我的学习参考:FlashAttention手动实践过程 - up: 比飞鸟贵重的多_HKL - bilibili
我的实现:FlashAttention - Wabbybabb0
⭐正如up主所言,对于一个新的知识和思想,应该抓住核心逻辑然后使其他因素尽可能简化,于是在github上找其他flash-attention的版本(没有那么庞大复杂的代码体系),于是找到了flash-attention-minimal仓库。
❓存在一个问题:在main.cpp中,forward被包装为python模块中的函数,在bench.py通过load载入,因为是通过python调用的,所以使用cuda传统debug的方法比较麻烦。
🚩解决方法:找一个能无缝衔接所有cuda算子的库libtorch实现不依赖python,直接在c++中调试cuda算子,思路是从flash.cu中forward使用torch得到的。libtorch是Pytorch的c++接口,使得在python写的模型torch可以在C++中运行。
- Pytorch C++
- libtorch-demo测试
那么,我们就不需要用main.cpp里将forward封装为python模块中的函数,可以直接调用forward,直接用C++实现调试。
所以现在第一件事是配置环境!
1 Libtorch环境搭建
1.1 环境测试
🎈到Pytorch官网找到合适的配置,通过nvcc -V查看合适的libtorch对应的cuda版本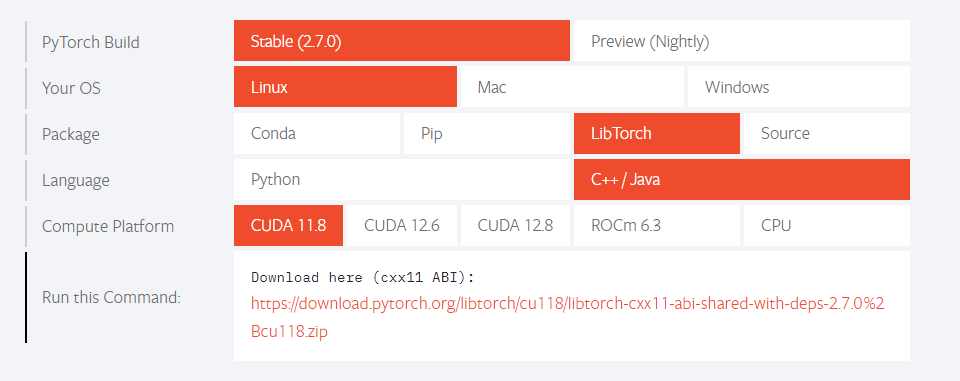
🎈下载完之后放到项目目录(比如/FlashAttention)下解压unzip libtorch-xxxxx
🎈根据官方提供的 libtorch-demo测试,进行环境测试
- 在当前目录下创建一个
example-app.cpp,内容如下
新增的两行用于测试c++是否能无缝衔接cuda(学到了up主的“尝试”思路,大胆的猜一些代码语法#include <torch/torch.h> #include <iostream> int main() { torch::Tensor tensor = torch::rand({2, 3}); std::cout << tensor << std::endl; # 下面是新增的两行 torch::Tensor tensor_cuda = torch::rand({2, 3}).to("cuda"); std::cout << tensor_cuda << std::endl; } - 在当前目录下创建一个cmake文件,内容如下
cmake_minimum_required(VERSION 3.18 FATAL_ERROR) project(example-app) find_package(Torch REQUIRED) set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${TORCH_CXX_FLAGS}") add_executable(example-app example-app.cpp) target_link_libraries(example-app "${TORCH_LIBRARIES}") set_property(TARGET example-app PROPERTY CXX_STANDARD 17) # 后面的内容是windows上使用的,可以删掉或注释掉 - 增加包的路径为
xxx/libtorch/share/cmake/Torch,cmake会在上面提供的路径找torchconfigcmake_minimum_required(VERSION 3.16.3 FATAL_ERROR) project(example-app) set(CMAKE_PREFIX_PATH "/home/wabby/Project/FlashAttention/libtorch/share/cmake/Torch;${CMAKE_PREFIX_PATH}") find_package(Torch REQUIRED) set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${TORCH_CXX_FLAGS}") add_executable(example-app example-app.cpp) target_link_libraries(example-app "${TORCH_LIBRARIES}") set_property(TARGET example-app PROPERTY CXX_STANDARD 17)
🎈编译build,得到可执行文件,然后运行,成功,说明Libtorch环境配置成功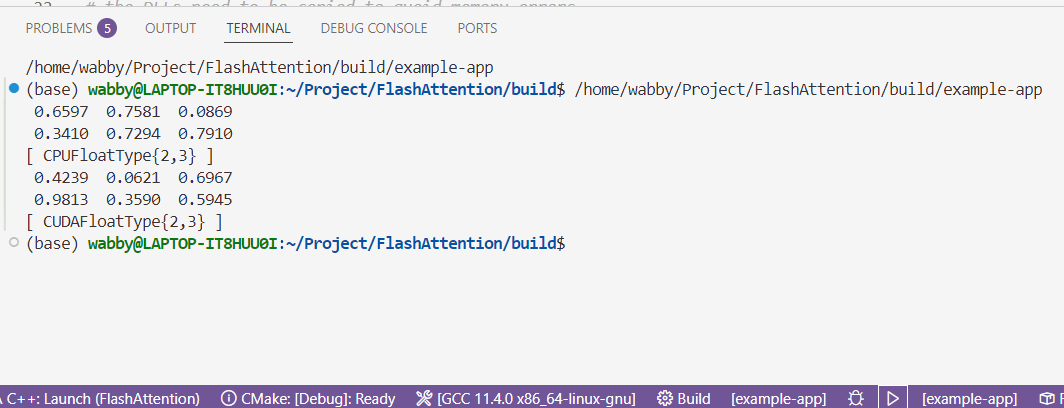
1.2 代码移植
🚩将bench.py移植为c++
- 变量一致
- 进行forward
- 语法:仿照demo
🎈在cmake文件添加下面的内容,编译build,打断点(断点不打在forward_kernel内部)运行,先确保两个可执行文件可以正常debugsadd_executable(flash-attention-main flash-attention-main.cpp flash.cu) target_link_libraries(flash-attention-main "${TORCH_LIBRARIES}") set_property(TARGET flash-attention-main PROPERTY CXX_STANDARD 17)
1.2.1 实现vscode调试cuda
弄了两天,仍未实现vscode调试cuda,但将过程中遇到的问题和部分解决方法放在这里,以便需要时取用。按照下面的方法弄完之后,再抱着尝试的心态重新打开就能调试了~(很神奇,应该是重启之后就好了嘿嘿~
笔者环境信息如下:
driver version on Windows: 566.07
cuda version on Windows10: 12.7
nvcc version on Windows10: V12.5.40
WSL2 Ubuntu version: 20.04.6 LTS
nvcc version on WSL2: V12.6.20
cuda-gdb version on WSL2: 13.2
🎈调试forward_kernel
- 在cmake文件添加下面的内容
# 调试用 if(CMAKE_BUILD_TYPE STREQUAL "Debug") target_compile_options(flash-attention-main PRIVATE $<$<COMPILE_LANGUAGE::CUDA>:-G>) endif() - 配置
launch.json
vscode中怎么调试cuda文件? - 知乎(笔者未成功)
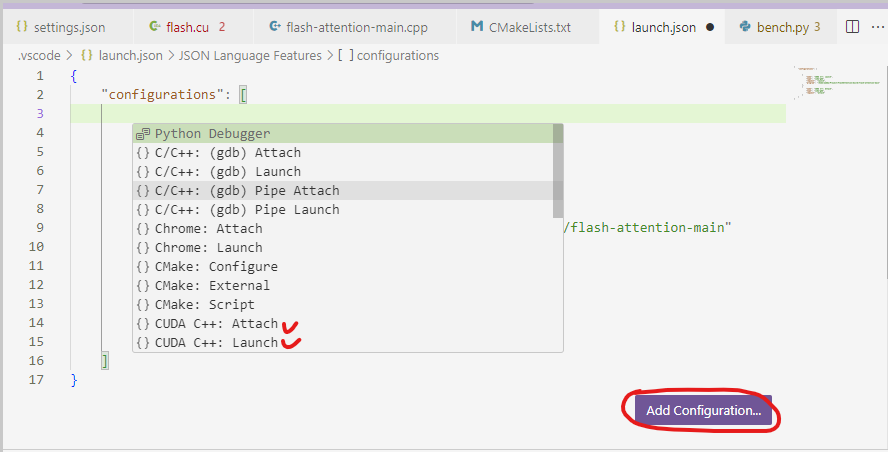
要在Launch的program添加可执行文件的路径{ "configurations": [ { "name": "CUDA C++: Launch", "type": "cuda-gdb", "request": "launch", "program": "/home/wabby/Project/FlashAttention/build/flash-attention-main" }, { "name": "CUDA C++: Attach", "type": "cuda-gdb", "request": "attach" } ] }
❓F5运行时遇到如下问题Error: get_elf_image(0): Failed to read the ELF image handle 93825002597824 relocated 1, error=CUDBG_ERROR_INVALID_ARGS, error message=
🚩解决方法:Cuda-gdb report Error under WSL2、Cuda-gdb report error using vscode for debugging under wsl2
- 先确保windows装了cudatoolkit,最好是12.2及以上的(官方推荐)
- 打开注册表
\HKEY_LOCAL_MACHINE\SOFTWARE\NVIDIA Corporation\GPUDebugger是否有一个叫EnableInterfaceDWORD类型的常量,且值为1,如下图所示,如果没有,可能是cudatoolkit没装好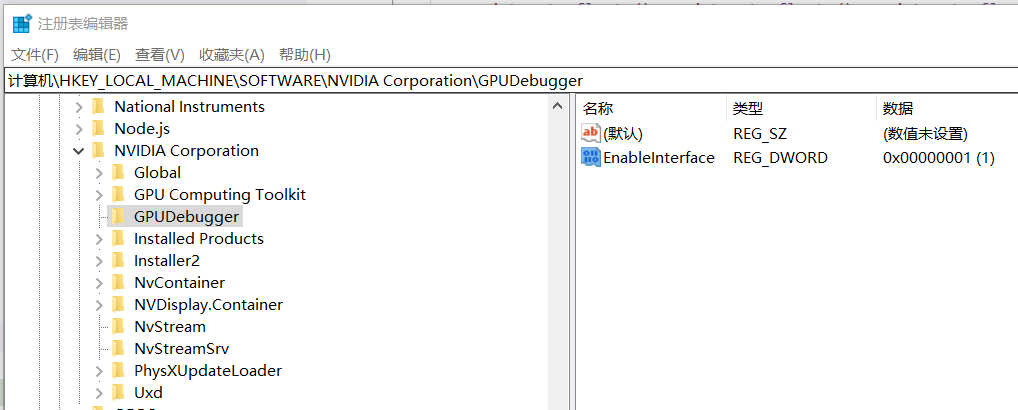
- 升级wsl,在cmd里输入
wsl --update,然后wsl --version可以看到升级后的版本,如下图所示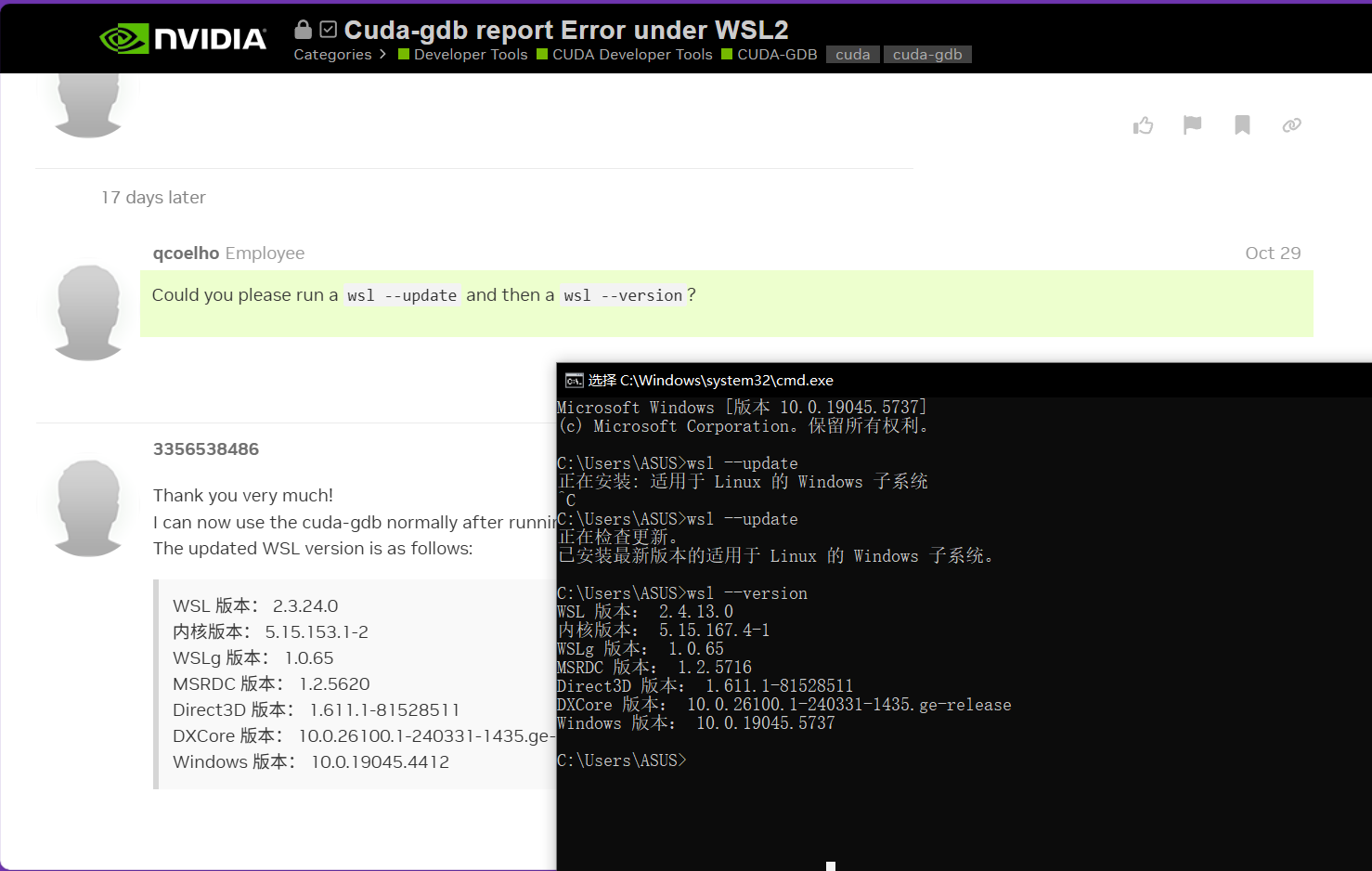
- 然后回到vscode,F5调试不再报错
Error: get_elf_image(0): Failed to read the ELF image handle 93825002597824 relocated 1, error=CUDBG_ERROR_INVALID_ARGS, error message=,但是仍无法进入cuda断点,同时有一个新的warning
❓【已解决】`warning: Cuda API error detected: cudaLaunchKernel returned(0x1)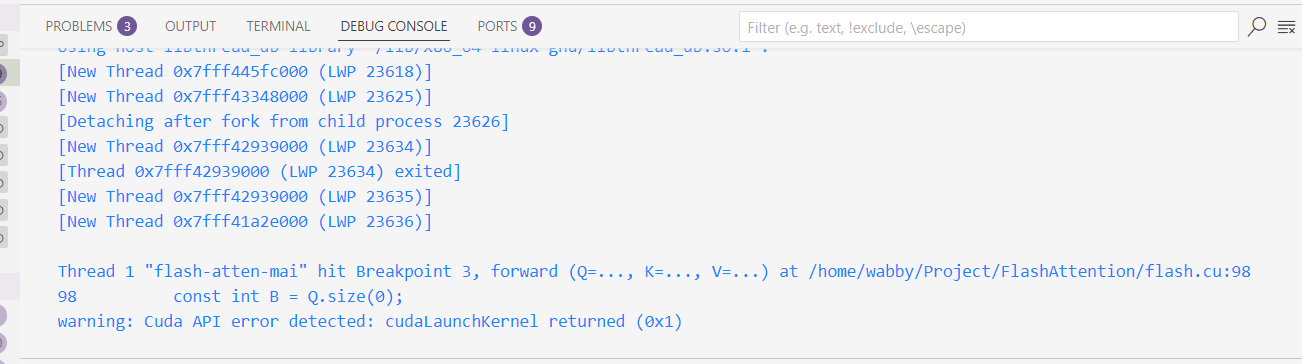
🚩【或许有用的方法】 - cuda-gdb giving error “warning: Cuda API error detected: cudaLaunchKernel returned (0x7)”、cuda-gdb给出错误“警告:检测到Cuda API错误:返回cudaLaunchKernel (0x7)”-腾讯云开发者社区-腾讯云,这两篇意思一样,前者是stack overflow原帖,后者是中文
- 在wsl输入
cuda-gdb进入(需要回车一下),再输入info cuda devices。- 笔者和stack overflow的一个评论的情况相同,显示
No Cuda devices,但是nvcc -V、编译、运行都是正常的
- 笔者和stack overflow的一个评论的情况相同,显示
- cuda - cuda-gdb 看不到可用设备_Stack Overflow中文网,有让运行
lsof /dev/nvidia*查看设备的,但是我的输出是空 - ubuntu 12.04 - CUDA-GDB: No CUDA devices - Stack Overflow,有个说法是”You can’t debug on a display device. Using cuda-gdb requires a dedicated device. … I mean that the GPU you debug on can’t be the one running your display. So unless you have at least two GPUs, or you are not running X windows, you can’t use cuda-gdb.I get “No Cuda devices” although nvcc —version shows correct output and I can compile and run, just not debug”,大意是使用cuda-gdb需要一个单独的专用的GPU,要么有两个GPU,要么不运行X(Linux下的图形界面服务器),可以用
ps aux | grep '[X]'来查一下,但是笔者的并没有运行X。cuda-gdb “No CUDA devices” but CUDA programs run - CUDA / CUDA Programming and Performance - NVIDIA Developer Forums也是同样的意思 - 可能需要在wsl2重新配置cuda了,WSL2安装CUDA踩坑Debug全记录 - rthete - 博客园,如果以后想折腾可以再重装一下
🚩【真有用的方法】重启!
2 验证
验证方法:使用libtorch做逻辑和精度验证,使用curand设置统一的随机数,cuRAND mt19937 example - github
进行example的测试
CMake配置:
add_executable(mt19937-app curand_mt19937_lognormal_example.cpp)
set_property(TARGET mt19937-app PROPERTY CXX_STANDARD 17)
find_package(CUDA REQUIRED)
target_link_libraries(mt19937-app
PRIVATE
${TORCH_LIBRARIES}
CUDA::curand
)\=\=\=\=\=\=\=\=\=\=5/21\=\=\=\=\=\=\=\=\=\=
检验:对基准和my_falsh的输出进行平铺处理.view(-1),发现前0~63个输出对的上,64及之后的对不上。
猜测:
- qkgemm?✔
- softmax?✔
- qkvgemm?❌
问题出在更新m和l时索引出错,其实这也很符合直觉,同一个Q下第一个分片数据没问题,第二个分片就出事了,第一个分片和第二个分片有联系的变量只有m和l了,那就printf查看计算O的公式、row_m_prev和row_m的值,发现同一个Q下的切片中,row_m有更大的值,但是row_m_prev对不上前一次的更新值,所以就去看关于m的变量,发现是存储新的m值时索引出错
准确性检验完成!
性能测试:然后在FA1和基准测试的代码里加上curand随机数生成,两边的q、k、v各使用同一个种子
torch:0.638ms
my FA1:36ms
也许是家用级显卡(3050)限制了FA1的发挥吧哈哈o( ̄▽ ̄)ブ



