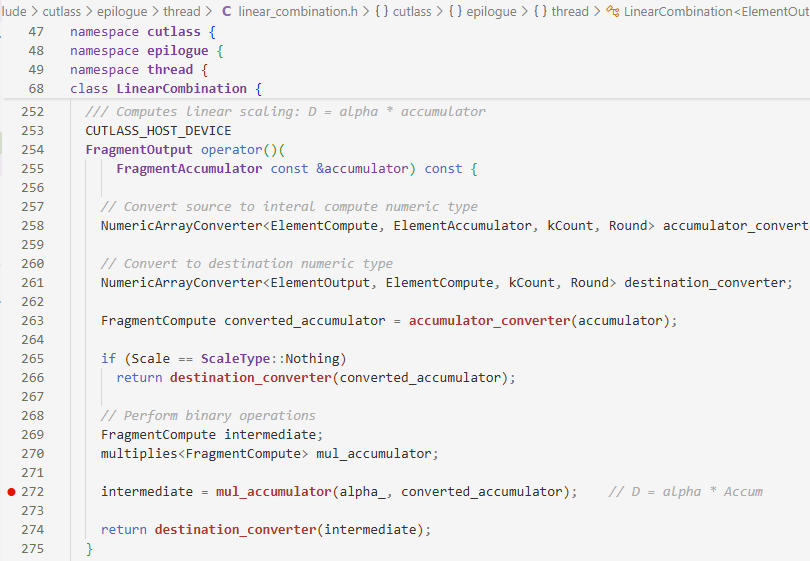
4 threadblock内部执行情况
上一节分析到mma做计算,这一节看mma的内部,mma跳转到prologue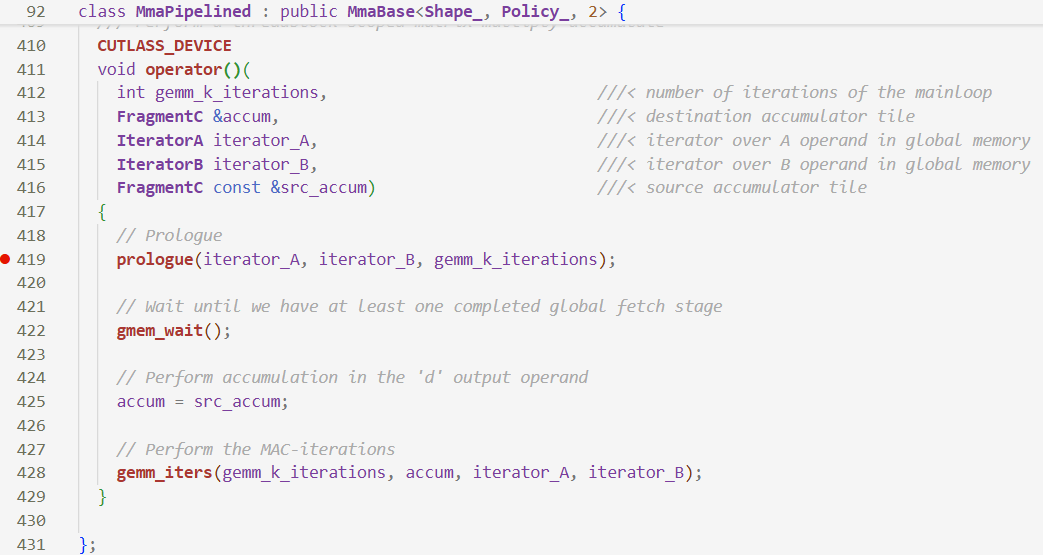
threadblock层的任务是对于主循环(mainloop)进行流水编排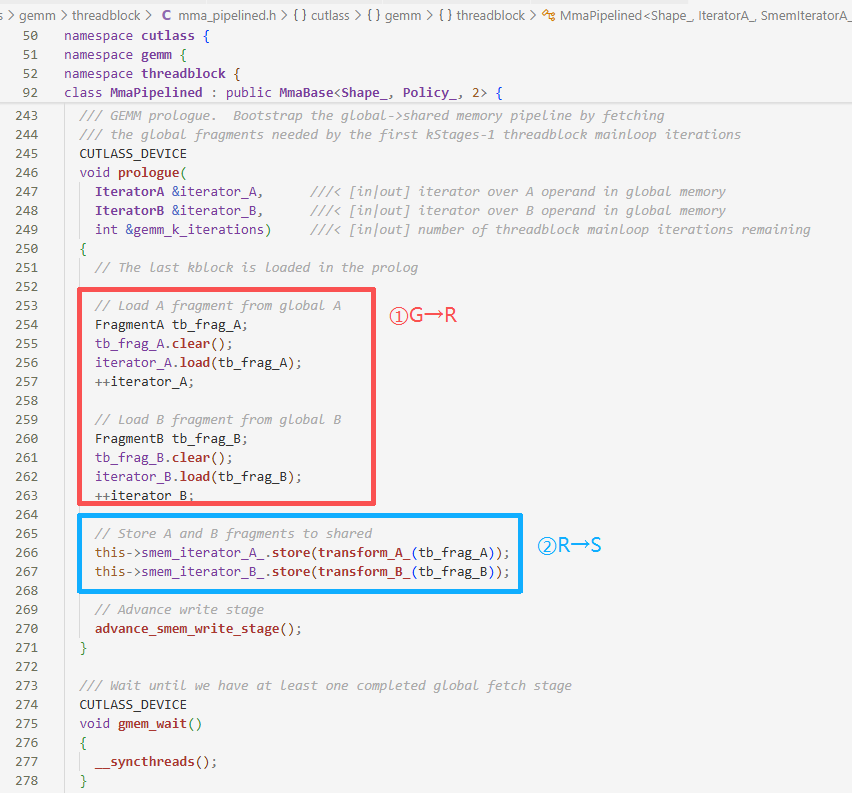
数据搬运过程:
- 第一步:
iterator_A.load(tb_frag_A)GMEM→Register - 第二步:
this->smem_iterator_A_.store(transform_A_(tb_frag_A));Register→SMEMtransform_A_实质是类型转换advance_smem_write_stage();内部:
smem_write_stage_idx ^= 1;管理SMEM双缓冲,计算和加载数据并行
这里是预启动的过程,只搬运数据不计算,经过中间的gemm_wait()同步操作后,下面的gemm_iter在预启动得到第一批数据后,进行循环计算
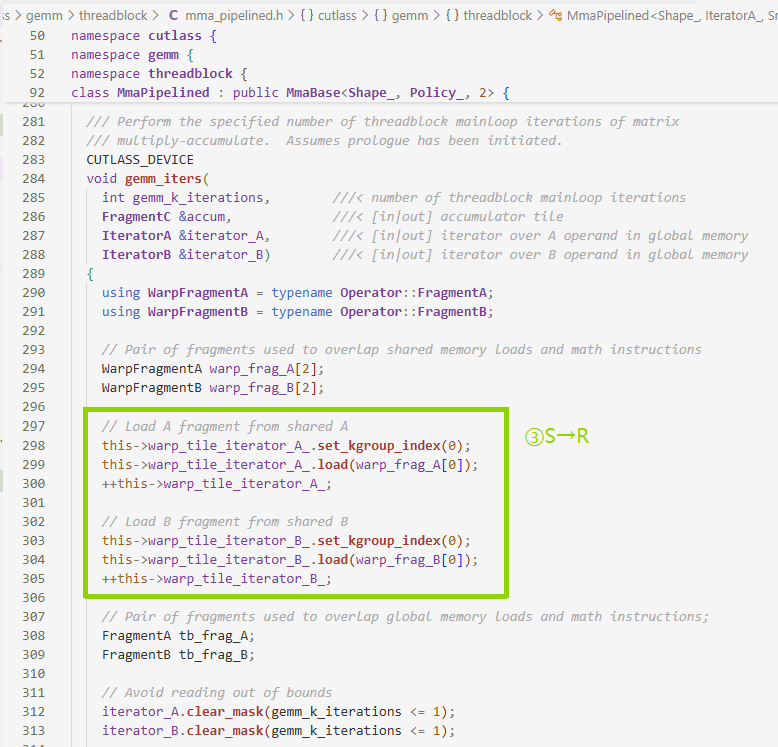
- 第三步:之前用的都是SMEM的iterator,现在变成了warp_tile的iterator,猜测后者是前者的一小部分,但数据仍在SMEM里,并且加载到Register
warp_frag_A和warp_frag_B用来做双缓冲,[2]使计算和加载数据交替
- 外层循环是沿着K的,内层循环是block内多个warp的循环
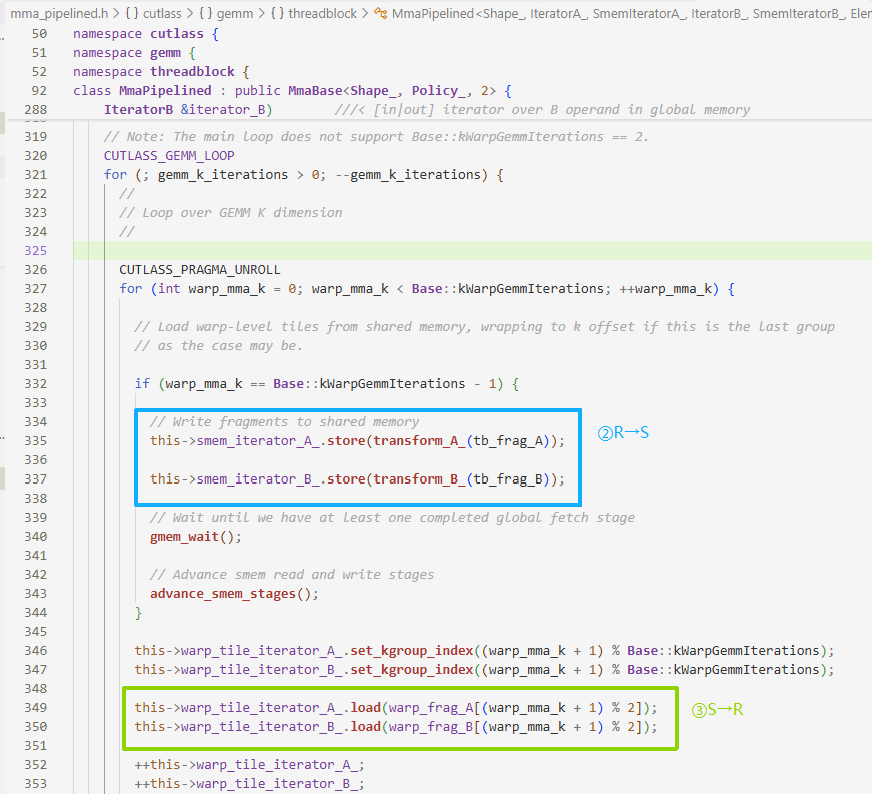
- 第二步:在内层循环最后一次迭代中,把之前在Register里
tb_frag_A的数据,写到SMEM - 第三步:数据SMEM→Register,这里同样使用双缓冲,一边计算
[0]一边加载[1],循环外部的第三步是处理预启动的数据
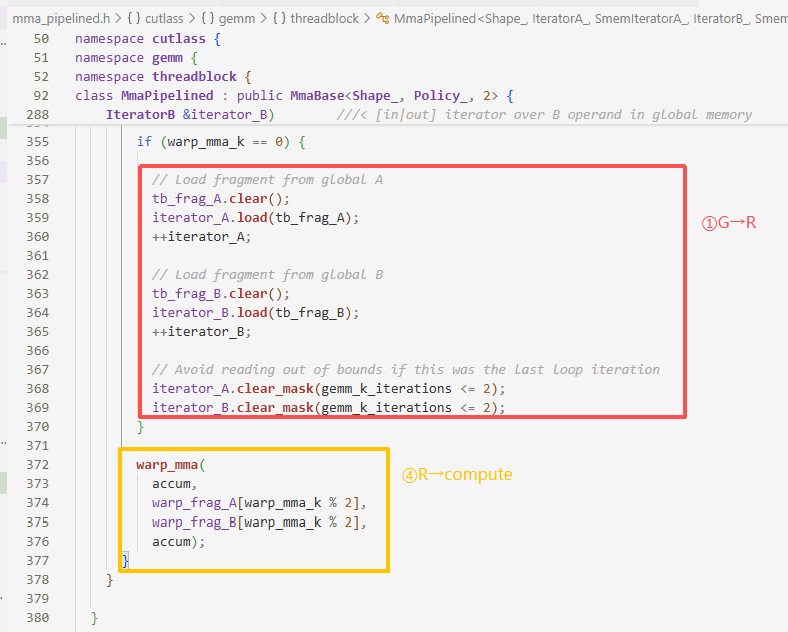
- 第一步:当处理SMEM的第一块warp时,数据从GMEM加载到Register里
tb_frag_A - 第四步:做双缓冲数据交替的计算Register→compute
5 warp内部执行情况
上一节最后一步是mma,mma计算是在warp内部执行的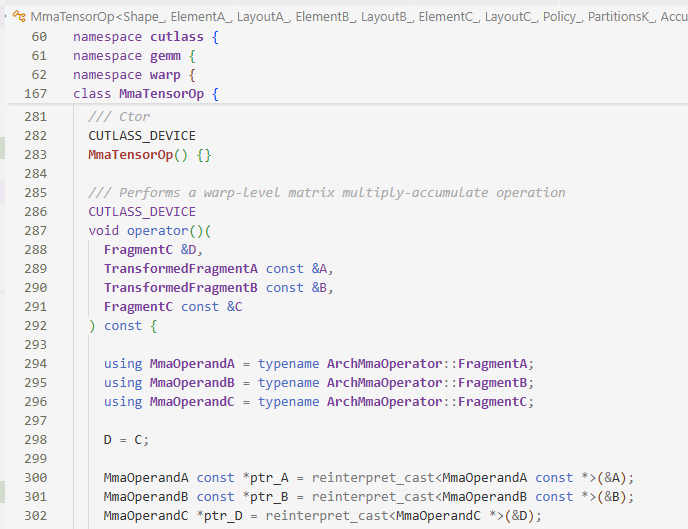
这里先确定kVerticalVisit行/列优先(默认行优先,即寄存器B在内层循环中被反复重用,A不断切换),再确定AccumulatorsInRowMajor决定D在寄存器里行/列优先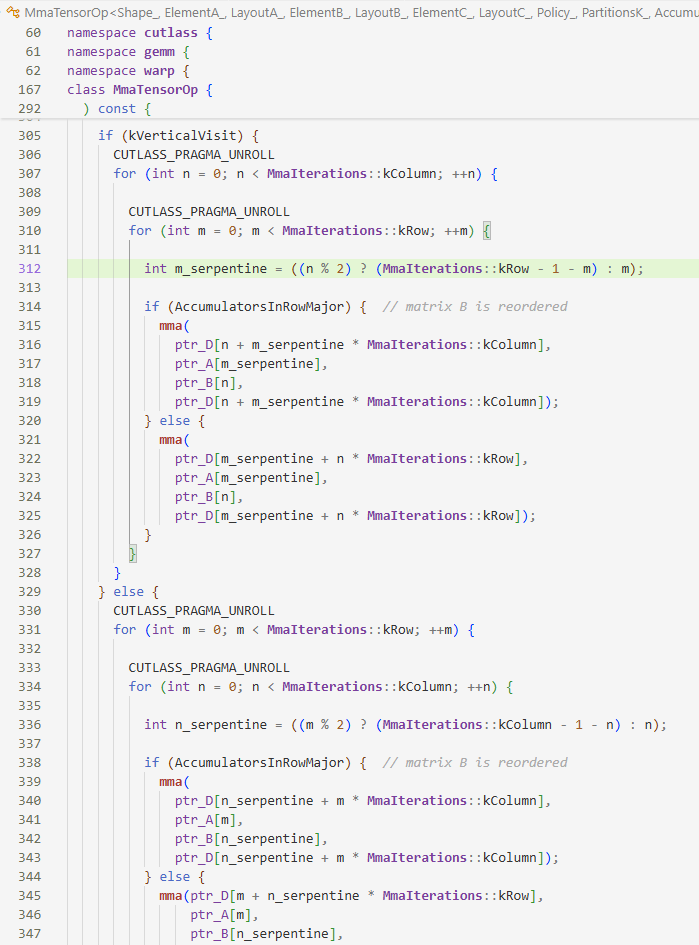
最后warp内部计算(上面的)mma回归到了我们熟悉的内联汇编,使用tensor core执行mma。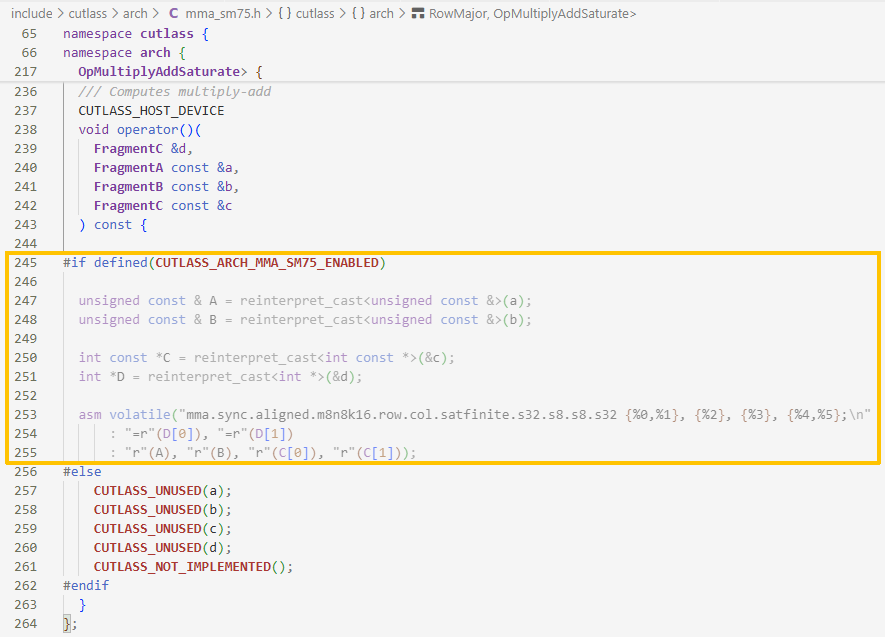
这里也表现了tensor core和cuda core计算分层的区别:
- tensor core:thread block→warp→
arch(上图所示命名空间),而且这里warp内部的8个块大小必须是16×16(In CUDA 9.0, the fundamental WMMA size is 16-by-16-by-16.)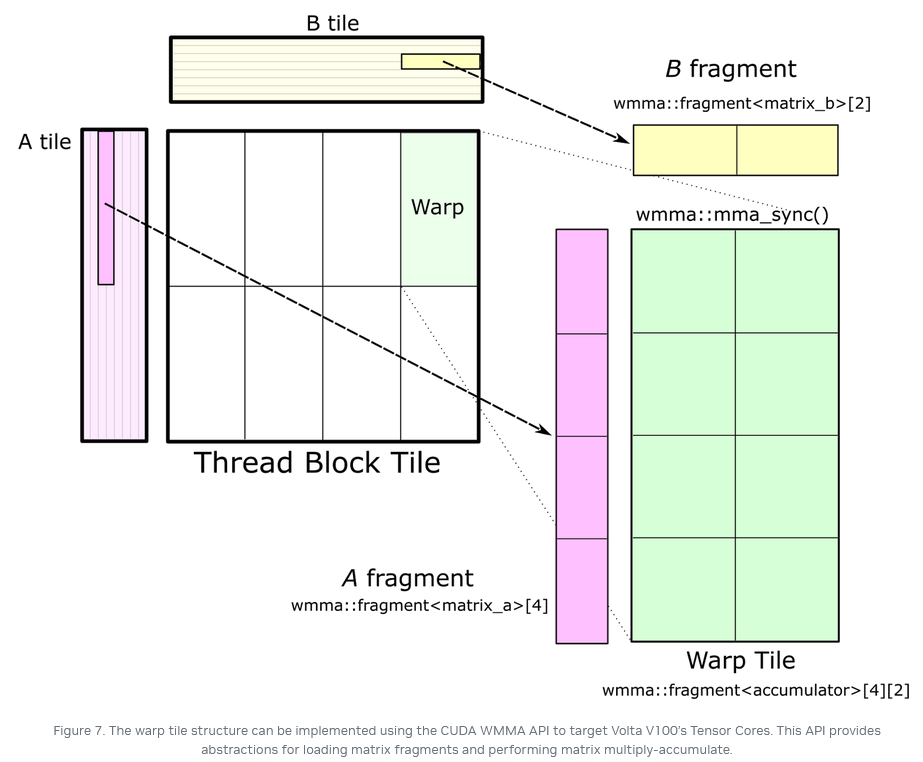
- cuda core:thread block→warp→thread
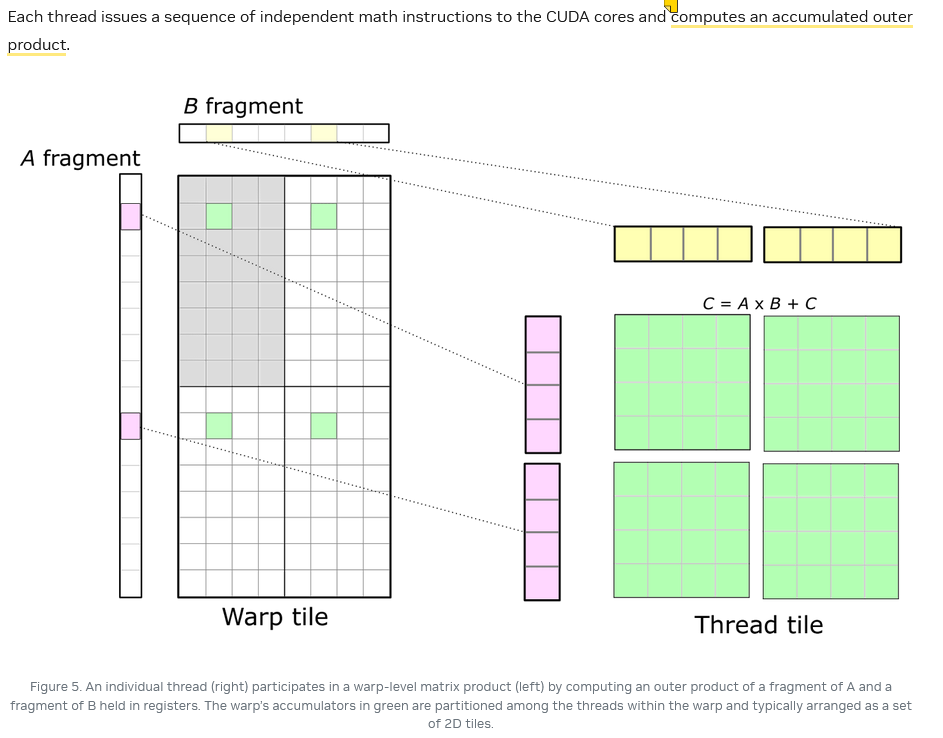
两种运算都是外积
5.1 Iterator
Iterator的定义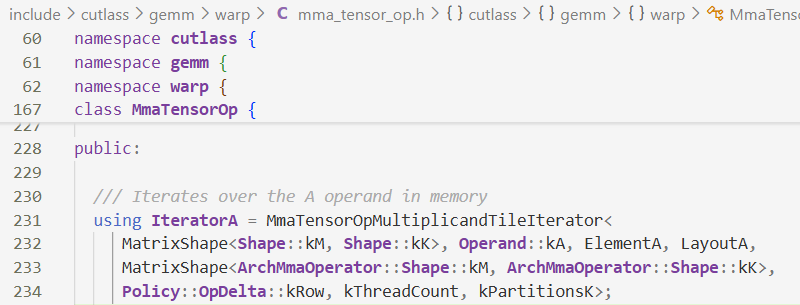
在warp层定义,在threadblock层里使用,为了确保读写一致
6 软件抽象
“CUTLASS的大部分类甚至说大部分代码,本质上来说都是在做这四件事的其中之一:模板推导,数据访问,数据计算,流水编排”
6.1模板推导
在上一节也有看到DefaultGemm类,”这段代码把Gemm类的模板参数几乎原封不动地给到了DefaultGemm这个类,最后得到了DefaultGemm类里面的GemmKernel这个类”,这里输入的是一系列模板参数,输出的是类(如这里的GemmKernel)
作用:
- 决定成员变量类型,不同的成员变量组合成一个”新的”Gemm类。”重要的类会有为自己服务的模板推导的类”这里
DefaultGemm就是一个”新的”类,并为他的子类GemmKernel选择Mma类等等重要子类,再传递给类别名GemmKernel。 - 将确定的信息通过类模板传参计算,静态参数根据模板参数计算出来(在编译时执行,在运行时该参数就成了立即数)
// 比如DefaultGemm定义中kPartitionsK就是静态参数 static const int kPartitionsK = ThreadblockShape::kK / WarpShape::kK;6.2数据移动
- 在CUDA层面,GMEM和SMEM的指针都是在Kernel launch的时候传进来的,之后就可以用指针来访问。但是GMEM和SMEM中的数据在编程管理中比较复杂,需要多个thread配合读取一块数据,要知道数据分布、每个thread负责哪些数据。
- 本地申请的变量默认存进Register,Register存不下会溢出到local memory,在CUDA13.0允许溢出到SMEM。”在CUTLASS中,Register中的数据被抽象成Fragment类,本质上就是一个固定长度的本地数组,所以也可以用指针访问。”
对于以上的数据访问,cutlass将其统一抽象为Iterator的概念,每种类型的数据移动,会有专属的Iterator类。
- 比如MmaSimtTileIterator就是一个在负责将数据从SMEM读到Register的类
- 又比如说,RegularTileIterator是一个负责将数据从GMEM读进Register的类
Iterator类会接收以下参数:Shape:CTA/Wrap要读取的Memory的各个维度的大小Layout:”描述N维的数据如何放到一维的Memory上,更本质地来说,是N维坐标到一维数组上的offset的映射”TensorMap:描述thread的分工(这里我并没有在源码中找到定义
Iterator提供的API
- 加载数据到Register(就是代码里的
frag):void load(Fragment &frag) { load_with_pointer_offset(frag, 0); } - 指针移动
PredicatedTileIterator &operator++() { ++iterator_; return *this; }
6.3 数据计算
正如第五节里提到的,计算最底层就是内联汇编,数据传输发生在threadblock层,从SMEM传到Register里,循环在warp层
6.4 流水编排
一个warp发出一条load global memory的指令之后,有两种可能:
- 第一种是warp继续launch之后的指令,直到某条指令和该条load指令有数据依赖,才被阻塞;
- 第二种可能就是warp被换下来,和其他warp交替并行计算和加载数据。
一般来说会先走第一种,直到阻塞再走第二种
在multi-stage pipeline出现之前,面临的问题:
①GEMM为保存数据(ABC),需要申请大量Register,为了数据复用也需要申请大量SMEM,那么每个SM上的资源就不够thread block分配,导致GEMM实现过程中每个SM能容纳的warp和thread block就少,导致Occupancy很低
②同步问题,因为warp和thread block少,也不能用切换线程来掩盖同步问题
解决方法:
①分块少,每个块的资源多,只要让每个块的计算不要停下来就行(尽管Occupancy低)
②pipeline就是(通过掩盖延迟)来解决数据搬运问题的:在计算当前块时,去搬下一块的数据,把瓶颈从内存转移到计算上
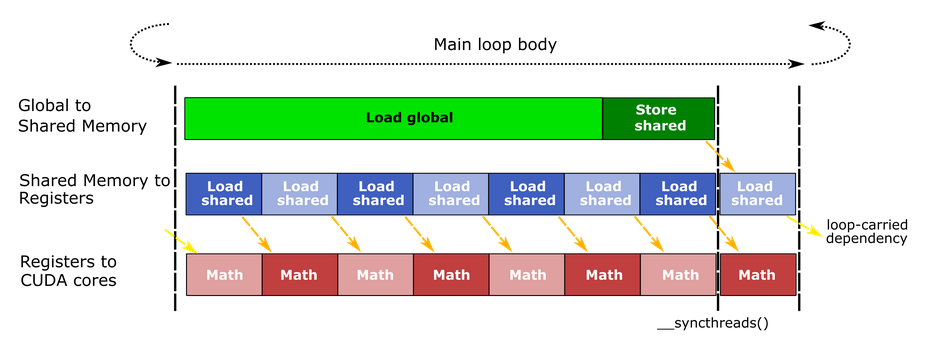
单缓冲:GMEM→SMEM__syncthreads(),等待写完→Register__syncthreads(),等待写完
双缓冲:如上图,在全局内存加载数据时,即SMEM在被写入,同时之前加载到SMEM的数据被读取到Register做计算,只有在写入SMEM时的一次__syncthreads(),虽然对SMEM和Register的容量需求更大了,但用来等待同步的时间少了(解决同步带来的延迟,让tensor core一直执行)
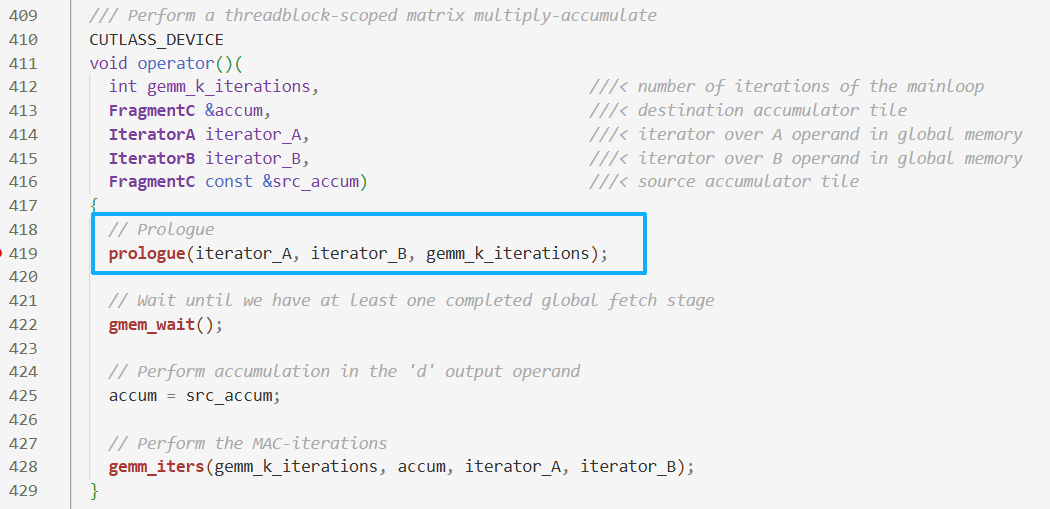
- 在第四节也分析了
prologue,它是只搬运数据不计算,在数据从Register写入SMEM时做了一次双缓冲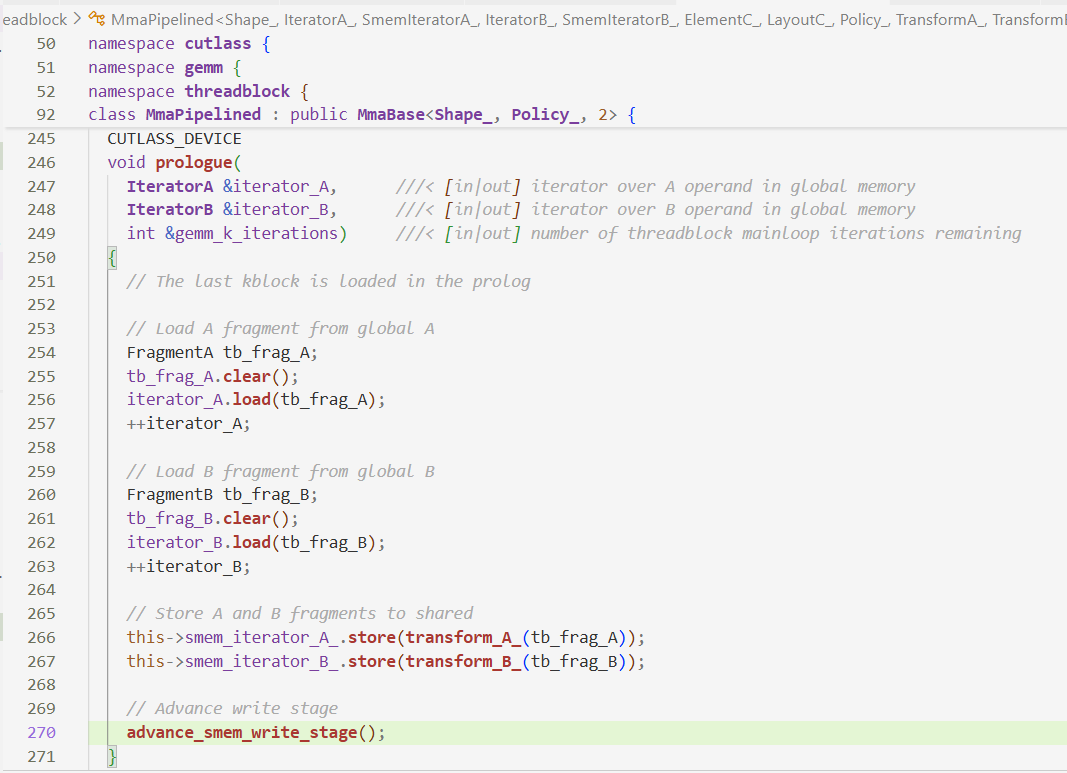
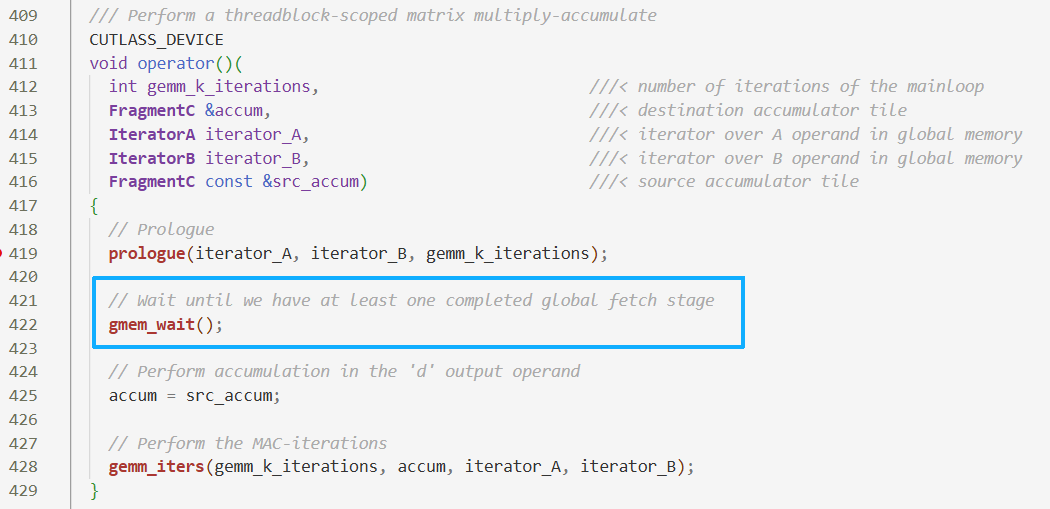
- 这里
gmem_wait()实质上是__syncthreads()
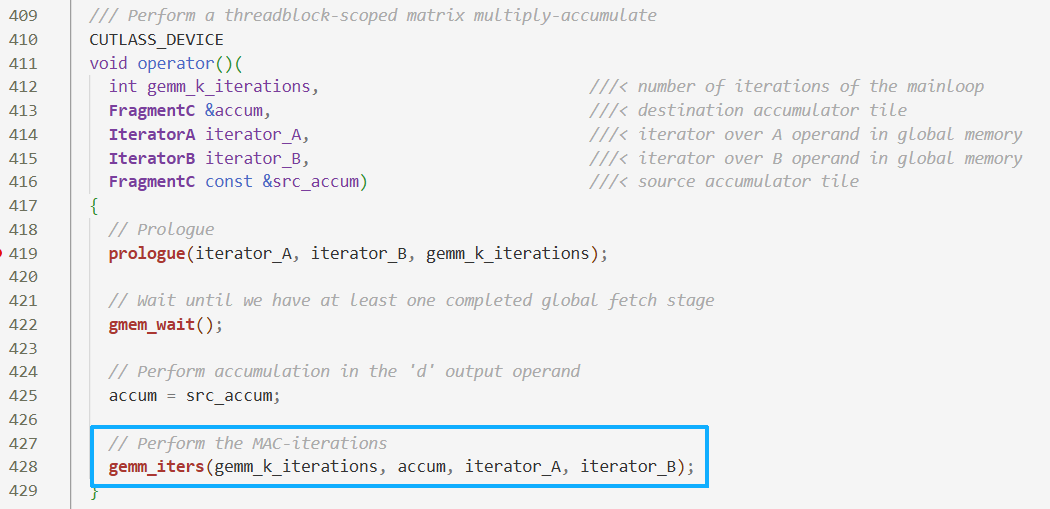
- 内部也有在数据从Register写入SMEM时的同步与双缓冲




