Lesson1 整体架构
Llama2:生成式模型以decoder-only为架构
由两个Decoder组成:
①Context Decoder,位于prompt阶段,用来生成一个token;全量推理:输入是一个句子,只需要生成第一个token;具有并行计算的特点
②Mask self Decoder,位于generate阶段,用来生成第二个token;增量推理:输入是一个token,在gpt上的表现为每次吐出为一个token;每次输入的都是上一个输出的token
Transformer系列:注意力机制的优化,MQA和GQA原理简述 - 简书
Lesson2 项目搭建&embedding kernel
讲解了:src/utils/tensor.hsrc/kernels/input_embedding.cusrc/kernels/input_embedding.htests/unittests/test_input_embedding.cu
-src
|-kernels
|-|-input_embeding.cu
|-utils
|-|-tensor.h
|-weightsLLMengine/src/utils/tensor.h
Struct Tensor{
Device location,
DataType dtype,
std::vector<int> shape;
...
virtual int size() const {
if (shape.size() == 0) {
// TODO: add an reminder info
return 0;
}
return std::accumulate(shape.begin(), shape.end(), (int)1, std::multiplies<int>());
}
...
template<typename T>
TensorWrapper<T>* as(){
return static_cast<TensorWrapper<T>*>(this); // 下行转换(显式),将this(Tensor类型的当前对象)转换为TensorWrapper<T>类型的指针
}
}
Class TensorWrap: public Tensor {
T * data;
...
}
Struct TensorMap{
std::unordered_map(std::string, Tensor*> tensor_map);
...
}std::unorder_map:是一个关联容器,用于存储键值对,键是该Tensor的名字,值是指向Tensor类型变量的指针- 关于为什么要在
TensorWrap中先继承父类Tensor再实现模板化T* data:Tensor要放到TensorMap中,而C++作为强类型语言,不支持字典存放不同类型的tensor(因为类型定义为Tensor的指针,如果在Tensor中加入了T*作为成员,可能会乱套了) std::accumulate(shape.begin(), shape.end(), (int)1, std::multiplies<int>());:做乘积,初始乘的值为1
如果.cpp文件调用带有cuda语法的函数,则其定义不能存在.h文件里,例如含有<<< >>>
例子:在src/kernel/input_embedding.cu中
- 定义了
launchInputEmbedding👇template<typename T> void launchInputEmbedding(TensorWrapper<int>* input_ids, // INT [token num] TensorWrapper<T>* output, // FP32 [token num, hidden_size] = [token num, 4096] EmbeddingWeight<T>* embed_table// FP32 [vocal_size, hidden_size] ) { // 分配线程块,核函数需要的维度信息 const int blockSize = 256; const int max_context_token_num = output->shape[0]; // token num const int hidden_size = output->shape[1]; const int gridSize = 2048; LLM_CHECK_WITH_INFO(max_context_token_num == input_ids->shape[0], "input ids 1st shape should equal to 1st shape of output"); embeddingFunctor<T><<<gridSize, blockSize>>>(input_ids->data, output->data, embed_table->data, max_context_token_num, hidden_size); - 实例化
- 显式实例化是告诉编译器生成一个模板函数的特定实例。在模板函数定义中,只是定义了一个通用的逻辑,但没有真正生成代码。只有在模板实例化的时候,编译器才会根据具体的数据类型来生成相应的函数代码。
- 原因:
- 避免代码膨胀:如果不显式实例化,那么每次使用不同类型调用模板函数时,编译器都会生成新的代码
- CUDA编译限制
- 分别生成了👇两种类型的具体实例
T=float、T=half// 显式实例化模版函数,由于cuda的语法规则,不能存在.cpp文件里,因此只能在此实例化 template void launchInputEmbedding(TensorWrapper<int>* input_ids, TensorWrapper<float>* output, EmbeddingWeight<float>* embed_table); template void launchInputEmbedding(TensorWrapper<int>* input_ids, TensorWrapper<half>* output, EmbeddingWeight<half>* embed_table);
src/kernels/input_embedding.cu
__global__ void embeddingFunctor(const int* input_ids,
T* output,
const T* embed_table,
const int max_context_token_num,
const int hidden_size)
{
int index = blockIdx.x * blockDim.x + threadIdx.x;
while (index < max_context_token_num * hidden_size) {
int id = input_ids[index / hidden_size];
output[index] = embed_table[id * hidden_size + index % hidden_size];
index += blockDim.x * gridDim.x;
}
} index的索引对应的是output的输出的每个位置?
index的索引对应的是output的输出的每个位置?
这个kernel的用处:将原本输入格式的[batch size, sequence length]变成[batch size, sequence length, hidden size]
有.cpp文件、.cc文件、.cu文件的目录下需要放CMakeLists.txt文件
Lesson3 Calculate padding offset kernel
讲解了:src/kernels/cal_paddingoffset.cusrc/kernels/cal_paddingoffset.htests/unittests/test_cal_paddingoffset.cu
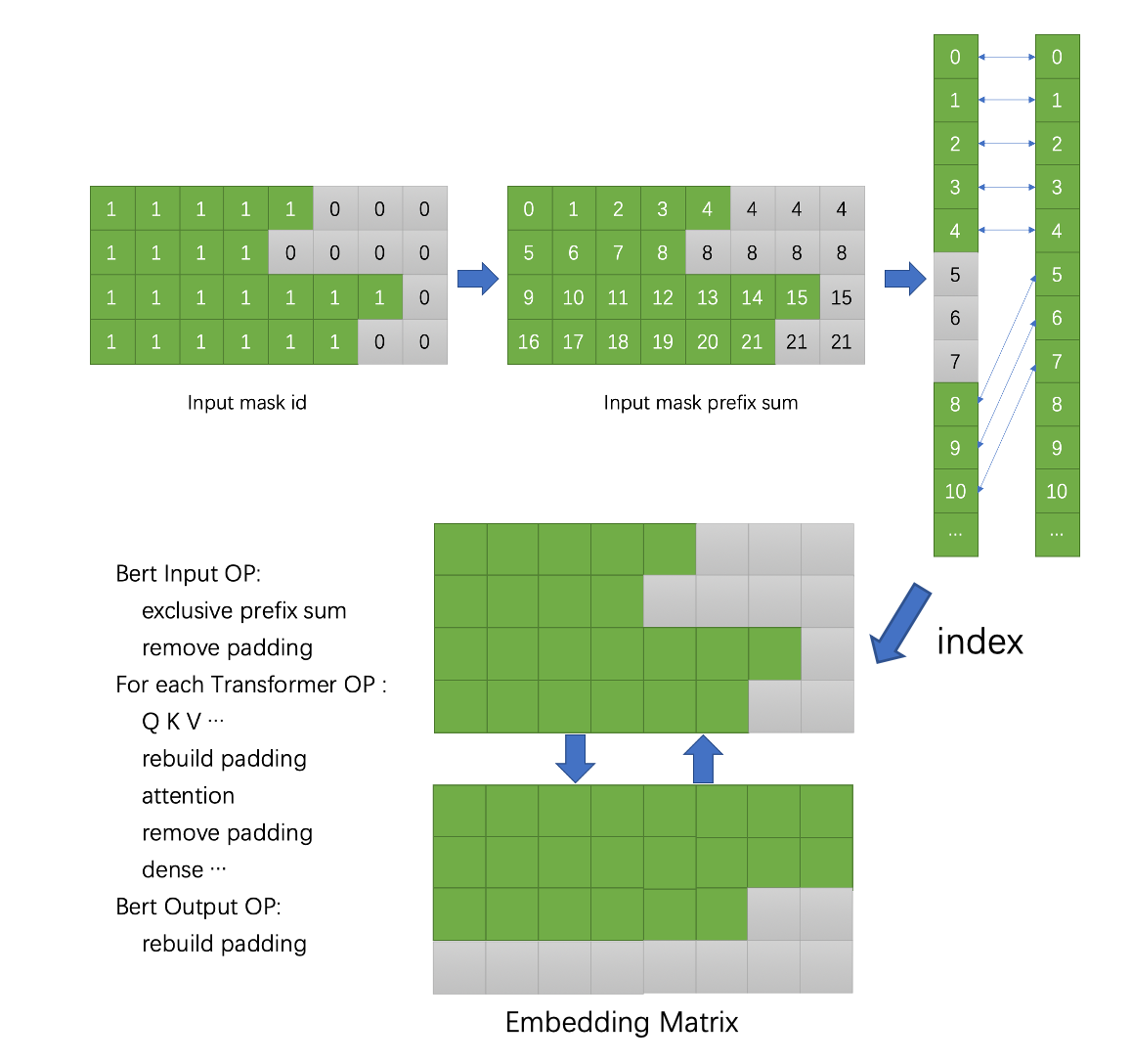
src/lkernels/cal_paddingoffset.h
void launchCalPaddingoffset(TensorWrapper<int>* padding_offset,
TensorWrapper<int>* cum_seqlens,
TensorWrapper<int>* input_lengths
);- 参数:
padding_offset:[batch size, max q_seq length]记录每个token在其之前的padding个数
cum_seqlens:[batch size + 1]第一个句子累积长度是它本身,第二个句子累积长度是第一句+第二句长度
input_lengths:[batch size]每个句子的输入长度,本身的
launchCalPaddingoffset函数的目的是输出padding个数和累积长度 - 例子:
11100
11000
11111
batch size = 3
seqlen = [3, 2, 5]
max_q_len = 5
padding_offset = [0, 0, 0, 0, 0
cum_seqlens = [0, 3, 5, 10]2, 2, 2, 2, 2 5, 5, 5, 5, 5]
相比于Lesson2中的模板化,这里不需要模板化的原因是,该函数的参数都是int类型,而Lesson2中的是T类型,需要对其做FP16和FP32的模板化
src/kernels/cal_paddingoffset.cu
__global__ void CalPaddingoffset(int* padding_offset,
int* cum_seqlens,
const int* input_lengths, //actual input lens
const int batch_size,
const int max_q_len) {
// 自己打的24-10-11
int cum_offset = 0;
int ind = 0;
int total_seqlen = 0;
for(int b = 0; b < batch_size; b++) { // b对应每个batch中的第b+1个seq
int seqlen = input_lengths[b]; // 获取每个句子长度
cum_seqlens[b] = total_seqlen; // (1)将累积的seqlen存入到每个句子中,cum_seqlens[0] = 0, ..., cum_seqlens[0] = 最后一个句子的句子累积长度
for( int i =0; i < seqlen; i++) {
padding_offset[ind] = cum_offset; // (2)将累积的offset存入到每个token中,padding_offset的下标应该是一个累积的值,所以应该在for的外部定义ind然后取其为下标
ind++;
}
cum_offset += max_q_len - seqlen; // 获取每个句子累积的offset
total_seqlen += seqlen; // 获取每个句子累积的句子长度
}
cum_seqlens[batch_size] = total_seqlen;
}kernel写完之后还需要写CMake文件test/unittest/CMakelist.txt:将test编译为可执行文件
add_executable(cal_paddingoffset // ※
test_input_embedding.cu
)
target_link_libraries(
cal_paddingoffset PUBLIC //这要和※处的名称对应
-lcudart
-lcudadevrt
paddingoffset // 这里可以自己起
)src/kernels/CMakelist.txt(注意和上面的名称的对应)add_library(paddingoffset STATIC cal_paddingoffset.cu)
set_property(TARGET paddingoffset PROPERTY CUDA_SEPARABLE_COMPILATION ON)
set_property(TARGET paddingoffset PROPERTY POSITION_INDEPENDENT_CODE ON)
set_property(TARGET paddingoffset PROPERTY CUDA_RESOLVE_DEVICE_SYMBOLE ON)Lesson4 RMS norm
讲解了:src/kernels/rmsnorm_kernel.cusrc/kernels/rmsnorm_kernel.htests/unittests/test_rmsnorm.cusrc/utils/vectorize_utils.hsrc/weights/llama/norm_weights.h
src/utils/vectorize_utils.h
template<typename T>
struct Vec{
using Type = T;
static constexpr int size = 0;
};
// 除此之外还定义了float4(size=4),half2(size=2)static:表示该成员size属于类而不是某个实例(对象)constexpr:定义一个静态的类成员,并且该成员是一个编译时常量,在编译时就确定float4和half2分别是包含4个float分量的向量和包含2个half分量的向量作用是存储通用的向量化数据结构
src/weights/llama/norm_weights.h
template<typename T>
struct LayerNormWeight {
T* gamma;
};4.1src/kernel/rmsnorm_kernel.cu
(1)warpReduceSum
template<typename T>
__device__ T warpReduceSum(T val){
for(int i = 32 / 2; i > 0; i >>= 1){
val += __shfl_xor_sync(0xffffffff, val, i);
}
return val; // 最后这个warp的结果保存在第一个第一个线程(threadIdx.x=0)
}将一个warp中的数据加起来
(2)blockReduceSum
template<typename T>
__device__ T blockReduceSum(T val){
int tid = threadIdx.x;
it wid = tid / 32;
int laneid = tid % 32;
int warpnum = (blockDim.x + 32 - 1) / 32;
val = warpReduceSum<T>(val); // val是每个warp的总和的值
static __shared__ T warpsum[64]; // 不能写warpnum,因为申请的是静态的,需要传入编译期常量64
if(landid == 0) // 如果是wrap的第一个线程(存有该wrap的结果)
{
warpsum[wid] = val; // 将每个warp的求和放入warpsum中
}
__syncthreads(); // 处理完共享内存的读写后要加上`__syncthreads();!!!
T sum = tid < warpnum ? warpsum[wid] : (T)0;
// 处理前warpnum个warpsum[wid],并且确保使用线程id为0~warpnum-1来处理
sum = warpReduceSum<T>(sum);
return sum;
}将一个block的数据加起来
参数:
tid:全局的thread idx (0~?)wid:wrap idx,每32个threads为一个wrap (0~?)laneid:wrap中的thread的编号(0~31)warpnum:用到的warp的个数,最小为1,所以这里需要向上取整warpsum:大小为64的类型为T的数组,存放每个warp的总和
(3)RMSNorm
计算公式:$\dfrac{x_i×g_i}{\sqrt{\sum^iE(x_i^2)+eps}}$
template <typename T>
__global__ void RMSNorm(T* decoder_in,
T* decoder_residual,
T* scale, //[q_hidden_units], RMSNorm weights
float eps, //RMSNorm eps
int num_tokens,
int hidden_units) {
}参数:
decoder_in:是输入同时也是输出位置,[num tokens, q_hidden_units]decoder_residual:暂时不知道这个的用处scale:可学习的参数(权重),[q_hidden_units]eps:很小的正数num_tokens:token的个数hidden_units:隐藏层的单元的数量int vec_size = Vec<T>::size;
using Vec_t = typename Vec<T>::Type;
Vec_t *dout = reinterpret_cast<Vec_t*>(decoder_in + blockIdx.x * hidden_units); // 每个线程需要读的数据的偏移; block的数量是token的数量
Vec_t *rsd = reinterpret_cast<Vec_t*>(decoder_residual * blockIdx.x * hidden_units);
float thread_sum = 0.0f; 参数:
vec_size:读取vector的大小,比如float4的向量个数为4,half2的向量个数为2Vec_t:读取类型并存到Vec_t中!前一句没有用
typename而后一句用了的原因是:①前者属于非依赖型,
size的值在编译时可以确定,与Td的具体类型无关;②后者时依赖类型,
Type是一个类型别名,取决于T,因此需要typename关键字来告诉编译器他是一个类型dout:根据线程指向每一个以输入向量为起始的block的开头,每一个block对应一个token,每个block之间相差大小为hidden units的间隔rsd:同doutthread_sum:用于求和for (int idx = threadIdx.x; idx < hidden_units / vec_size; idx += blockDim.x) {
Vec_t vec = dout[idx];
rsd[idx] = vec;
thread_sum += vec.x * vec.x;
thread_sum += vec.y * vec.y;
thread_sum += vec.z * vec.z;
thread_sum += vec.w * vec.w;
}
thread_sum = blockReduceSum<float>(thread_sum); 用于求$\sum^iE(x_i)$,每个block得到一个总和
参数:
vec:将dout[idx]的数据存到vec中
thread_sum:每个线程都有一个私有的副本注意:
idx的范围是从threadIdx.x开始的,范围是0~blockDim.x-1因此每个for循环实际只处理了一个block的求和,
idx+=blockDimx.x使得可以对下一个block进行求和所以说这里的求和是block层面的,也是每个token层面的
__shared__ float inv_mean;
if (threadIdx.x == 0) {
inv_mean = rdqrtf(thread_sum / hidden_units + eps);
}
__syncthreads(); // share memory inv_mean写入完成后要加上这句话 用于计算平均值$inv_mean\dfrac{1}{\sqrt{\sum^iE(x_i^2)+eps}}$
inv_mean:因为均值是block层面的,所以最好把它设为share memoryshare memory写入完成后要加上
__syncthreads();Vec_t *s = reinterpret_cast<Vec_t *>(scale);
for (int idx = threadIdx.x; idx < hidden_units / vec_size; idx += blockDim.x) {
Vec_t vec = dout[idx];
dout[idx].x = vec.x * inv_mean * s[idx].x; // 因为输入输出都是decoder_in,所以需要实实在在地进dout[idx]这个指针指向的buffer,等号左边不能用vec
dout[idx].y = vec.y * inv_mean * s[idx].y; // 因为vec size是4,所以累加4次
dout[idx].z = vec.z * inv_mean * s[idx].z;
dout[idx].w = vec.w * inv_mean * s[idx].w;
}用于计算$inv_mean × x_i ×g_i$
注意:需要把结果写回
dout中
(4)launchRMSNorm
template<typename T>
void launchRMSNorm( TensorWrapper<T>* decoder_out,
TensorWrapper<T>* decoder_residual,
LayerNormWeight<T>& attn_norm_weight,
bool is_last
){
int num_tokens = decoder_out->shape[0];
int hidden_units = decoder_out->shape[1];
int vec_size = Vec<T>::size;
int num_threads = hidden_units / 4;
T* rsd = decoder_residual->data;
dim3 grid(num_tokens); // num_tokens个block
dim3 block(num_threads); // hidden_units / 4个block
RMSNorm<T><<<grid, block>>>(decoder_out->data,
rsd,
attn_norm_weight.gamma, // scale
eps,
num_tokens,
hidden_units);
}Lesson5 Casual Mask
讲解了:src/kernels/build_casual_mask.cusrc/kernels/build_casual_mask.htests/unittests/test_casual_mask.cu
src/kernel/build_casual_mask.cu
template<typename T>
__global__ void BuildCausalMasksConsideringContextPastKV(T* mask,
const int* q_lens,
const int* k_lens,
int max_q_len,
int max_k_len){
int tid = threadIdx.x;
int qlen = q_lens[blockIdx.x];
int klen = k_lens[blockIdx.x];
mask += blockIdx.x * max_k_len * max_q_len; // 每个block只有256个线程,相应的,mask也需要有偏移量移动到下一个mask上,与block的移动同步
while(tid < max_k_len * max_q_len){
int q = tid / max_k_len; // 目前处于哪一行
int k = tid % max_k_len; // 目前处于哪一列
bool is_one = q < qlen && k < klen && k <= q + (klen - qlen);
mask[tid] = static_cast<T>(is_one);
tid += blockDim.x;
}
}参数:
mask:[batch_size, max_q_len, max_k_len]每个mask是一个矩阵,用于表示哪些token对于目前对话是可见的(置1)和不可见的(置0)q_lens:[batch_size],作为input lens,我的理解是当前对话的输入k_lens:[batch_size],作为context lens,我的理解是结合一定程度的上下文的输入max_q_len&max_k_len:分别是q_lens和k_lens中最大的理解:
int qlen = q_lens[blockIdx.x];
int klen = k_lens[blockIdx.x];👆每个
block对应一个对话,batch_size = 对话个数。这里是分别取每个对话的qlen和klenmask += blockIdx.x * max_k_len * max_q_len;
while(tid < max_k_len * max_q_len){
int q = tid / max_k_len; // 目前处于哪一行
int k = tid % max_k_len; // 目前处于哪一列
bool is_one = q < qlen && k < klen && k <= q + (klen - qlen);
mask[tid] = static_cast<T>(is_one);
tid += blockDim.x;
}- 为了确保
mask里的每个数都能被处理到(第三句很重要)mask[tid] = static_cast<T>(is_one);:block中的一个线程对应mask里的一个数,但是blockDim.x=256,所以需要加上第三句话- 循环条件
tid < max_k_len * max_q_len:确保每个数都有对应线程处理 mask += blockIdx.x * max_k_len * max_q_len;:mask的大小>block的线程数的情况👇
那么就是一个block处理一个mask,如果block大小小于mask的话,就继续用该block的线程处理mask剩余的数
Lesson6 Linear
讲解了:src/kernels/cublas_utils.h:定义cublas类src/kernels/cublas_utils.cc:实现cublas类src/kernels/linear.cusrc/kernels/linear.htests/unittests/test_linear.cu
6.1 cublas类的声明与定义
src/kernels/cublas_utils.h
class cublasWrapper {
private:
cublasHandle_t cublas_handle;
cudaDataType_t Atype;
cudaDataType_t Btype;
cudaDataType_t Ctype;
cublasComputeType_t computeType;
public:
cublasWrapper(cublasHandle_t cublas_handle);
~cublasWrapper();
void setFP32GemmConfig();
void setFP16GemmConfig();
void Gemm(cublasOperation_t transa,
cublasOperation_t transb,
const int m,
const int n,
const int k,
const void* A,
const int lda,
const void* B,
const int ldb,
void* C,
const int ldc,
float alpha,
float beta);
// for qk*v and q*k
void stridedBatchedGemm(cublasOperation_t transa,
cublasOperation_t transb,
const int m,
const int n,
const int k,
const void* A,
const int lda,
const int64_t strideA,
const void* B,
const int ldb,
const int64_t strideB,
void* C,
const int ldc,
const int64_t strideC,
const int batchCount,
float f_alpha,
float f_beta);
};👆声明
cublasWrapper类,batchedGemm相对于Gemm多了步长stride和batchCount
定义部分:
①构造函数
cublasWrapper::cublasWrapper(cublasHandle_t cublas_handle,
cublasLtHandle_t cublaslt_handle):
cublas_handle(cublas_handle),
cublaslt_handle(cublaslt_handle){
}cublasHandle_t是cublas库中的一个类型,与句柄有关- 传入
cublas_handle返回到类中的cublas_handle_ cublasHandle_t和cublasLtHandle_tcublasHanle_t:用于一般的线性代数运算(如向量和矩阵操作)cublasLtHandle_t:用于更高级的矩阵运算,特别是自定义和优化矩阵乘法(GEMM),在需要复杂配置或多种数据类型时有用处
②单精度与半精度的配置
void cublasWrapper::setFP32GemmConfig()
{
Atype = CUDA_R_32F;
Btype = CUDA_R_32F;
Ctype = CUDA_R_32F;
computeType = CUBLAS_COMPUTE_32F; //
}
void cublasWrapper::setFP16GemmConfig()
{
Atype = CUDA_R_16F;
Btype = CUDA_R_16F;
Ctype = CUDA_R_16F;
computeType = CUBLAS_COMPUTE_16F;
}- 对于
computeType,当cuda version<11.0时用CUDA_R_32F,cuda version>11.0时使用CUBLAS_COMPUTE_32F,半精度的同理
③为alpha和beta赋值
const void* alpha = is_fp16_computeType ? reinterpret_cast<void*>(&(h_alpha)) : reinterpret_cast<void*>(&f_alpha);
const void* beta = is_fp16_computeType ? reinterpret_cast<void*>(&(h_beta)) : reinterpret_cast<void*>(&f_beta);- 如果
is_fp16_computeTyp为1,则传入半精度的alpha给alpha,beta同理
④关于batchedGemm与Gemm同理
6.2 Gemm
src/kernels/linear.cu
template<typename T>
void launchLinearGemm(TensorWrapper<T>* input,
BaseWeight<T>& weight,
TensorWrapper<T>* output,
cublasWrapper* cublas_wrapper,
bool trans_a = false,
bool trans_b = false){
{
Bk = input->shape.size() == 3 ? input->shape[1] * input->shape[2] : input->shpe[1];
Cm = output->shape.size() == 3 ? output->shape[1] * output->shape[2] : output->shpe[1];
int lda = Am;
int ldb = Bk;
int ldc = Cm;
cublasOperation_t transA = trans_b ? CUBLAS_OP_T : CUBLAS_OP_N;
cublasOperation_t transB = trans_a ? CUBLAS_OP_T : CUBLAS_OP_N;
// 可能会出现输入为[bs, 1, hiddenunits] * [hiddenunits, hiddenunits],所以需要检查输入的维度
if(!trans_b && !trans_a){
LLM_CHECK_WITH_INFO(Ak == Bk, "2nd dim of input MUST = 1st dim of weight!");
}
cublas_wrapper->Gemm(transA,
transB,
trans_b ? Ak : Am, // m
Cn, // n
Bk, // k
weight.data,
lda,
input->data,
ldb,
output->data,
ldc,
1.0f,
0.0f);}① 关于A、B、C
(1)一般的gemm
A:
input shape = [seqlen, hidden_units]B:
weight shape = [hidden_units, hidden_units]A * B = C with trans_b = false
对于qkvlinear,是指将三次矩阵乘法融合到一次input=[seqlen, hidden_units]weight shape = [hidden_units, 3×hidden_units]
(2)出现在sampling的LMHead
A:input shape = [batch_size, hidden_units]
B:weight_shape = [vocabulary_size, hidden_units]A * B = C with transb = true
②重点与难点:
torch.nn.linear的计算公式是$y=x×w^T$,修改之前是$y=x×w$,因此trans_b=True- cublas API接受的输入以及输出的内存排布全部都默认为列主序(column-major)

- 因此,我们的思路是
- 从原本的$y=x×w$,因为
nn的计算方式 - 加上
trans_b=True后可以实现$y=x×w^T$,因为列主序(从行主序到列主序需要将两边同时转置)- 这里的
trans_b对应的是原本我们理解的$y=x×w$公式,trans_b对应$w$ - 变成column major之后
A对应$w^T$,所以是用trans_b决定trans_A
- 这里的
- 将$y=x×w^T$变成$y^T=w×x^T$后可以实现列序列的要求,那么对应$y=x×w$就应该变成$y^T=w^T×x^T$
- 即从原始的$y=x×w$变成我们需要的公式,只需要
- 添加
trans_b=True - 公式$y^T=w^T×x^T$
- 添加
- 从原本的$y=x×w$,因为
int Am = weight.shape[1];
int Ak = weight.shape[0];
int Bk = input->shape[1];
int Bn = input->shape[0];
int Cm = output->shape[1];
int Cn = output->shape[0];6.3 StrideBatchGemm
①关于input1和input2
$q×k$
input1:q shape = [batch_size, head_nums, seqlen(=len_q), hidden_units]
input2:k shape = [batch_size, head_nums, seqlen(=len_k), hidden_units]A * B = C with trans_b = true
$qk×v$
input1:qk shape = [batch_size, head_nums, seqlen(=len_q), seqlen(=len_k)]
input2:v shape = [batch_size, head_nums, seqlen(=len_k), hidden_units]A * B = C with transb = false
实际上在src/kernels/linear.cu中处理过程与Gemm差不多
②StrideBatchGemm和BatchGemm相比
假如A=[1,2,3,4]
- StrideBatch多一个
Stride变量,用于作地址偏移取出要相乘的值,偏移量等于A[i]和A[i+1]之间的距离- =3*4
- 两个都有
batchCount变量
初始化列表例子 :
class Person {
public:
////传统方式初始化
//Person(int a, int b, int c) {
// m_A = a;
// m_B = b;
// m_C = c;
//}
//初始化列表方式初始化
Person(int a, int b, int c) :m_A(a), m_B(b), m_C(c) {}
void PrintPerson() {
cout << "mA:" << m_A << endl;
cout << "mB:" << m_B << endl;
cout << "mC:" << m_C << endl;
...
}RAII机制可以自动析构掉一些类成员变量
huggingface的7b chat中linear的weight全是转置后的,比如gate的权重应该是[q_hidden_units, inter_size],但是在huggingface里是[inter_size, q_hidden_units],所以launchLinearGemm的trans_b对于所有linear weights来说都是true
Lesson7 Debug(一)
src/kernels/rmsnorm_kernel.cu
dout[idx].x = __float2half(vec.x * inv_mean) * s[idx].x;
dout[idx].y = __float2half(vec.y * inv_mean) * s[idx].y;出现如下报错:
error: more than one operator "*" matches these operands:
built-in operator "arithmetic * arithmetic"
function "operator*(const __half &, const __half &)"在编译器执行乘法运算时,发现有多个符合条件的*操作符但是不确定应该使用哪一个
built-in operator "arithmetic * arithmetic":这是CUDA支持的基本算术类型之间的乘法操作(如整数或浮点数)。function "operator*(const __half &, const __half &)":这是CUDA中针对__half类型(即半精度浮点数)提供的乘法操作符。
解决方法:
将代码改为dout[idx].x = s[idx].x * __float2half(__half2float(vec.x) * inv_mean); dout[idx].y = s[idx].y * __float2half(__half2float(vec.y) * inv_mean);
编译顺序从kernels到tests原因:
- 编译
tests时需要调用到src/kernels的cuda函数或者launch函数,所以需要先编译kernels文件下的 - 在根目录下的
CMakeList.txt中有先后顺序add_subdirectory(src) add_subdirectory(tests)
Lesson8 RoPE
一文看懂 LLaMA 中的旋转式位置编码(Rotary Position Embedding)
讲解了:src/kernels/qkv_bias_and_RoPE.cusrc/kernels/qkv_bias_and_RoPE.hsrc/models/llama/llama_params.htests/unittests/test_bias_and_rope.cusrc/utils/vectorize_utils.h
本节融合算子的作用
- 将
qkv bias加到QKV上,QKV = [num tokens, qkv head num, head size]qkv head num=q head num+k head num+v head numk head num=v head num
- padding后,
QKV会被分割成三个矩阵q、k、v,- shape(q)=
[bs, q head num, max q len, head size] - shape(k/v)=
[bs, kv head num, max q len, head size]
- shape(q)=
- rope & attention
- 写回显存(gmem)
输入:
QKV shape=[num tokens, qkv head num, head size]
qkv bias shape = [qkv head num, head size]
输出:
q:[bs, q head num, max q len, head size]
k:[bs, kv head num ,max q len, head size]
v:[bs, kv head num, max q len, head size]
这里的max q len就是seqlen
下一节会讲到repeat kv
8.1 src/kernels/qkv_bias_and_RoPE.cu
llama使用的是QGA(Grouped-Query Attention),采用的是一组Q(N个)共享同一个KV
QKV第一个维度是token_num,因此网格的第一个维度x也是token_num,网格的第二个维度y是head_num(q head num)
qkv类型是BaseWeight<T>,在src/weights/base_weights.h中
template<typename T>
struct BaseWeight{
std::vector<int> shape;
T* data;
WeightType type;
T* bias; // qkv需要这一项
}①GetRoPRfreq()是用来求$θ$和$m$的
inline __device__ float2 GetRoPEfreq(int zid, int rot_embed_dim, float base, float t_step) {
float inv_freq = t_step / powf(base, zid / (float)rot_embed_dim); // 求mθ
return{cos(inv_freq), sin(inv_freq)};
}公式:$Θ=\{θ_i=10000^{-2(i-1)/d},i\in[1,2,…,d/2]\}$
入参:
zid:2(i-1)rot_embed_dim:d,词嵌入向量的维度base:公式中的10000t_step:time step,是要求的m,m表示第m个token
变量:inv_freq:就是$mθ_i$- $mθ_i=m\ ÷\ 10000^{2(i-1)/d}$
- $10000^{2(i-1)/d}$ =
powf(base,zid / (float)d)base=10000zid=2(i-1)- 因为传进来的
rot_embed_dim是int型的,所以加了个float
- 返回的是$cos(mθ_i)$和$sin(mθ_i)$
②GetRoPEres()是用来得到RoPE后的结果的
inline __device__ float2 GetRoPEres(float data, float data_rotate, const float2 coef){
float2 rot_v;
rot_v.x = coef.x * data - coef.y * data_rotate;
rot_v.y = coef.x * data_rotate + coef.y * data;
retern rot_v;
}入参:
data:head_size中的前半的数据data_rotate:head_size中后半的数据coef:通过GetRoPRfreq()得到的$cos(mθ_i)$和$sin(mθ_i)$
变量:- (举例)
rot_v.x=$cos(mθ_0)\ \ x_0\ -\ sin(mθ_0)\ \ x_{64}$ - (举例)
rot_v.y=$cos(mθ_0)\ \ x_{64}\ +\ sin(mθ_0)\ \ x_0$ - 上面两个为一组
rot_v,一组指的是他们共享$cos(mθ_0)$和$sin(mθ_0)$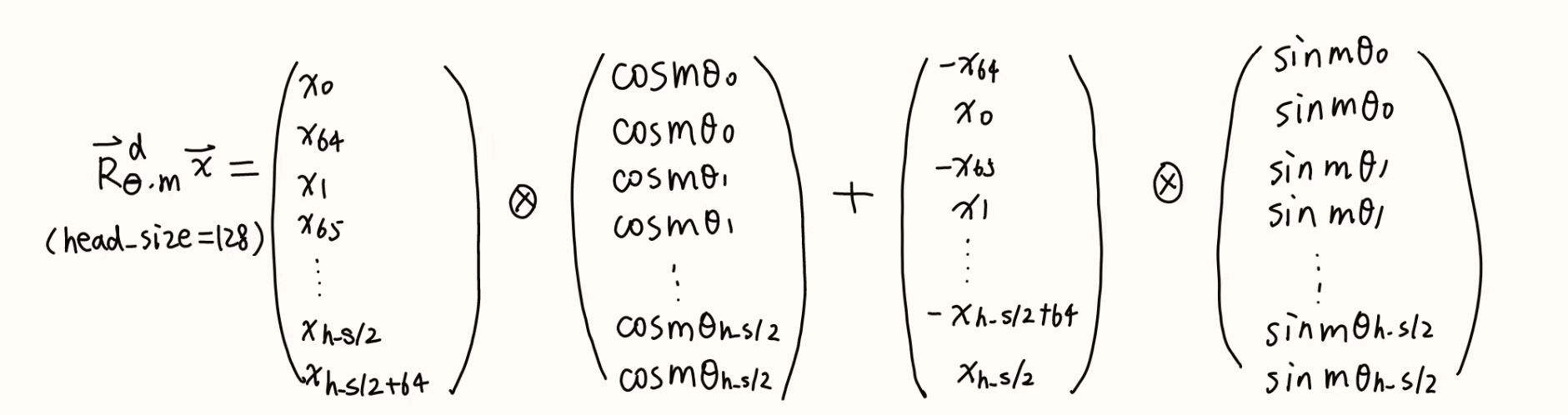
③add_fusedQKV_bias_transpose_kernel()
实际上并没有加上bias偏置项
template <typename T>
__global__ void add_fusedQKV_bias_transpose_kernel(
T *q_buf,
T *k_buf,
T *v_buf,
T *QKV,
const int *padding_offset, // created before qkv linear
const int *history_length,
const int *input_length, // actual length of each seq
const int batch_size,
const int seq_len, // max_seq_len to pad to
const int head_num,
const int kv_head_num,
const int head_size,
const int rotary_embedding_dim,
float rotary_embedding_base // default 10000 in llama
)1)配置block、thread和padding
int token_id = blockIdx.x;
int head_id = blockIdx.y;
int tid = threadIdx.x;
int token_padding_offset = padding_offset[token_id];token_id和head_id用于获得数据偏移量token_padding_offset是该token之前的padding个数
2)为写到显存里面做准备
int dst_token_id = token_id + token_padding_offset;
int batch_id = dst_token_id / seq_len;
int local_token_id = dst_token_id % seq_len;dst_token_id:可以理解为当前token_id在全部token中的位置token_id是当前token在不考虑padding时的token位置token_padding_offset是当前token之前的padding个数batch_id:当前token所在位置的对应的句子idlocal_token_id:当前token在当前句子的位置(0~seq_len-1)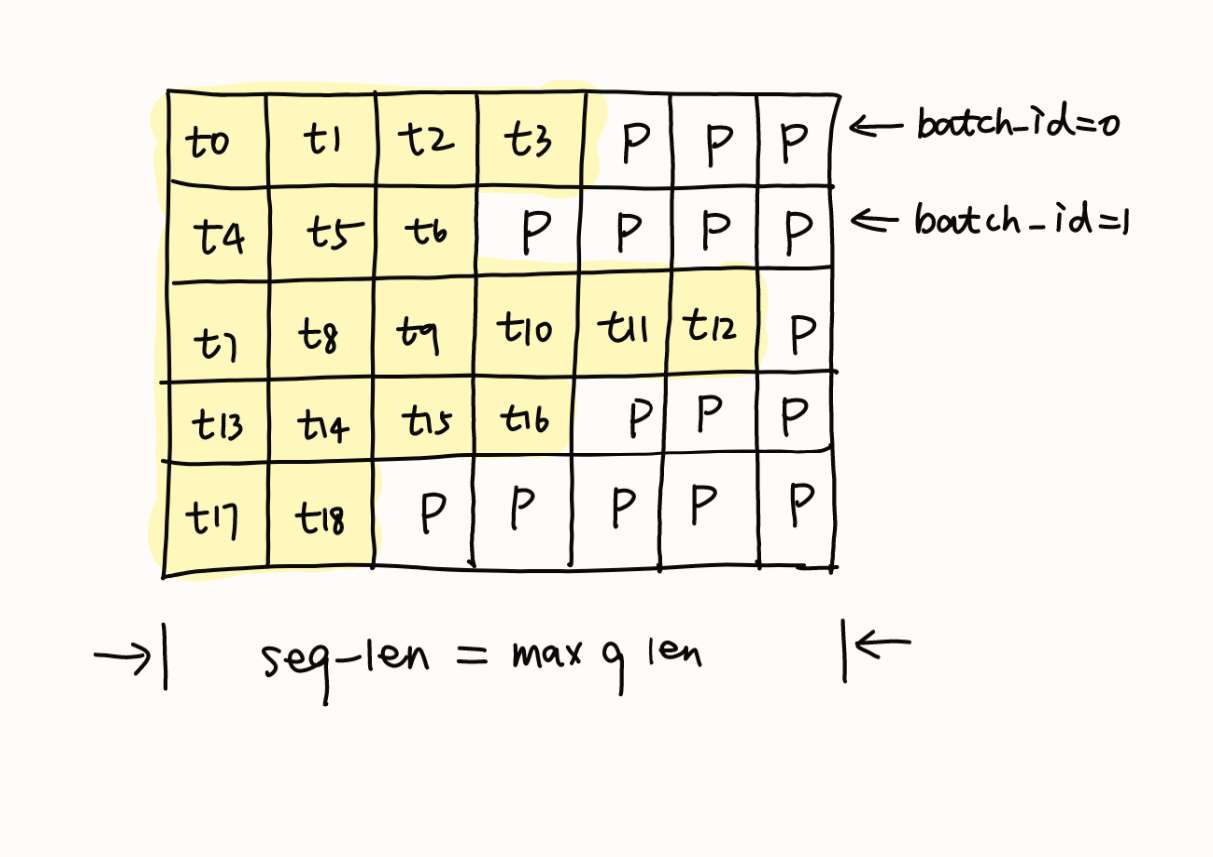
为了写到显存里才做的padding
3)基于(作为输入)QKV buffer的三个维度(num tokens, qkv head num, head size)获取q、k、v
int qkv_head_num = head_num + 2 * kv_head_num;
int q_id = token_id * qkv_head_num * head_size + head_id * head_size + tid;
int k_id = token_id * qkv_head_num * head_size + head_id * head_size + tid + head_num * head_size;
int v_id = token_id * qkv_head_num * head_size + head_id * head_size + tid + head_num * head_size + kv_head_num * head_size;qkv_head_num:其中head_num是q_head_num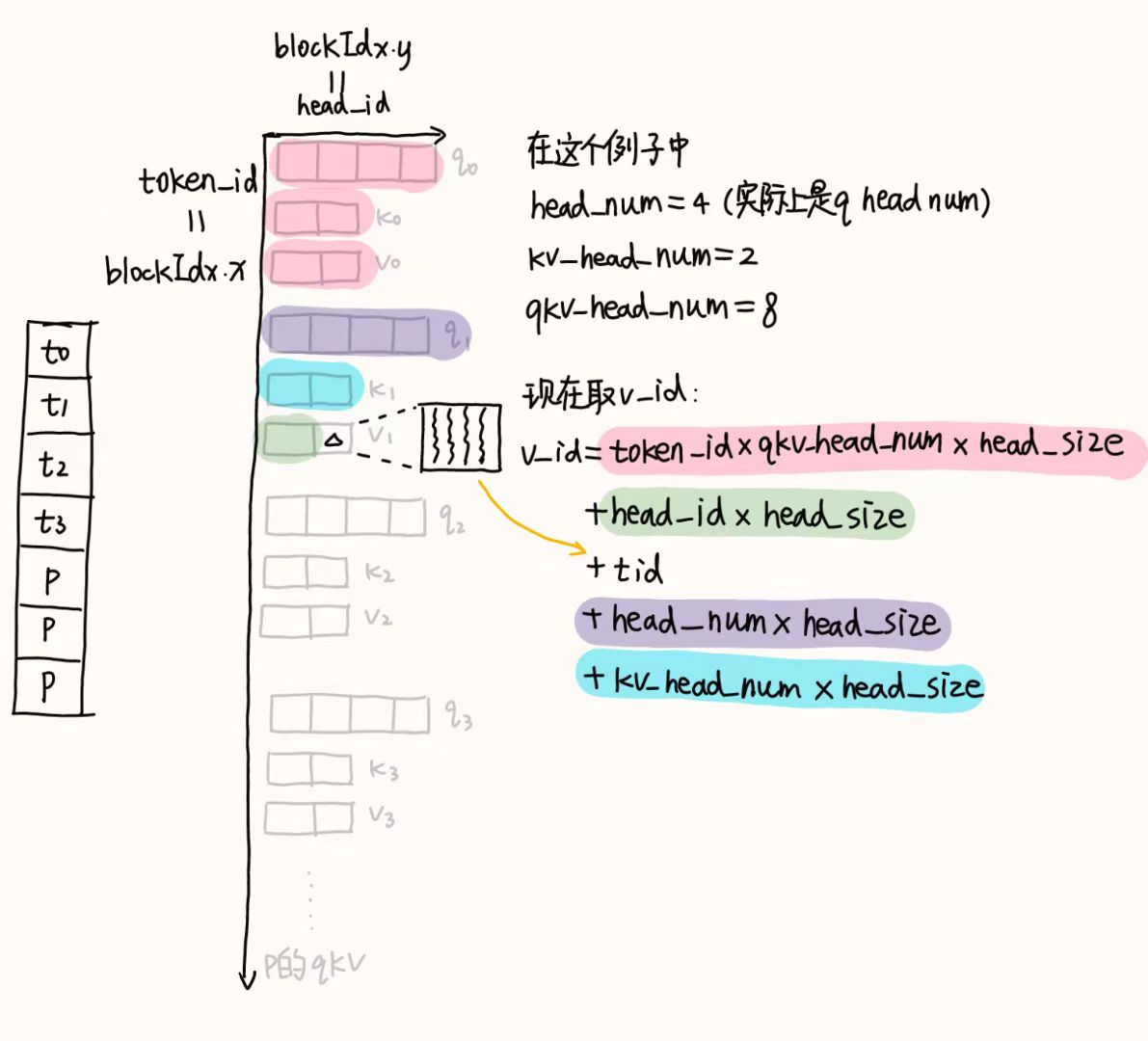
4)计算RoPE
const int cur_seq_history_len = history_length[batch_id];
const int context_length = cur_seq_history_len + input_length[batch_id]
const int timestep = cur_seq_history_len + local_token_id;
if(tid >= rotary_embedding_dim / 2){
return;
}
float2 cos_sin = GetRoPEfreq(tid * 2, rotary_embedding_dim, rotary_embedding_base, timestep);
float2 q_rotate = GetRoPEres(QKV[q_id], QKV[q_id + head_size / 2], cos_sin);
float2 k_rotate = GetRoPEres(QKV[k_id], QKV[k_id + head_size / 2], cos_sin);这里的长度都以token为单位
cur_seq_history_len:当前序列的历史的序列长度总和context_length:当前序列长度+历史的序列长度timestep:历史序列长度+当前seq中的token,得到当前token在整个序列中的位置
llama的旋转编码是将head size切分成两半,左一半与右一半对应做RoPE,所以当tid >= rotary_embedding_dim/2时就可以停止做RoPE计算,rotary_embedding_dim是词嵌入向量的维度,这里指的应该是token的维度
在q_rotate和k_rotate的计算过程中也能证实data和data_rotate对应的是线程,所以在上面的if语句中只需要一半的线程即可
5)写回gmem
int dst_q_id = batch_id * seq_len * head_num * head_size +
head_id * seq_len * head_size +
local_token_id * head_size + tid;
int dst_kv_id = batch_id * seq_len * kv_head_num * head_size +
head_id * seq_len * head_size +
local_token_id * head_size + tid;
q_buf[dst_q_id] = q_rotate.x;
q_buf[dst_q_id + head_size / 2] = q_rotate.y;
if(head_id < kv_head_num){
// 对于MQA和GQA
k_buf[dst_kv_id] = k_rotate.x;
k_buf[dst_kv_id + head_size / 2] = k_rotate.y;
}下面给出了
dst_q_id的例子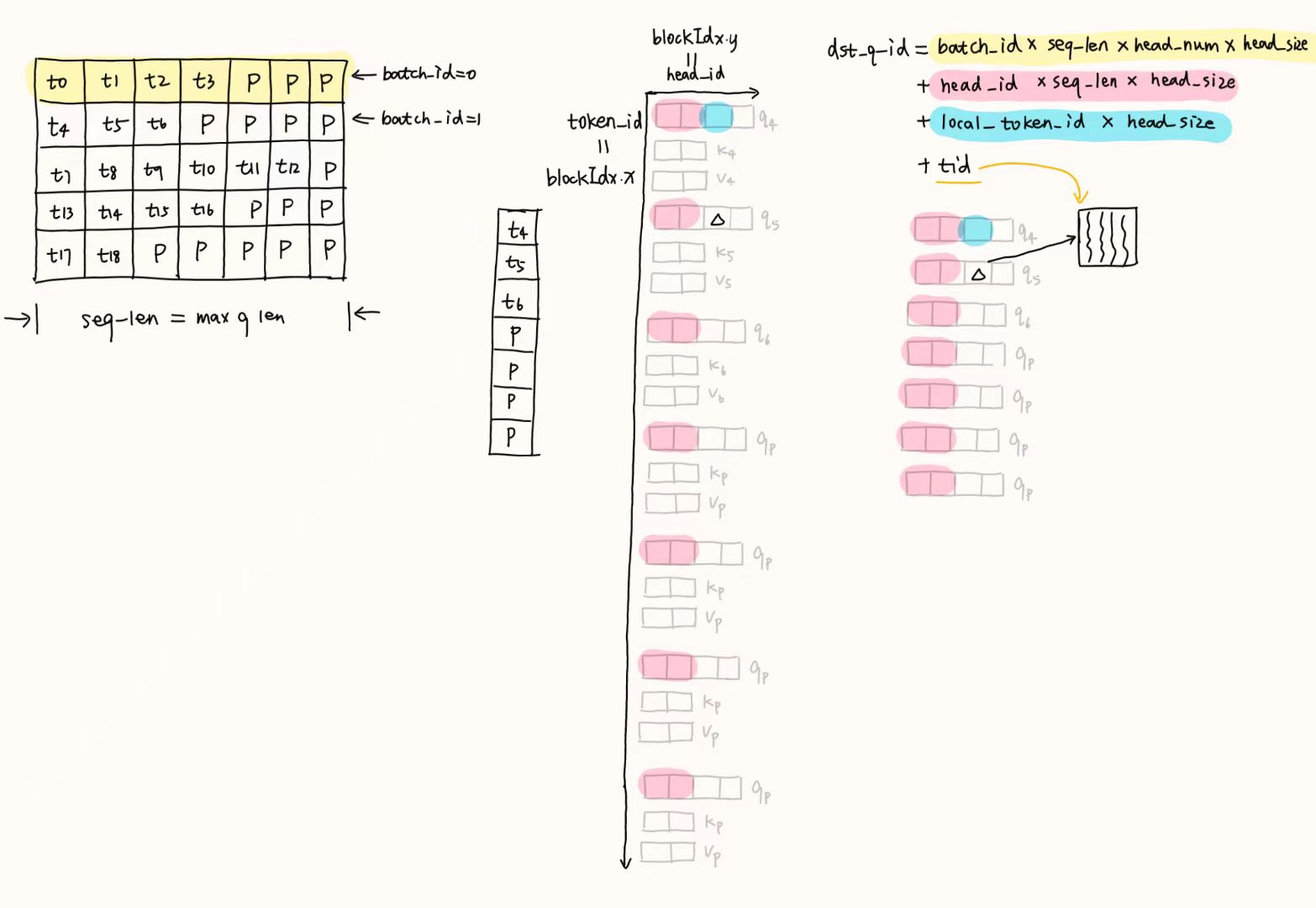
④rope_kernel_for_self_decoder()
template<typename T>
__global__ void rope_kernel_for_self_decoder(T* q,
T* k,
const int batch_size,
const int head_num,
const int kv_head_num,
const int head_size,
const int step,
int rotary_embedding_dim,
float rotary_embedding_base)这里主要针对self decoder
int tid = threadIdx.x;
int q_head_id = blockIdx.x;
int q_batch_id = blockIdx.y;
int kv_head_id = q_head_id / (head_num / kv_head_num); // 将kv_head_id的数量膨胀到q_head_id的数量
int kv_batch_id = q_batch_id;
int batch_stride = head_num * head_size; // seq len=1
int kv_batch_stride = kv_head_num * head_size;
int head_stride = head_size;
int q_offset = q_batch_id * batch_stride + q_head_id * head_stride + tid;
int k_offset = kv_batch_id * kv_batch_stride + kv_head_id * head_stride + tid;
if(tid >= rotary_embedding_dim / 2){
return;
}
float2 cos_sin = GetRoPEfreq(tid * 2, rotary_embedding_dim, rotary_embedding_base, step - 1); // 这里通过与hf相比发现要-1
float2 q_rotate = GetRoPEres(q[q_offset], q[q_offset + head_size / 2], cos_sin);
float2 k_rotate = GetRoPEres(k[k_offset], k[k_offset + head_size / 2], cos_sin);
q[q_offset] = q_rotate.x;
q[q_offset + head_size / 2] = q_rotate.y;
k[k_offset] = k_rotate.x;
k[k_offset + head_size / 2] = k_rotate.y;最后k[k_offset]不需要判断head_idx<kv_head_num是因为int kv_head_id = q_head_id / (head_num / kv_head_num);这里的对应关系不会令k head越出边界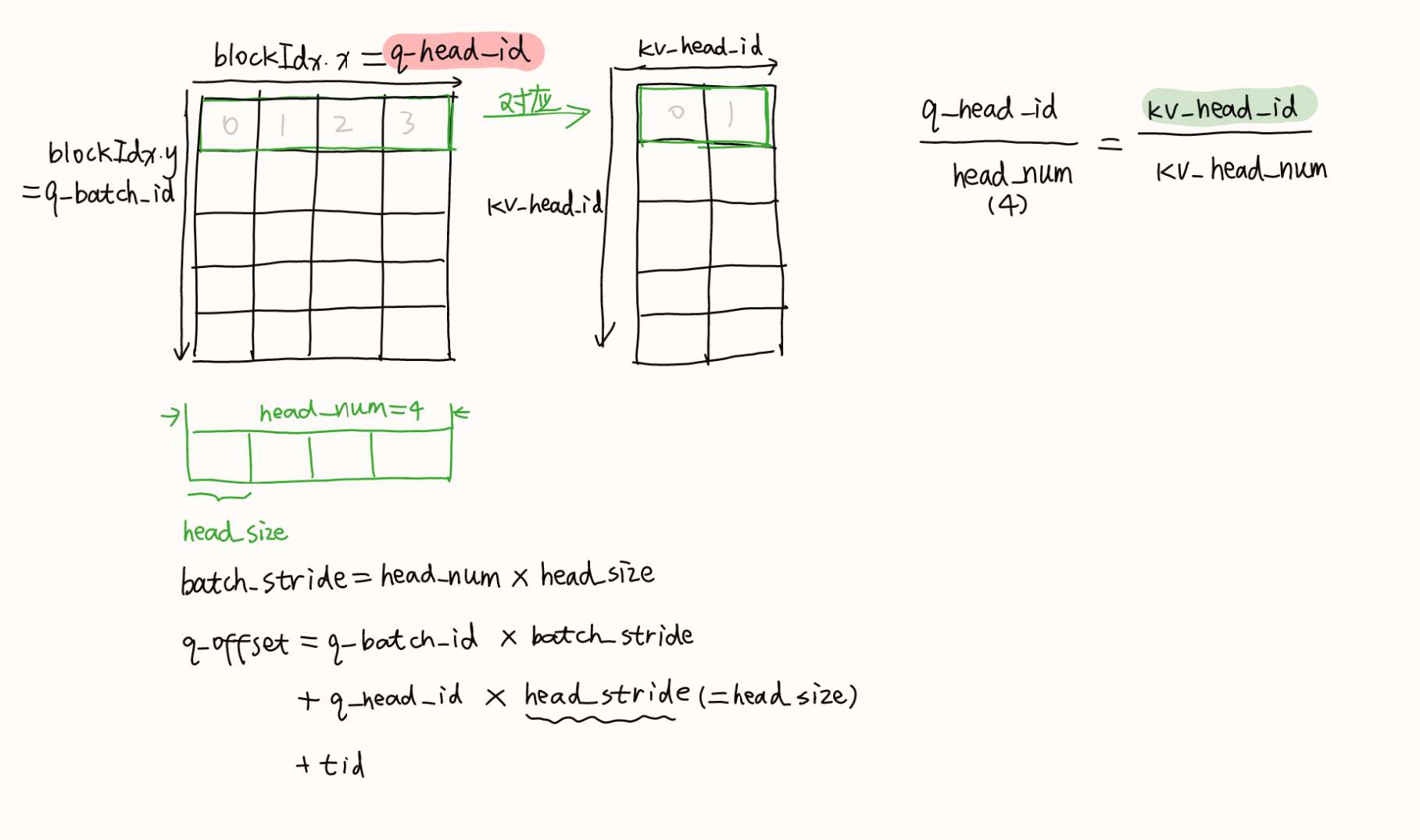
8.2 其他
using Vec_t = Vec<t>::type;和using Vec_t = typename Vec<t>::type;的区别
- 使用
typename关键字用来明确告诉编译器Vec<t>::type是一个类型而不是一个(静态)成员 - 不使用
typename的前提是编译器已经确定了Vec<t>::type是一个类型,不需要typename做提示// 需要typename做提示 template<typename T> struct Vec{ using Type = T; } // 不需要typename做提示 struct Vec{ using Type = int; }
const_cast主要用于移除(或添加)对象的const限定符,可以修改那些被声明为const的变量
Lesson9 concat past kv cache
讲解了:src/kernels/concat_past_kv.cusrc/kernels/concat_past_kv.htests/unittests/test_concat_kv.cu
llama中max_q_len(即seq_len)是8192,是关注对象;k和v写到max_q_len需要根据history_len找到相应的位置kv cache shape = [num layers, bs, kv_head_num, max_seq_len, head_size]
↓其中,max_seq_len的位置是写到[seqlen[history_len:history_len + max_q_len]]
这一节内容不多,但是折磨了我挺长时间的T.T
主要是max_q_len、max_seq_len、history_len、cur_query_len这几个变量没弄明白(可能是视频默认我会吧哈哈)
max_q_len:做完旋转之后的k、v的对应的每个batch的长度,即token的个数max_seq_len:考虑上下文的每个batch的长度,即token的长度,什么叫考虑上下文呢,就是入参的时候会输入history_len的就是上文长度,max_seq_len作为该batch的最长的长度history_len:这个batch中的上文长度,即token的长度cur_query_len:需要进行查询的长度(新生成的token的长度)history_len + cur_query_len <= max_seq_len
难点就是写入的位置的偏移dst_offset,实际上这一节也是要解决的问题就是kv cache的写入位置,结合代码看下图就好了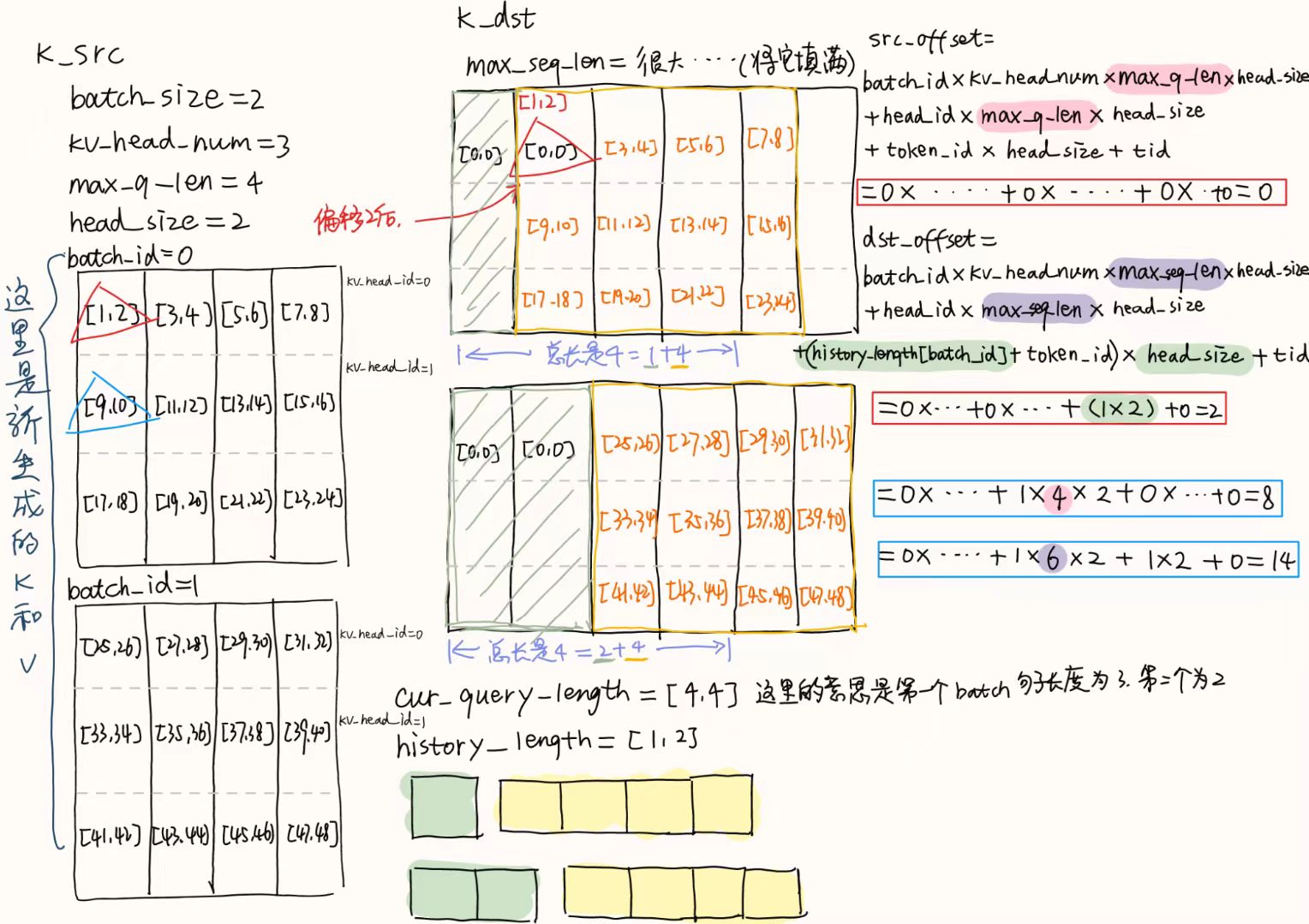
👆当layer=1的情况
👇这里只放key的,value的和他差不多
template <typename T>
__global__ void append_key_cache(T *k_dst, // [num layers, bs, kv head num, max_q_len, head size]
const size_t layer_offset,
const T *k_src, // [bs, kv_head num, max_q_len, head size]
const int kv_head_num,
const int head_size,
const int *cur_query_length,
const int *history_length,// [batch_size]
const int max_q_len,
const int max_seq_len){
// 根据这里的dim3 grid(max_q_len, batch_size, kv_head_num);来写下面的三行
int batch_id = blockIdx.y;
int head_id = blockIdx.z;
int token_id = blockIdx.x;
int tid = threadIdx.x;
T* k_cache_dst = k_dst + layer_offset; // 将k写到当前的layer位置,算是一个定位;k_dst是所有k的起始位置
int cumsum_seq_len = history_length[batch_id]; // 当前batch在当前layer中累积的句子长度
int cur_seq_len = cur_query_length[batch_id];
if(token_id < cur_seq_len){
// [bs, kv_head_num, max_q_len, head size] => [bs, kv_head_num, max_seq_len[cumsum_seq_len:cumsum_seq_len + max_q_len], head_size]
// 在k_src上的偏移
int src_offset = batch_id * kv_head_num * max_q_len * head_size
+ head_id * max_q_len * head_size
+ token_id * head_size + tid;
// 需要写入的位置的偏移
int dst_offset = batch_id * kv_head_num * max_seq_len*head_size
+ head_id * max_seq_len * head_size
+ (cumsum_seq_len + token_id) * head_size + tid;
k_cache_dst[dst_offset] = k_src[src_offset]; // k_src是当前layer的,dst_offset需要加上
}
}Lesson10 RepeatKV for MQA&GQA kernel
讲解了:src/kernels/repeat_kv.cusrc/kernels/repeat_kv.htest/unittests/test_repeat_kv.cu
写这个kernel的动机:将MHA转换为MQA,目的是平衡推理速度和MHA所能达到的精度;因为k和v的数量与头数量成正比,所以要减小头的数量和size以减小带宽压力,同时因为后面要做QKgemm,因此要矩阵对齐
尺寸变化:[batch size, kv head num, max seq len, head size]=>[batch size, q head num, max k len, head size]
q_head_per_kv = head_num / kv_head_num,即每一组k head或v head对应多少组q head共用
dim3 grid((max_k_len * head_size + blockSize - 1) / blockSize, batch_size, head_num);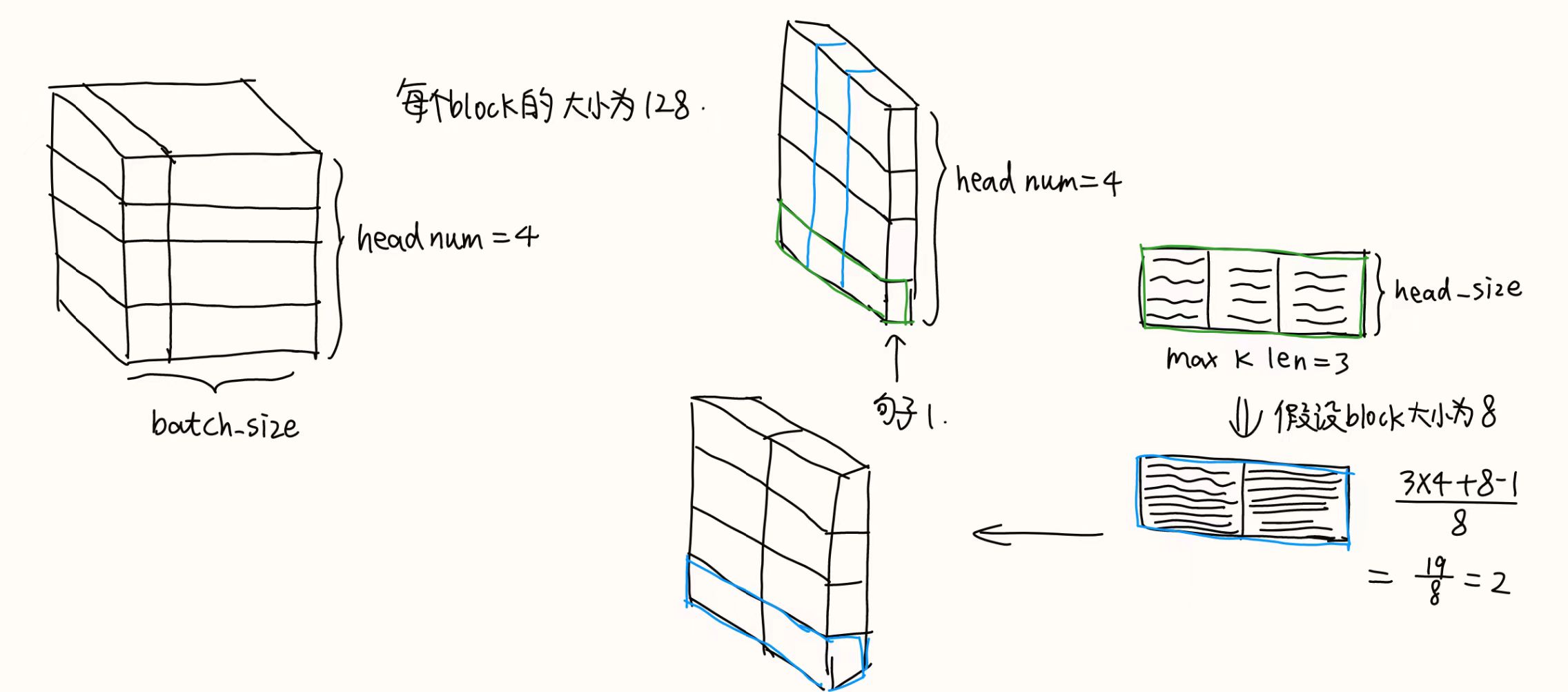
src/kernels/repeat_kv.cu
template <typename T>
__global__ void repeat_value_cache(T *v_dst,
const T *v_src,
const size_t layer_offset,
const int head_num,
const int q_head_per_kv,
const int head_size,
const int *context_length,
const int max_k_len,
const int max_seq_len){
const int batch_id = blockIdx.y;
const int head_id = blockIdx.z;
const int gtid = blockIdx.x * blockDim.x + threadId.x;
const auto val_src = v_src + layer_offset;
const T* val_dst = v_dst;
const int seq_len = context_length[batch_id];
const int v_head_size_id = gtid % head_size;
const int v_seq_len_id = gtid / head_size;
if(v_seq_len_id < seq_len){
const int src_id = batch_id * (head_num / q_head_per_kv)*
head_size * max_seq_len +
head_id / q_head_per_kv * head_size *
max_seq_len +
v_seq_len_id * head_size +
v_head_size_id;
const int dst_id = batch_id * head_num * head_size * max_k_len +
head_id * head_size * max_seq_len +
v_seq_len_id * head_size +
v_head_size_id;
val_dst[dst_id] = val_src[src_id];
}}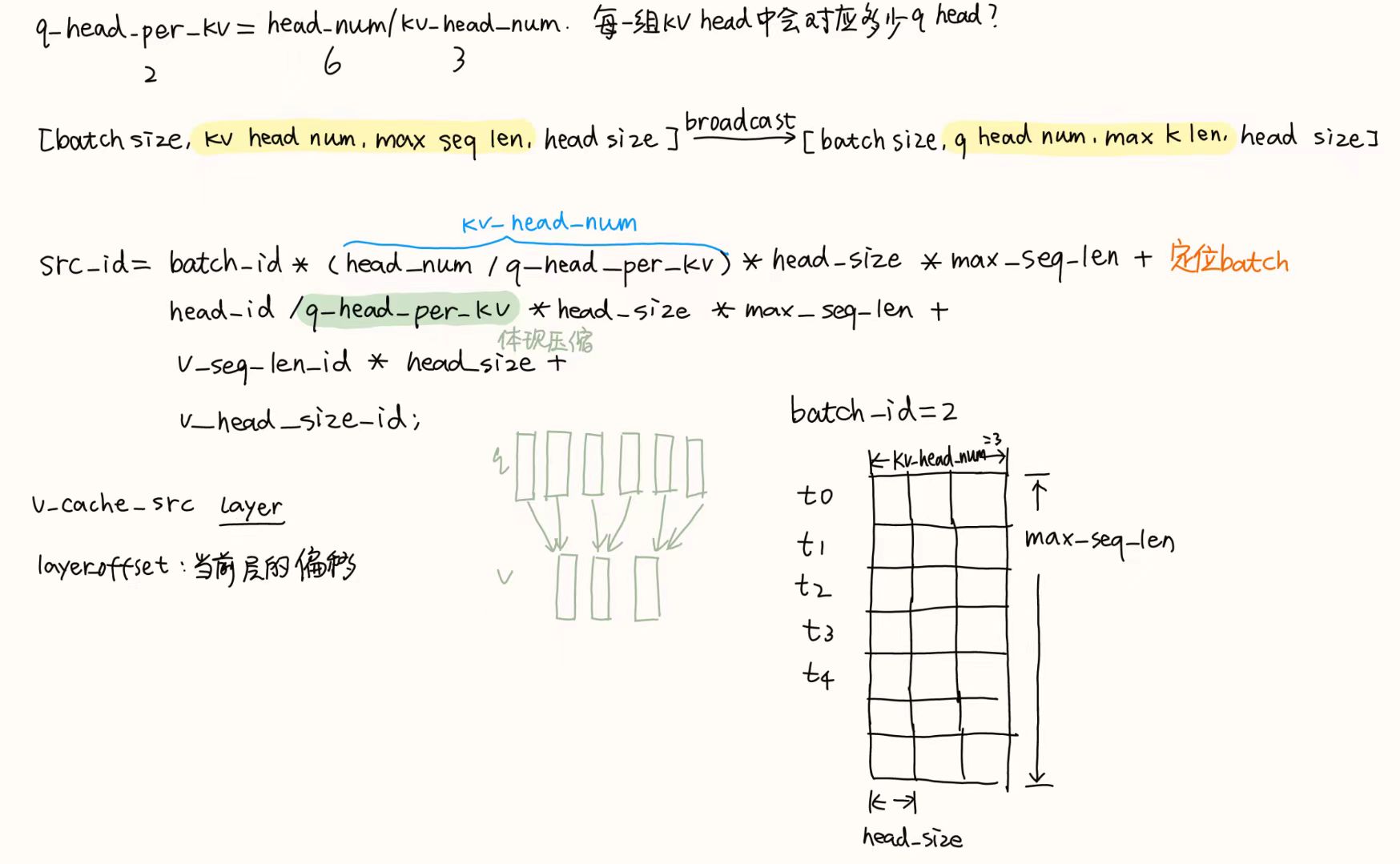
实际上就是按照
q head的大小重新排布了k head或v head,使他们一一对应。(图中绿色部分为对应关系,每q_head_num/kv_head_num组q head共用一组k head或v head)
总觉得这里的max_k_len有点误导人…应该不是kv head num * max seq len = q head num * max k len,只是单纯的扩展了
Lesson11 Fused mask&softmax
讲解了:src/kernels/attn_softmax_kernel.cusrc/kernels/attn_softmax_kernel.h
SumOp和MaxOp的定义
template <typename T>
struct SumOp
{
__device__ __forceinline__ T operator()(const T &a, const T &b) const { return a + b; }
};
template <typename T>
struct MaxOp
{
__device__ __forceinline__ T operator()(const T &a, const T &b) const { return max(a, b); }
};👆这样写的目的是模板化
template <template <typename> class ReductionOp, typename T>
__inline__ __device__ T warpReduce(T val)
{
for (int mask = 32 / 2; mask > 0; mask /= 2)
{
val = ReductionOp<T>()(val, __shfl_xor_sync(0xffffffff, val, mask));
}
return val;
}👆使用模板模板参数ReductionOp,在调用warpReduce时传入不同的操作类型SumOp和MaxOp
LLM-CHECK_WITH_INFO(k_length % 2 == 0, "K_len should be divided by 2 under half type!");fp32类型下以float4力度读写(还未实现),fp16类型下以half2读写,这里是只对fp16做向量化使其vec_size=2,而fp32向量化后vec_size=1
#define LAUNCH_SOFTMAX(dtype, vec_size) \
if (block.x > 2048 && block.x <= 4096) \
{ \
constexpr int NUMS_PER_THREAD_PER_ROW = 4; \
block.x /= 4 * vec_size; \
block.x = (block.x + 32 - 1) / 32 * 32; \
assert(block.x < 1024); \
ScaleMaskAndSoftmax_##dtype<dtype, NUMS_PER_THREAD_PER_ROW> \<<<grid, block>>>((dtype *)attn_score->data, \ (dtype *)qk->data, \
(dtype *)mask->data, \ batch_size, \ head_nums, \ q_length, \ k_length, \
scale); \
}NUMS_PER_THREAD_PER_ROW作为编译器常量- 如果当前输入的shape比较大,每个线程只访问4个vec,即
.x、.y、.z、.w这种,所以block.x被分为4*vec_size份- 其中,
vec_size对于half来说取2,对于float来说取1
- 其中,
- 同时block个数仍需对齐32,向上取整
- 整体看来就是用较少的线程处理数据,如果输入shape太大就采用输入向量化(目前只实现了fp16)并且减少线程使用
template <typename T, int NUMS_PER_THREAD_PER_ROW>
__global__ void ScaleMaskAndSoftmax_float(T *attn_score,
T *qk,
T *mask,
int batch_size,
int head_nums,
int q_len,
int k_len,
float scale){
int batch_id = blockIdx.y;
int head_id = blockIdx.z;
if(threadIdx.x >= k_len){
return;
}
__shared__ float s_max, inv_sum;
for(int row_start = 0; row_start < q_len; row_start++){
int qk_offset = 0;
T qk_data = static_cast<T>(0);
T mask_data = static_cast<T>(0);
T data[NUMS_PER_THREAD_PER_ROW];
T thread_max = FIL_MIN; - 在launch中
- grid=
[q_length, batch_size, head_nums] - block=
[k_length(以32的倍数向上取整)]
- grid=
- 开始处理所有行
以下全都在上一层的for的内部,为便于看代码因此忽略部分缩进
for (int col_start = 0; col_start < NUMS_PER_THREAD_PER_ROW; col_start++){
// 每个线程只需要处理NUMS_PER_THREAD_PER_ROW个数据
qk_offset = batch_id * head_nums * q_len * k_len +
head_id * q_len * k_len + row_start * k_len +
col_start * blockDim.x + threadIdx.x;
qk_data = qk[qk_offset];
mask_offset = batch_id * q_len * k_len + head_id * q_len * k_len
+ row_start * k_len + col_start * blockDim.x
+ threadIdx.x;
mask_data = mask[mask_offset];
data[col_start] = scale * qk_data + (1 - mask_data) * -1e4f;
thread_max = fmax(data[col_start], thread_max); // 一个线程对多个元素做处理之后,多个元素的最大值
}
T max_val = blockReduce<MaxOp, T>(thread_max); // 一行的最大值
// block的最大值存在id为0的线程中
if(threadIdx.x == 0){
s_max = max_val;
}
__syncthreads(); - 列被分为
NUMS_PER_THREAD_PER_ROW个数据由同一个线程处理 - 每遍历一次
col_start就会有相应的线程并行,之后再用blockReduce进行最后的规约 mask_data和qk_data不同的地方是没有head_nums,其他都一致- 如果
mask_data=1,说明不需要被mask,反之需要被mask(加上$-10^4$,这使得在softmax时得到的值非常的小)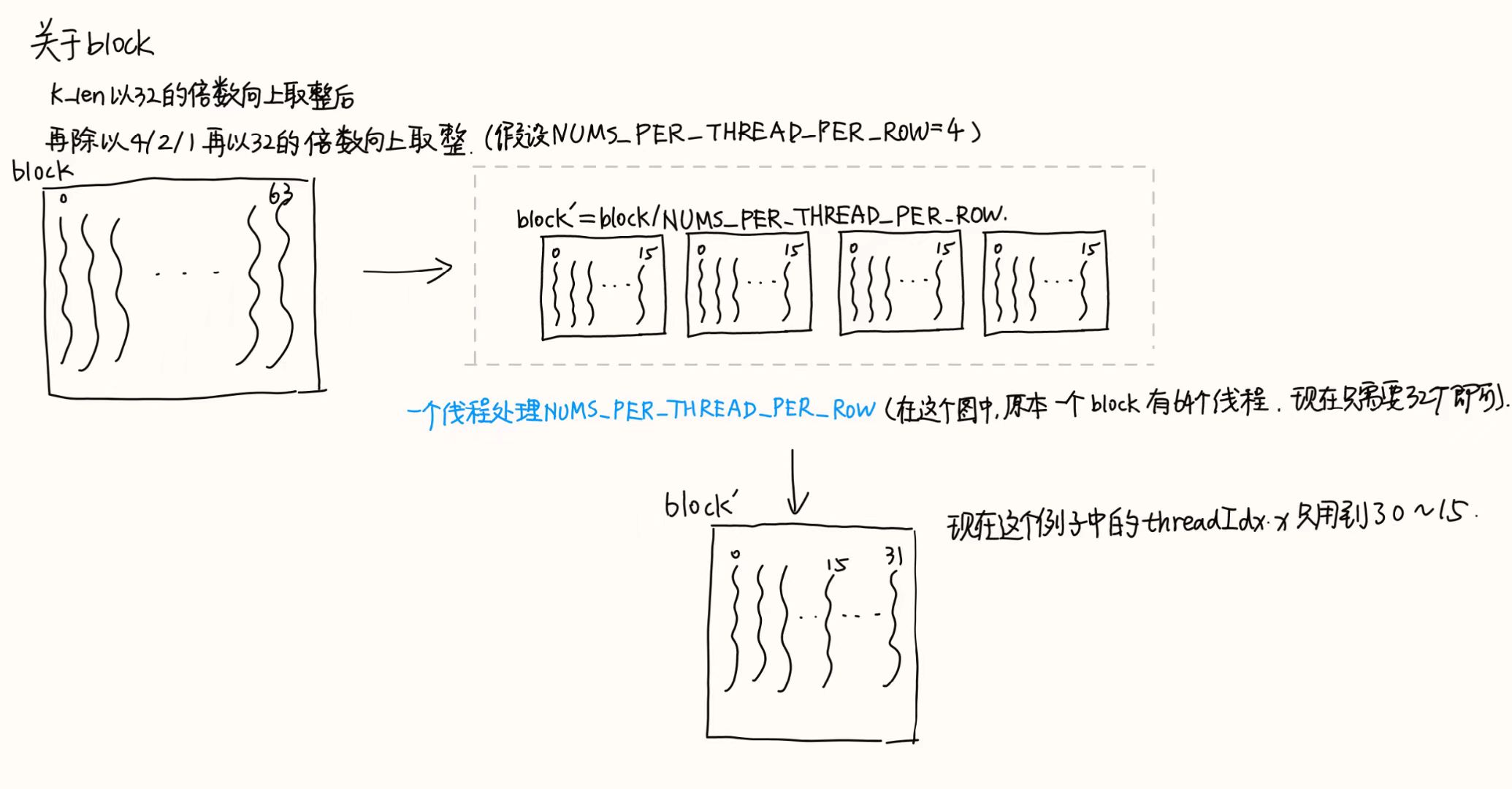
考虑到数值范围的溢出问题,一般会在指数部分减去D=max(zi)
softmax的公式为:$D=max(z_i),softmax(z_i)=\dfrac{e^{z_i-D}}{\sum^C_{c=1}e^{z_c-D}}$T thread_sum = 0.0f; for(int col_start = 0; col_start < NUMS_PER_THREAD_PER_ROW; col_start++){ data[col_start] = expf(data[col_start] - s_max); thread_sum += data[col_start]; } T sum_val = blockReduce<SumOp, T>(thread_sum); if(threadIdx.x == 0){ inv_sum = 1 / (sum_val + 1e-6); } __syncthreads(); for(int col_start = 0; col_start < NUMS_PER_THREAD_PER_ROWl;col_start++) { qk_offset = batch_id * head_nums * q_len * k_len + head_id * q_len * k_len + row_start * k_len + col_start * blockDim.x + threadIdx.x; attn_score[qk_offset] = (data[col_start] * inv_sum); }
- 如果
对于fp16,不同的地方在于向量化处理
//scalar_cast_vec: 将常量转换为2个或4个向量
Vec_t ONE = scalar_cast_vec<Vec_t>(__float2half(1.0f));
Vec_t NEG_INF = scalar_cast_vec<Vec_t>(__float2half(-10000.0f));
Vec_t scale_vec = scalar_cast_vec<Vec_t>(__float2half(scale));根据
src/utils/vectorze_utils.h:half->half2 ,float->float4
在src/utils/vectorize_utils.h
template<typename T_OUT, typename T_IN>
inline __decvice__ T_OUT scalar_cast_vec(T_IN val){
return val;
}
// half转为half2
template<>
inline __device__ half2 scaler_cast_vec<half2, half>(half val){
return __half2half2(val);
}
// float转为float2
template<>
inline __device__ float2 scaler_cast_vec<float2, float>(float val){
return __make_float2(val, val);
}
// float转为float4
template<>
inline __device__ float4 scaler_cast_vec<float4, float>(float val){
return __make_float4(val, val, val, val);
}
// float转为half2
template<>
inline __device__ float2 scaler_cast_vec<half2, float>(float val){
return __float2half2_rn(val);
}还有一部分直接用库中half2函数进行计算处理
Lesson12 Fused transpose&remove padding
讲解了:src/kernels/fused_transpose_and_remv_pad.cusrc/kernels/fused_transpose_and_remv_pad.h
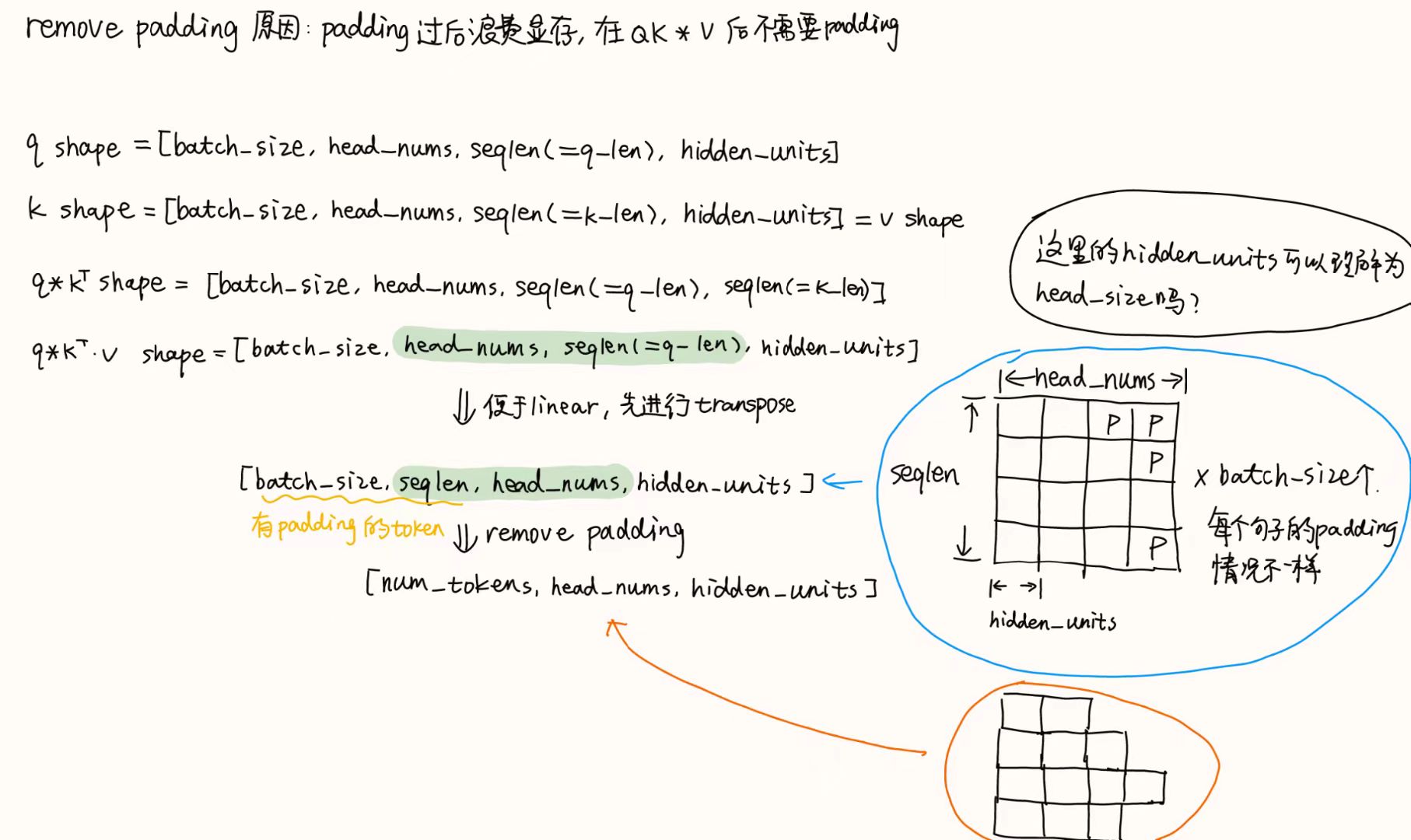
template <typename T>
__global__ void fused_transpose_reshape_remv_pad(T *src,
T *dst,
const int num_tokens,
const int batch_size,
const int seq_len,
const int head_num,
const int head_size,
const int *padding_offset /*for remove padding*/)
{
int token_id = blockIdx.x; // 这里的token_id是指padding之前的每个token的id
int batch_id = token_id + padding_offset[token_id] / seq_len; // 这里的batch_id是指padding之后每个token对应的batch的id
int seq_id = token_id + padding_offset[token_id] % seq_len; // 每个token在句子中的编号,范围是0~seq_len-1
// transpose前后的offset
int src_offset = batch_id * head_num * seq_len * head_size + seq_id * head_size; // transpose前的偏移位置,具体到head_size的偏移,这里把head_id * seq_len * head_size去掉了,会在for循环补上
int dst_offset = token_id * head_num * head_size; // 这里的偏移只具体到token
for(int i = threadIdx.x; i < head_num * head_size; i+=blockDim.x){ // 因为每个block处理一个token,所以i+=blockDim.x
int head_id = i / head_size;
int head_size_id = i % head_size;
dst[dst_offset + i] = src[src_offset + i * seq_len * head_size + head_size_id];
}
}代码比较容易理解,不懂的看注释即可
Lesson13 Fused addResidualNorm
讲解了:src/fused_addresidual_norm.cusrc/fused_addresidual_norm.h
template<typename T>
__global__ void FusedAddBiasResidualRMSNorm( // residual.shape = [num tokens, hidden_units]
T* residual, // [num tokens, hidden_units]
T* decoder_in, // [num tokens, hidden_units]
/*optional*/const T* bias, // [hidden_units]
const T* scale, // [hidden_units], RMSNorm weights
float eps, // RMSNorm eps
int num_tokens,
int hidden_units){ rmsnorm(decoder_in + residual + bias)
// grid:[num_tokens] block:[num_threads] int vec_size = Vec<T>::size;
using Vec_t = typename Vec<T>::Type;
int batch_id = blockIdx.x; // 一个block表示一个batch
int tid = threadIdx.x;
Vec_t *de_out = reinterpret_cast<Vec_t*>(decoder_in + batch_id * hidden_units);
Vec_t *rsd = reinterpret_cast<Vec_t*>(residual + batch_id * hidden_units);
Vec_t *bia;
if(bias != nullptr){
bia = reinterpret_cast<Vec_t*>(bias);
} Vec_t tmp;
T thread_sum = static_cast<T>(0.0f);
for (int i = threadIdx.x; i < hidden_units / vec_size; i += blockDim.x) {
if(residual != nullptr){
// 下面对应HF中的hidden_states = residual + hidden_states
de_out[i].x += rsd[i].x;
de_out[i].y += rsd[i].y;
de_out[i].z += rsd[i].z;
de_out[i].w += rsd[i].w;
// 下面对应residul = hidden_states
rsd[i].x = de_out[i].x;
rsd[i].y = de_out[i].y;
rsd[i].z = de_out[i].z;
rsd[i].w = de_out[i].w;
}
if(bias != nullptr){
de_out[i].x += bia[i].x;
de_out[i].y += bia[i].y;
de_out[i].z += bia[i].z;
de_out[i].w += bia[i].w;
}
thread_sum += de_out[i].x * de_out[i].x;
thread_sum += de_out[i].y * de_out[i].y;
thread_sum += de_out[i].z * de_out[i].z;
thread_sum += de_out[i].w * de_out[i].w;
}
Vec_t *de_out = reinterpret_cast<Vec_t*>(decoder_in + batch_id * hidden_units):每个block表示一个token,每个token的大小为hidden_units,这里表示了当前token的偏移量- 在HF中的顺序
hidden_states = residual + hidden_states对应de_out[i].x += rsd[i].x;residul = hidden_states对应rsd[i].x = de_out[i].x;hidden_states = self.post_attention_layernorm(hidden_states)对应de_out[idx].x = de_out[idx].x * inv_mean * s[idx].x; - 根据公式$\dfrac{x_i×g_i}{\sqrt{\sum^iE(x_i^2)+eps}}$
- $x_i$对应加了
residual的de_out[i] - $g_i$对应
s[idx]
- $x_i$对应加了
// 求分母,以1/xxx表示
T block_sum = blockReduceSum<float>(thread_sum);
__shared__ float inv_mean;
if (threadIdx.x == 0) {
inv_mean = rsqrtf(block_sum / hidden_units + eps);
} __syncthreads();
// rmsnorm
Vec_t *s;
if(scale != nullptr) {
s = reinterpret_cast<Vec_t *>(scale);
}
for (int idx = threadIdx.x; idx < hidden_units / vec_size; idx += blockDim.x) {
de_out[idx].x = de_out[idx].x * inv_mean * s[idx].x;
de_out[idx].y = de_out[idx].y * inv_mean * s[idx].y;
de_out[idx].z = de_out[idx].z * inv_mean * s[idx].z;
de_out[idx].w = de_out[idx].w * inv_mean * s[idx].w;
}
}Lesson 14 Gate Linear&Up Linear
讲解了:src/kernels/linear
输入:
为context decoder时,[batch_size, q hidden units];
为self decoder时,[token nums, q hidden units]
Gate&Up权重:[q hidden units, 2 * inter size]
输出:[batch_size(或token nums), 2 * inter size] = [bs/tn, 2, inter size],实际上输出是三维
Lesson 15 SwiGLU
讲解了:src/kernels/act_kernel.hsrc/kernels/act_kernel.cu
SiLU(Sigmoid Linear Unit),相对于ReLU,SiLU在函数接近0时具有更平滑的曲线
$y=x*sigmoid(\beta x)=\dfrac{1}{1+e^{-\beta x}}$,当$\beta=1$时就是SiLU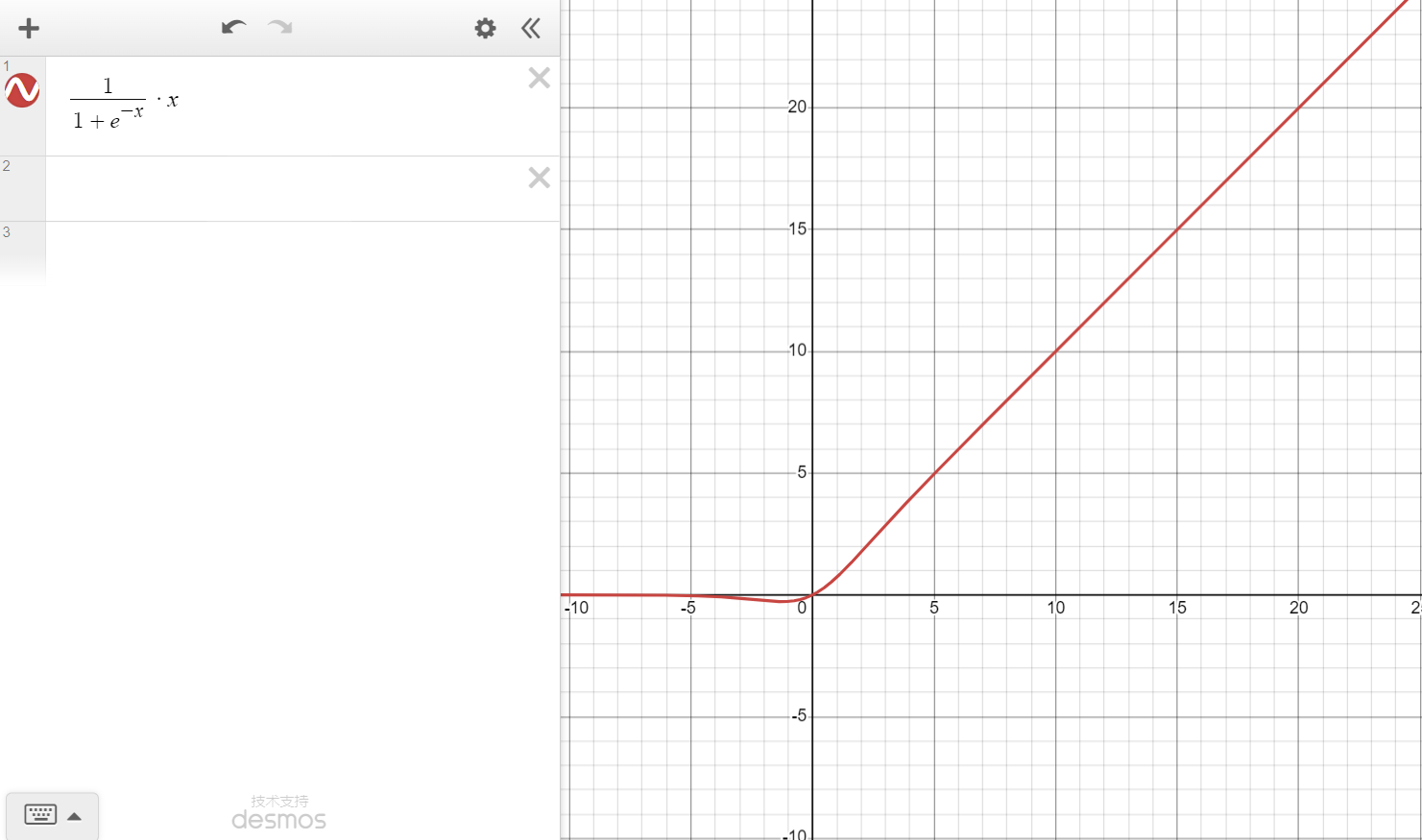
template<typename T>
__device__ __forceinline__ T silu(const T& in){
return in / (1.0f * expf(-in));
}grid:[batch_size=input->shape[0]]block:[256]
Gate Linear和Up Linear的输出(对于context decoder而言)[bs, 2, inter size]可以视为两个大小为[bs, inter size]的部分,第一部分做SiLU,得到的结果与第二部分做mul最终得到最后的结果
template<typename T>
__global__ void silu_and_mul_kernel(
T* out, // shape: [bs, intermedia size]
const T* input, // shape: [bs, 2, intermedia size]
const int intermedia_size) {
const int batch_idx = blockIdx.x;
for(int idx = threadIdx.x; idx < intermedia_size; idx +=blockDim.x){
const T x = input[batch_idx * 2 * intermedia_size + idx];// 第一个
const T y = input[batch_idx * 2 * intermedia_size + intermedia_size + idx]; // 第二个
out[batch_idx * intermedia_size + idx] = silu<T>(x) * y;
}
}Lesson16 Fused SelfDecoderAttention kernel
讲解了:src/fused_decoder_self_attention.cu
融合部分:concat kv+repeat kv+qk gemv+softmax+qk*v gemv
- 如何fuse:数据在寄存器(如
q、k和v)和显存(如q_buf、k_buf和v_buf)都出现,因此需要复用在寄存器和共享内存中的数据,因为访问显存会耗时,并且带宽很低 - 使用动态共享内存
Q*k Gemv:q.shape=[batch size, head num, 1, head size]- 这里的
1表示每次针对一个特定位置(当前token)计算attention
- 这里的
k.shape=[batch size, head num, step, head size],- 这里不是
kv head num,是因为在repeat kv这一步中已经把q和k的头对齐了 - 这里的
step表示每个句子包含step个token,每个token的key都与当前查询向量q做点积
- 这里不是
重温:
- qkv矩阵的shape
- q
[batch size, q head num, 1, head size] - k
[batch size, kv head num, step(/seqlen), head size] - v
[batch size, kv head num, step(/seqlen), head size]
- q
launchDecoderMaskedMHA()
qkv_buf:[batch size, qkv head num, head size],默认head_num是q的head,qkv、kv的head会加上相应的前缀- 用
getVal的前提是数据必须在CPU上(LLM_CHECK(location == CPU)) - grid:
[head_num, batch_size] - block:
[head_size]
入参:
template<typename T>
void launchDecoderMaskedMHA(TensorWrapper<T>* qkv_buf,
BaseWeight<T>& qkv,
TensorWrapper<int>* layer_id,
TensorWrapper<T>* k_cache,
TensorWrapper<T>* v_cache,
TensorWrapper<bool>* finished,
TensorWrapper<int>* step,
TensorWrapper<T>* mha_output,
LLaMAAttentionStaticParams& static_params){ qkv_buf=qkv_linear=[bs, q_hidden_units] * [qhiddenunits, hiddenunits] = [bs, qkv_head_num, head_size]qhiddenunits:将输入的嵌入向量(embedding vector)的向量长度,hiddenunits:=[qkv_head_num,qiddenunist]=[qkv_head_num,head_size]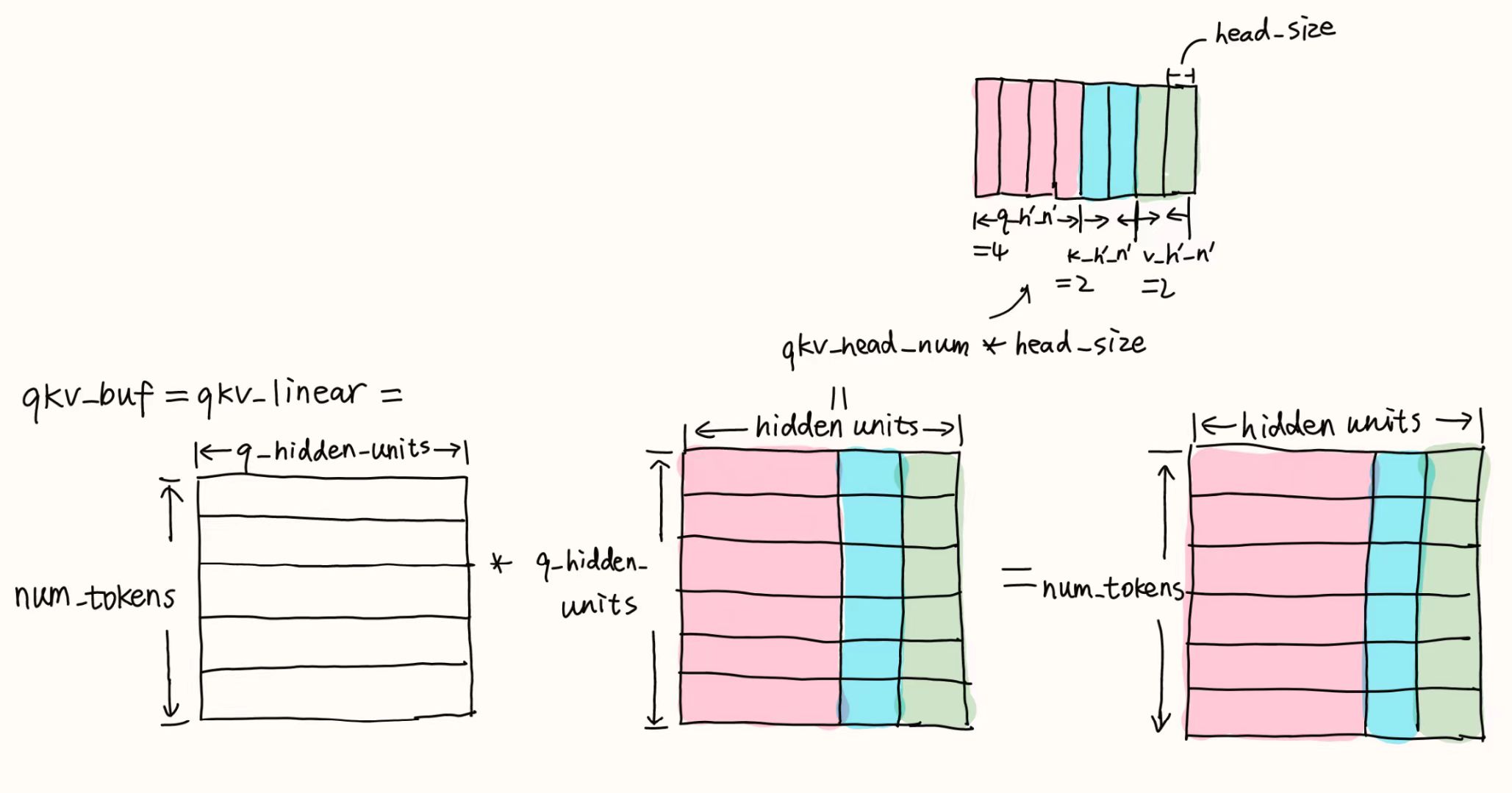
- kv的cache
- k_cache
[num layers, bs, kv head num, max seq len or step, head size] - v_cache
[num layers, bs, kv head num, max seq len or step, head size]const int qkv_head_num = qkv_buf->shape[1]; const int kv_head_num = k_cache->shape[2]; const int max_seq_len = k_cache->shape[3]; int head_num = qkv_head_num - 2 * kv_head_num; const int head_size = qkv_buf->shape[2]; const int cur_step = step->getVal(); const int layer = layer_id->getVal(); const int layer_offset = layer * max_seq_len * batch_size * kv_head_num * head_size; size_t smem_size_bytes = head_size * sizeof(T) + cur_step * sizeof(float); T* qkv_data = qkv_buf->data; T* q = qkv_data; T* k = qkv_data + head_num * head_size; T* v = qkv_data + (head_num + kv_head_num) * head_size; int rotary_embedding_dim = static_params.rotary_embedding_dim; float rotary_embedding_base = static_params.rotary_embedding_base; int max_position_embeddings = static_params.max_position_embeddings; bool use_dynamic_ntk = static_params.use_dynamic_ntk; dim3 grid(head_num, batch_size); dim3 block(head_size); //vec size = 4 for fp32 masked_MHA_kernel<T><<<grid, block, smem_size_bytes>>>( q, k, v, // /*(T*)*/qkv.bias, k_cache->data + layer_offset, v_cache->data + layer_offset, mha_output->data, batch_size, head_num, kv_head_num, max_seq_len, head_size, cur_step, rotary_embedding_dim, rotary_embedding_base);
- k_cache
q、k、v:qkv_buf=[bs, qkv_head_num, head_size],q、k、v分别加上相应偏移量k_cache、v_cache:定位到某一个layer上,不考虑layer时的shape为[bs, kv head num, max seq len or step, head size]mha_output->data:作为输出地址cur_step:当前时间步,当前生成到第几个tokenrotary_embedding_dim、rotary_embedding_base:RoPE用
masked_MHA_kernel()
入参:
template<typename T>
__global__ void masked_MHA_kernel(const T* q,
const T* k,
const T* v,
T* qkv_bias,
T* k_cache,
T* v_cache,
T* mha_output,
const int batch_size,
const int head_num,
const int kv_head_num,
const int max_seq_len,
const int head_size,
const int step,
int rotary_embedding_dim,
float rotary_embedding_base){// rsqrt(dh) k_offset和cache_offset区别:k_offset是qkv linear提供给k的,(因为是self_attention所以)一个batch只有一个tokencache_offset是kv cache提供给k的,有max seq len,一个batch最多有max seq len个token(有这么多是因为新生成的token的k、v也加上去了)
- 以
tid * vec_size < head_size作为是否超出边界的判断head_size一般是4、8、16的倍数,所以当vec_size为2或4时也能正常判断- (抛开倍数问题会觉得不能正常判断的原因是:
head_size=7,当tid(=1)*vec_size(=4)时,4<7此时判断未超出边界,但是一共有2×4=8已经超出边界了)
- 输出:`mha_output.shape=[batch_size, q_head_num, 1, head_size]
①ConcatPastKVCacheinput=[bs, kv head num, seqlen, head size]output=[bs, kv head num, max_seq_len, head size]
int tid = threadIdx.x;
int q_head_id = blockIdx.x;
int q_batch_id = blockIdx.y;
int kv_head_id = q_head_id / (head_num / kv_head_num);
int kv_batch_id = q_batch_id;
int batch_stride = head_num * head_size;
int kv_batch_stride = kv_head_num * head_size;
int head_stride = head_size;
int q_offset = q_batch_id * batch_size + q_head_id * head_stride + tid;
// k_offset是qkv linear提供给k的
int k_offset = kv_batch_id * kv_batch_stride + kv_head_id * head_stride + tid;
// cache_offset是kv cache提供给k的
int cache_offset = kv_batch_id*kv_head_num*max_seq_len*head_size
+ kv_head_id * max_seq_len * head_size
+ tid * vec_size;//没有seq len的维度是因为seq len始终为1
int step_stride = head_size;
float scale = rsqrt((float)head_size);
int vec_size = Vec<T>::size;
int q_offset_vec = q_batch_id * batch_size + q_head_id * head_stride + tid * vec_size;
int k_offset_vec = kv_batch_id * kv_batch_stride + kv_head_id * head_stride + tid * vec_size;
using Vec_t = typename Vec<T>::Type; ②声明动态共享内存变量
const T* q_mem = q;
const T* k_mem = k;
const T* v_mem = v;
if(tid * vec_size < head_size){
qvec = *reinterpret_cast<Vec_t*>(const_cast<T*>(&q_mem[q_offset_vec]));
kvec = *reinterpret_cast<Vec_t*>(const_cast<T*>(&k_mem[k_offset_vec]));
vvec = *reinterpret_cast<Vec_t*>(const_cast<T*>(&v_mem[v_offset_vec]));
}
extern __shared__ char sqk[]; // 声明动态共享内存变量
// shared memory的分配
// 存到shared memory中的数据的特点是低延迟、高复用
// 在这里对q用shared memory进行存储是因为之后有个优化,使用一个block取多行k进行qk gemm,此时q的复用频率变高,不需要重复加载q
T* sq_scalar = reinterpret_cast<T*>(sqk);
float* logits = reinterpret_cast<float*>(sq_scalar + head_size);
Vec_t *sq = reinterpret_cast<Vec_t*>(sq_scalar);
if(tid * vec_size < head_size){
sq[tid] = qvec;
} __syncthreads();
float zero = 0.0f;
Vec_t zero_f4 = scalar_cast_vec<Vec_t, T>(zero); // 将float转为float4
float4 scale_f4 = scalar_cast_vec<float4, float>(scale);
// q*k gemv
for(int iter = 0; iter < step; iter++){ //一个block循环计算step行
Vec_t kvec_qk = tid * vec_size < head_size ? *reinterpret_cast<Vec_t*>(&k_cache[iter * step_stride + cache_offset]) : zero_f4; // 这里乘iter相当于乘max seq len。我的理解是cache_offset是对于token而言的,iter*cache_offset的偏移使定位到当前step(当前token)
if(iter == step - 1 && tid * vec_size < head_size){ // step的最后一个位置存储RoPE输出的k
*reinterpret_cast<Vec_t*>(&k_cache[iter * step_stride + cache_offset]) = kvec;
kvec_qk = kvec; // 这里的kvec_qk是用来做计算的,下面的vvec_qkc同理
}
Vec_t qk = zero_f4;
qk.x = tid * vec_size < head_size ? sq[tid].x * kvec_qk.x * scale_f4.x : zero;
qk.y = tid * vec_size < head_size ? sq[tid].y * kvec_qk.y * scale_f4.y : zero;
qk.z = tid * vec_size < head_size ? sq[tid].z * kvec_qk.z * scale_f4.z : zero;
qk.w = tid * vec_size < head_size ? sq[tid].w * kvec_qk.w * scale_f4.w : zero;
T qk_acc = qk.x + qk.y + qk.z + qk.w; // 一个线程有4个值,先在线程局部把这四个值加起来,再用blockReduceSum
T attn_score = blockReduceSum<T>(qk_acc);
if(tid == 0){
logits[iter] = attn_score; // logits是step×1大小的数组
}
__syncthreads();
}
// softmax T local_logits = tid < step ? (T)logits[tid] : 0;
__shared__ float row_max, fenmu;
T block_max = blockReduceMax<T>(local_logits);
if(tid == 0){
row_max = block_max;
} __syncthreads();
T fenzi = tid < step ? expf(logits[tid] - row_max) : 0; // e(x_i - x-max) / sigma(e(x_i, x_max));
T block_fenmu = blockReduceSum<T>(fenzi);
if(tid == 0){
fenmu = block_fenmu + 1e-6;
} __syncthreads();
if(tid < step){
logits[tid] = (T)(fenzi / fenmu);
} __syncthreads();
// 隐式的repeat kv,都是向量化类型
if(tid * vec_size < head_size){
Vec_t O = scalar_cast_vec<Vec_t, T>(0.0f); // 中间寄存器
for(int iter = 0; iter < step; iter++){
Vec_t vvec_qkv = *reinterpret_cast<Vec_t*>(&v_cache[iter * step_stride + cache_offset]);
if(iter == step - 1){ // step的最后一个位置存储RoPE输出的k
*reinterpret_cast<Vec_t*>(&v_cache[iter * step_stride + cache_offset]) = vvec;
vvec_qkv = vvec;
} __syncthreads();
O.x += vvec_qkv.x * logits[iter]; // v的一整行×qk的一个
O.y += vvec_qkv.y * logits[iter]; // v的一整行×qk的一个
O.z += vvec_qkv.z * logits[iter]; // v的一整行×qk的一个
O.w += vvec_qkv.w * logits[iter]; // v的一整行×qk的一个
}
*reinterpret_cast<Vec_t*>(&mha_output[q_offset]) = O; // [batch size, q head num, 1, head size]
}}Lesson17 topK
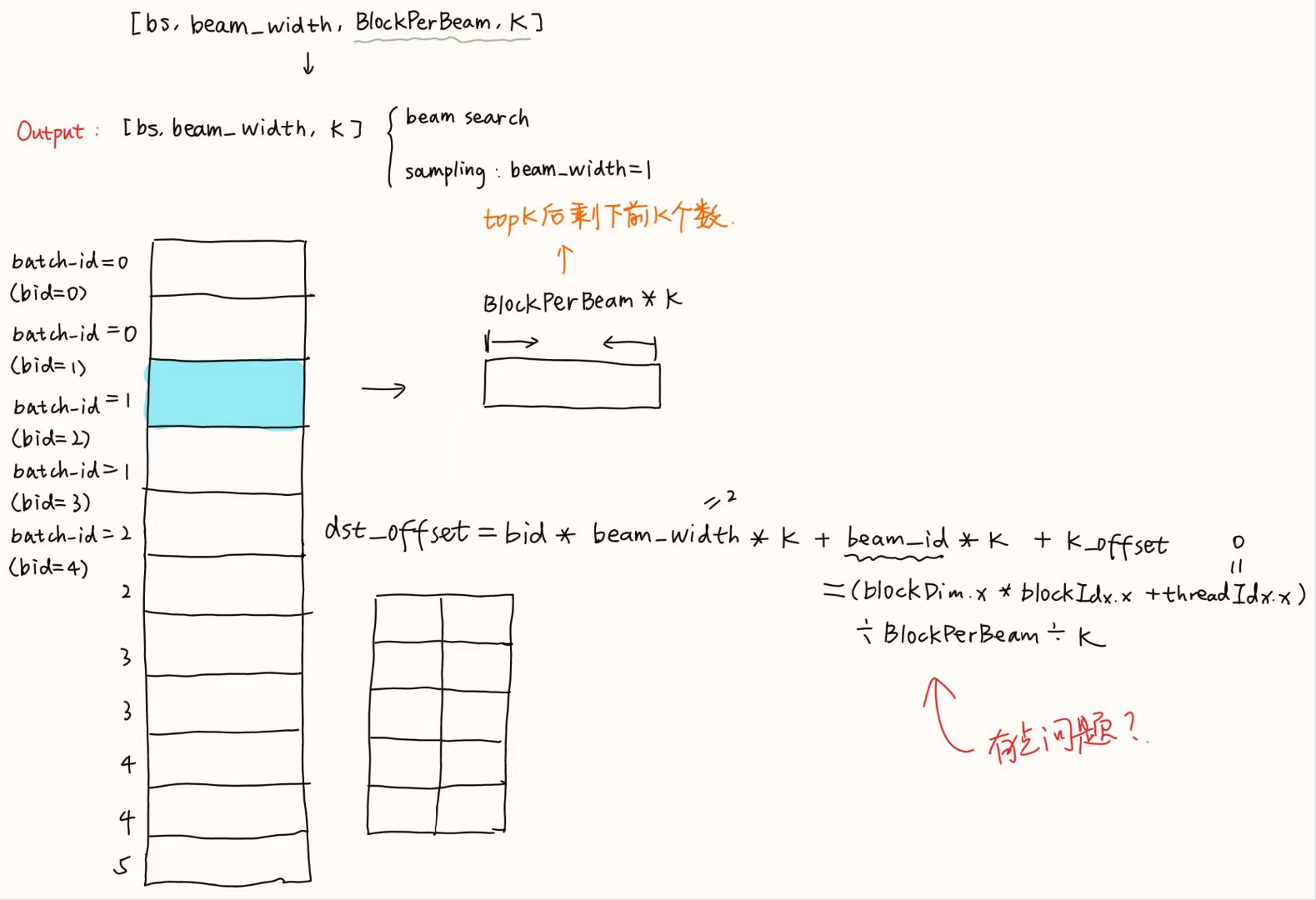
讲解了:src/kernels/topK.cusrc/kernels/topK.h
输入:[bs, beam_width, vocab size]
输出:[bs, beam_width, K]
topK中的K是从一组候选中选取得分最高的前K个值
beam_width是指保留的候选路径数
目的:每个vocab需要选择K个值作为topK
做法:由于vocab_size比较大,因此分成两次topK
- 第一次:
[bs, beamwidth, vocab size] => [bs, beamwidth, BlockPerBeam, K]- 将vocab分为
BlockPerBeam段,每段做topK选出前K个最大的值 - 第一次topK后每个vocab还有
BlockPerBeam * K个值 - grid:
[min(batch_size * BlockPerBeam, maxBlockNums)] - block:
[256]
- 将vocab分为
- 第二次:
[bs, beamwidth, BlockPerBeam, K] => [bs, beamwidth, K]- 将vocab剩下的
BlockPerBeam * K个值直接做topK得到K个值 - grid:
[min(batch_size, maxBlockNums)] - block:
[256]
- 将vocab剩下的
①topK的做法
template<typename T, int K>
struct topK{
// 下面这两行的访问权限是public,因为默认就是public所以不用显式地写出来
T val[K];
int id[L];
// 初始化topK中id全为-1,val全为最小值
__device__ void init(){
for(int i = 0; i < K; i++){
id[i] = -1;
val[i] = FLT_MIN;
}
}
// 如果当前输入的数字比最后一个数字大,则摒弃最后一个数字,将输入的数字排进来
void insertHeap(T data, int data_id){
if(id[K-1] == -1 || val[K-1] < data){
id[K-1] = data_id;
val[K-1] = data;
}
// 只需要对当前输入进来的做冒泡排序,因为每进来一个都做一次冒泡排序
for(int i = K-2; i >= 0; i--){
if(val[i + 1] > val[i]){
T tmp = val[i];
val[i] = val[i + 1];
val[i + 1] = tmp;
int tmp_id = id[i];
id[i] = id[i + 1];
id[i + 1] = tmp_id;
}
}
}
};②将两个topK做一次reduce输出为一个topK
template<typename T, int K>
__device__ topK<T, K> reduce_functor(const topK<T, K>& a, const topK<T, K>& b) {
topK<T, K> res = a;
for(int i = 0; i < K; i++){
res.insertHeap(b.val[i], b.id[i]);
}
return res;
}③第一次topK
template<typename T, int K, int blockSize, int BlockPerBeam>
__global__ void topK_kernel_round1(const T* probs,
const int vocab_size,
int* topK_ids,
T* topK_vals){
int tid = threadIdx.x;
int bid = blockIdx.x;
int row_id = bid / BlockPerBeam; // 哪一批vocab/哪一个batch中
int block_lane = bid % BlockPerBeam; // 同一批vocab中的哪一个段
topK<T, K> thread_topK; // 为每一个线程分配一个topK寄存器
thread_topK.init();
// 下面做thread层次的reduce
for(int data_id = tid + block_lane * blockSize; data_id < vocab_size; data_id += BlockPerBeam * blockSize){
int data_offset = data_id + row_id * vocab_size;
T data = probs[data_offset];
thread_topK.insertHeap(data, data_offset);
}
typedef cub::BlockReduce<topK<T, K>, blockSize> blockreduce;
__shared__ typename blockreduce::TempStorage tmp_storage;
topK<T, K> block_topk = blockreduce(tmp_storage).Reduce(thread_topK, reduce_functor<T, K>);
if(tid == 0){
for(int k_offset = 0; k_offset < K; k_offset++){
int dst_offset = row_id * BlockPerBeam * K +
block_lane * K +
k_offset;
topK_vals[dst_offset] = block_topk.val[k_offset];
topK_ids[dst_offset] = block_topk.id;
}
}
}入参:
probs:输入的概率值[bs, beamwidth, vocab size]topK_ids和topK_vals:作为输出
在未需要data+=BlockPerBeam*blockSize时,
- 每个batch中,
block_lane=0~7,tid=0~255 - 在不同batch中,
row_id不同 data_id+=BlockPerBeam*blockSize可以理解为当data_id是0~2047并且data_id仍未超出vocab_size时,在不变动tid和bid前提下,线程并行执行data+_id加上步长为BlockPerBeam*blockSize得到的新的data_id的行为。直到data_id超过vocab_size为止data_id可以理解为在某一vocab中的偏移量,加上row_id关于batch的偏移得到最终的偏移量data_offsetthread_topK:是每个线程都有自己的topKbid=0, tid=0:负责data_id为0、2048、4096的topKbid=7, tid=1:负责data_ia为1793、2561、4609的topK
typedef cub::BlockReduce<topK<T, K>, blockSize> blockreduce;
__shared__ typename blockreduce::TempStorage tmp_storage;
topK<T, K> block_topk = blockreduce(tmp_storage).Reduce(thread_topK, reduce_functor<T, K>); cub::BlockReduce是NVIDIA提供的CUB(CUDA UnBound)库中的一个模板类,目的是将线程块中的数据(由每个线程负责一部分)规约为单一结果template <typename T, int BLOCK_DIM> class cub::BlockReduce { public: using TempStorage = typename ImplementationDefined; BlockReduce(TempStorage& temp_storage); T Reduce(T input, ReduceOp reduce_op); };tmp_storage:供线程块中的线程通信和归约使用block_topk:合并每个线程块中的线程的topK,得到每个线程块的topK
最后每个block只使用第一个线程做转移,将block_topk个数据转移到topK_vals和topK_ids中。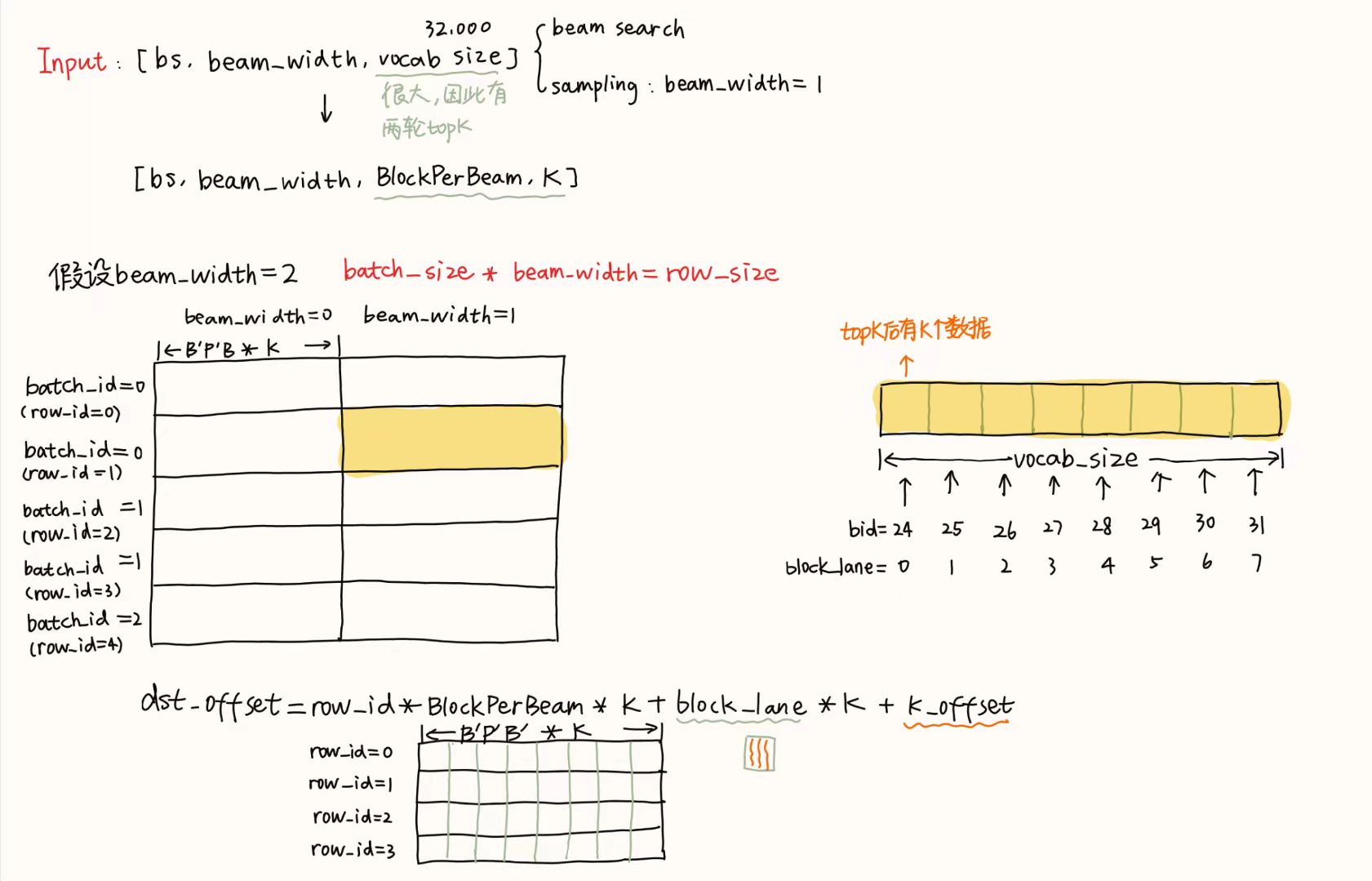
④第二次topK
template<typename T, int beam_width, int K, int blockSize, int BlockPerBeam>
__global__ void topK_kernel_round2(const int* topK_ids,
const T* topK_vals,
int* final_topK_ids,
T* final_topK_vals){
int tid = threadIdx.x;
int bid = blockIdx.x;
int row_id = bid; // 改动1:每个batch只用一个block表示,同时没有block_lane
topK<T, K> thread_topK;
thread_topK.init();
// 下面做thread层次的reduce
for(int data_id = tid; data_id < beam_width * BlockPerBeam * K; data_id += blockSize){ // 改动2:data_id的初始不用考虑该batch的第几个block,步长为blockSize
int data_offset = data_id + bid * beam_width * BlockPerBeam * K; // 改动3:batch内的偏移确定后,data_offset在每个batch之间的偏移就是beam_width*BlockPerBeam*K
thread_topK.insertHeap(topK_vals[data_offset],
topK_ids[data_offset]);
}
typedef cub::BlockReduce<topK<T, K>, blockSize> blockreduce;
__shared__ typename blockreduce::TempStorage tmp_storage;
topK<T, K> block_topk = blockreduce(tmp_storage).Reduce(thread_topK, reduce_functor<T, K>);
if(tid == 0){
int beam_id = (blockDim.x * blockIdx.x + tid) / BlockPerBeam/ K; // 改动4:写入时需要考虑beam_id,感觉这条公式有点奇怪?
for(int k_offset = 0; k_offset < K; k_offset++){
int dst_offset = bid * beam_width * K +
beam_id * K +
k_offset; // 改动5
final_topK_vals[dst_offset] = block_topk.val[k_offset];
final_topK_ids[dst_offset] = block_topk.id[k_offset];
}
}
}
Lesson18 FusedSoftmax and Sampling
讲解了:src/kernels/sampling.cusrc/kernels/sampling.hsrc/utils/params.htests/unittests/test_sampling.cu
在GPU上生成随机数,主机仅传给设备一个信号,是的多个随机数在device端被生成:curand_kernel
params.h
using IntDict = std::unordered_map<std::string, int>;
using floatDict = std::unordered_map<std::string, float>;键为字符串,值为int或float
__device__ void curand_init(unsigned long long seed, unsigned long long subsequence, unsigned long long offset, curandState_t* state)seed:时间种子。subsequence:序列号,区分不同线程块的随机数生成器,确保每个块有自己的随机数生成器。offset:在指定序列中的偏移量,用于跳过序列的前几个值以获得不同的随机数,这里表示从序列的起点开始生成随机数。state:指向curandState_t的指针,保存生成器的内部状态。
__device__ float curand_uniform(curandState_t* state)返回在0.0f和1.0f之间均匀分布的浮动值
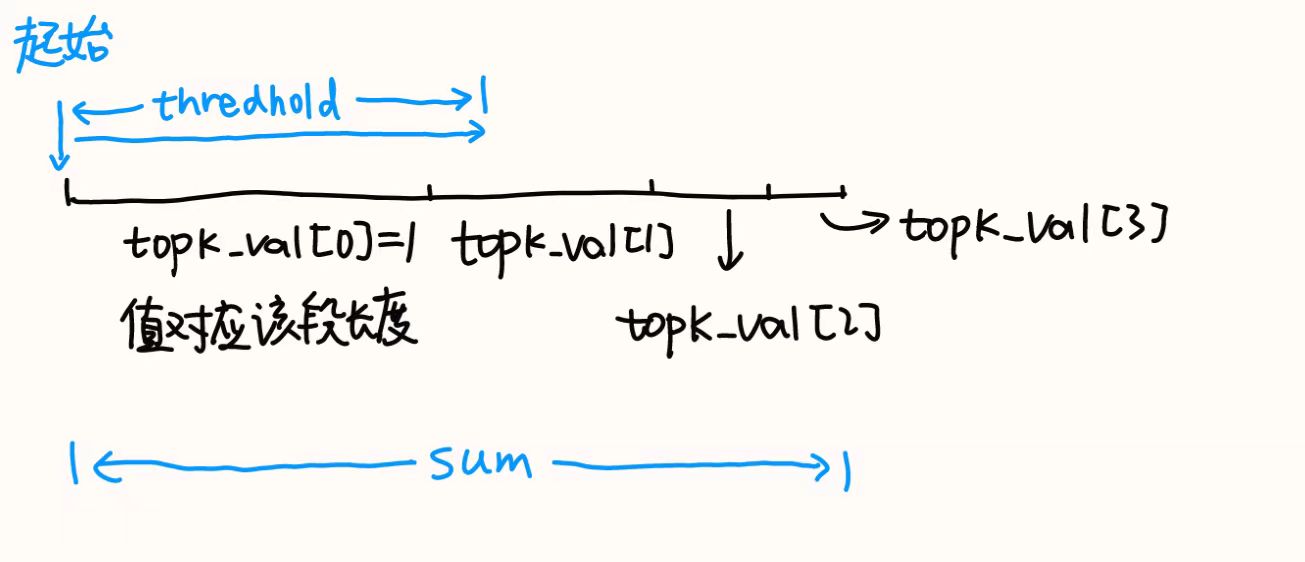
在上图的例子中,thredhold-topk_val[0]>0,thredhold-topk_val[0]-topk_val[1]<0,因此采样值落在topk_val[1]上
- grid:
[batch_size] - block:
[K]
Lesson19 allocator
讲解了:src/memory/allocator/base_allocator.hsrc/memory/allocator/cuda_allocator.h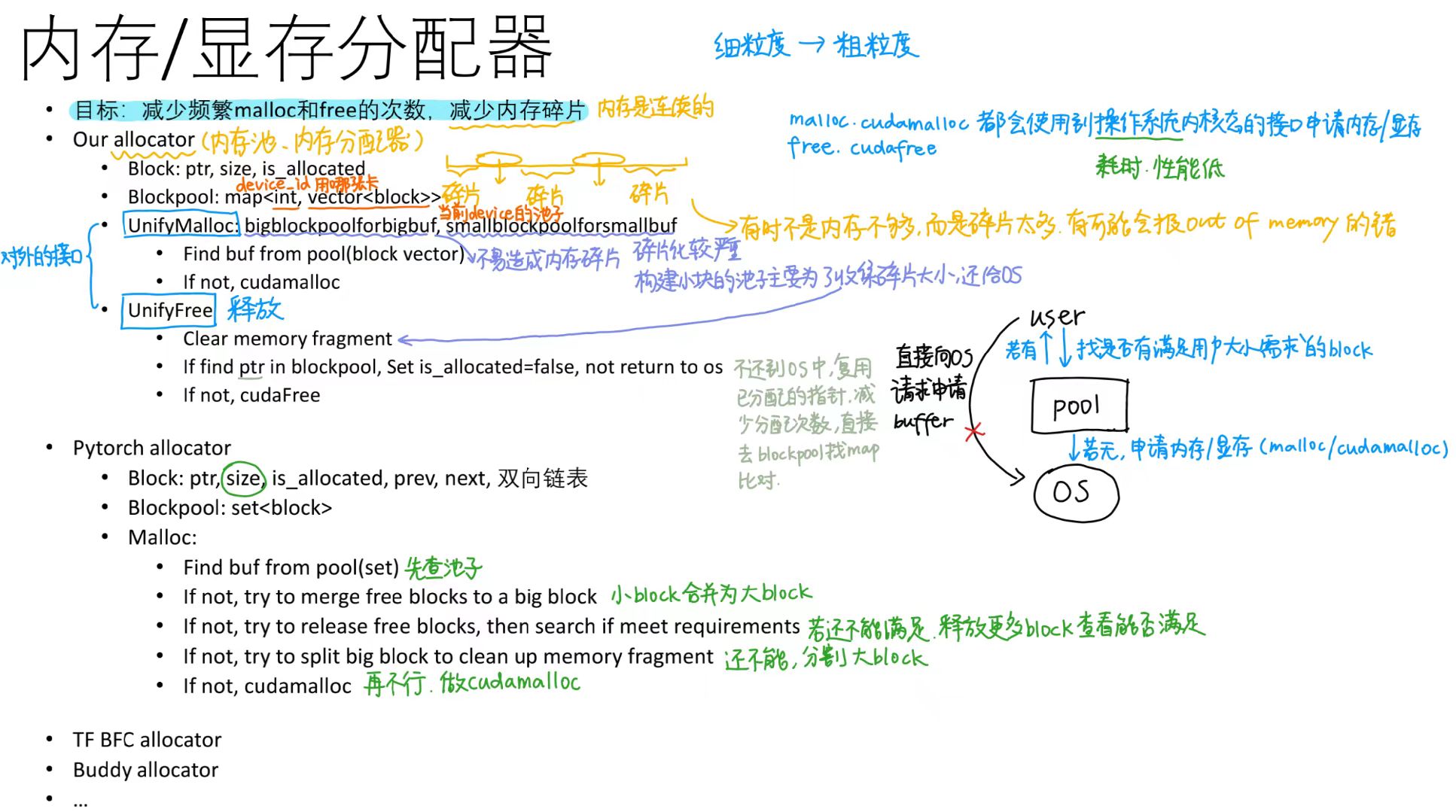
base_allocator.h
class BaseAllocator // 公共的父类
{
public:
virtual ~BaseAllocator(){};
template<class T>
T* Malloc(T* ptr, size_t size, bool is_host){
return(T*)UnifyMalloc((void*)ptr, size, is_host);
}
virtual void* UnifyMalloc(void* ptr, size_t size, bool is_host = false) = 0;
template<typename T>
void Free(T* ptr, bool is_host = false){
UnifyFree((void*)ptr, is_host);
}
virtual void UnifyFree(void* ptr, bool is_host = false) = 0;
};- 父类的析构函数要声明为虚函数:确保当使用基类指针指向派生类对象时,销毁对象时会正确调用派生类的析构函数。
(void*)ptr:CPU的分配函数malloc返回的是一个void类型的,所以把传进去的指针强转为void- 定义
UnifyMalloc和UnifyFree为虚函数,在子类里一定要实现这个函数
cuda_allocator.h
①定义两种块
struct CudaBigBlock {
void *data;
size_t size;
bool is_allocated;
CudaBigBlock() = default; // 构造函数
CudaBigBlock(void* data_, size_t size_, bool is_allocated_): // 构造函数
data(data_), size(size_), is_allocated(is_allocated_){}
};
struct CudaSmallBlock {
void* data;
size_t size;
bool is_allocated;
CudaSmallBlock() = default; // 构造函数
CudaSmallBlock(void* data_, size_t size_, bool is_allocated_): // 构造函数
data(data_), size(size_), is_allocated(is_allocated_){}
};大小块的定义相同
- 大内存块:不易造成内存碎片
- 小内存块:碎片化较严重,构建小块的内存池主要为了收集碎片大小归还OS(有时不是内存不够,而是碎片太多可能会报out of memory的错
②定义分配器
class CudaAllocator: public BaseAllocator {
private:
//{device id: block} // 每个设备都有内存池
std::map<int, std::vector<CudaSmallBlock> > cudaSmallBlockMap;
std::map<int, std::vector<CudaBigBlock> > cudaBigBlockMap;
std::map<int, size_t> FreeSize;
int dev_id; 定义了
- 设备ID与以
CudaSmallBlock为对象的数组的映射(每个设备都有一个大、小内存池) - 设备ID与以
CudaBigBlock为对象的数组的映射 - 设备ID与该设备空闲内存大小的映射
public:
CudaAllocator() {
cudaGetDevice(&dev_id);
}
~CudaAllocator() {
} 为CudaAllocator实现UnifyMalloc
0)对齐32bytes以实现float4
void* UnifyMalloc(void* ptr, size_t size, bool is_host) {
size = ((size + 31) / 32 ) * 32; 1)如果是主机上申请buffer,用
malloc申请if(is_host){
ptr = malloc(size);
memset(ptr, 0, size);
return ptr;
} memset:初始化从ptr指向开始的size个值,初始化的数值为0
2)在bigblocks中找空闲的块,即被free出来但是还未归还到OS的if(size > 1024 * 1024){ auto BigBlocks = cudaBigBlockMap[dev_id]; int blockID = -1; for(int i = 0; i < BigBlocks.size(); i++){ if(BigBlocks[i].size >= size&&!BigBlocks[i].is_allocated && BigBlocks[i].size - size < 1024 * 1024){ if(blockID == -1 || BigBlocks[blockID].size > BigBlocks[i].size){ blockID = i; } } } if(blockID != -1){ BigBlocks[blockID].is_allocated = true; return BigBlocks[blockID].data; } void* new_buffer; cudaMalloc(&new_buffer, size); BigBlocks.push_back(CudaBigBlock(new_buffer, size, false)); return new_buffer; }- 如果
size大于1024k就用bigblock if(BigBlocks[i].size >= size && !BigBlocks[i].is_allocated && BigBlocks[i].size - size < 1024 * 1024)BigBlocks[i].size >= size:该内存块的大小要大于申请的内存!BigBlocks[i].is_allocated:该内存块没有被分配出去BigBlocks[i].size - size < 1024 * 1024:该内存块分配之后剩余的内存不会超过1024k(碎片化?)
if(blockID == -1 || BigBlocks[blockID].size > BigBlocks[i].size)blockID == -1:如果当前还没分配内存块- 或者
BigBlocks[blockID].size > BigBlocks[i].size:已经分配给该内存的内存块比当前的内存块要大,则替换当前内存块来存储
- 分配内存块之后,返回一个void类型的指针
- 如果未能找到合适的,直接
cudaMalloc
3)在smallblocks中找空闲的块,即被free出来但是还未归还到OS的auto SmallBlocks = cudaSmallBlocksMap[dev_id]; for(int i = 0; i < SmallBlocks.size(); i++){ if(SmallBlocks[i].size >= size&&!SmallBlocks[i].is_allocated &&SmallBlocks[i].size - size < 1024 * 1024){ SmallBlocks[i].is_allocated = true; FreeSize[dev_id] += SmallBlocks[i].size; // 这里去掉 return SmallBlocks[i].data; } } - 匹配策略:简单首次匹配,使用第一个符合要求的内存块而不再比较
FreeSize[dev_id] += SmallBlocks[i].size;:将分配出来的内存块大小加到对应设备的FreeSize中,以便之后释放内存
4)没有找到合适内存的void* newBuffer = (void*)ptr; CHECK(cudaMalloc(&newBuffer, size)); CHECK(cudaMemset(newBuffer, 0, size)); // size是初始化的字节数 SmallBlocks.push_back(CudaSmallBlock(newBuffer, size, false)); return new_buffer; }__host__ cudaError_t cudaMemset(void* devPtr, int value, size_t count)- Initializes or sets device memory to a value.
- devPtr:Pointer to device memory
- value:Value to set for each byte of specified memory
- count: Size in bytes to set
0)如果指针指向主机端的内存,直接释放
1)当累积的小内存块超过1G时,清理未分配出去的smallblocks,已分配的保留在smallmap中void UnifyFree(void* ptr, bool is_host) { if (ptr == nullptr) { return; } if(is_host){ cudaFree(ptr); }for(auto& it : cudaSmallBlocksMap){ if(FreeSize[it.first]) > 1024 * 1024 * 1024{ auto& cudaBlocks = it.second; std::vector<CudaSmallBlock> tmp; for(int i = 0; i < cudaBlocks.size(); ++i){ if(!cudaBlocks[i].is_allocated){ cudaSetDevice(it.first); cudaFree(cudaBlocks[i].data); // 未分配,归还OS } else{ tmp.push_back(cudaBlocks[i]); // 已分配,存回map中 } } cudaBlocks.clear(); it.second = tmp; FreeSize[it.first] = 0; } }
for(auto& it : cudaSmallBlocksMap):&it:对容器元素的引用,&表示对it的修改会直接作用于容器中的元素而不会创建副本it.first和it.second:分别是设备ID和内存块向量
__host__ cudaError_t cudaSetDevice(int device):Set device to be used for GPU executions.cudaBlocks.clear():在更新cudaBlocks之前先清空FreeSize[it.first] = 0:对当前设备的FreeSize归零
3)找到待free的内存块的位置,设is_allocated = false,大小block都不归还到OS,除非没有在大小block里面找到待free的指针for(auto& it : cudaSmallBlocksMap){ auto& cudaBlocks = it.second; for(int i = 0; i < cudaBlocks.size(); i++){ if(cudaBlocks[i].data == ptr){ cudaBlocks[i].is_allocated = false; FreeSize[it.first] += cudaBlocks[i].size; return; } } auto& bigBlocks = cudaBigBlocksMap[it.first]; for(int i = 0; i < bigBlocks.size(); i++){ if(bigBlocks[i].data == ptr){ bigBlocks[i].is_allocated = false; return; } } } cudaFree(ptr); } };
a.size和a.size()
- 当
a是标准容器(std::vecotr,std::map等等)时,size是一个成员函数,用于获取容器的大小,写法为a.size(),调用成员函数 - 当
a是用户自定义的类,public: size_t size;时,size是一个成员变量,写法为a.size;public: size(){};时,size是成员函数,写法为a.size()
Lesson 20 Context attention
20.1src/layers/attention/context_attention.cpp
20.1.1 构造函数
LLaMAContextAttentionLayer<T>::LLaMAContextAttentionLayer:构造函数
head_num(head_num),
kv_head_num(kv_head_num),
head_size(head_size),
stream(stream),
cublas_wrapper(cublas_wrapper),
allocator(allocator),
hidden_units(head_num * head_size),
attn_static_params(attn_params),
q_head_per_kv(head_num / kv_head_num),
scale(float(1 / sqrt(head_size)20.1.2 分配内存
LLaMAContextAttentionLayer<T>::allocForForward(LLaMAAttentionDynParams& params):分配forward所需要的buffer
LLaMAAttentionDynParams定义来源:src/models/llama_llama_params.hstruct LLaMAAttentionDynParams { int batch_size; int num_tokens; int max_q_len; int max_k_len; }先定义指针
new:它从堆上分配指定类型的内存,并返回一个指向该内存块的指针。使用new分配的内存不会像栈上分配的变量那样在函数结束时自动释放,需要手动释放。- 和
malloc区别:new:不仅分配内存,还会调用对象的构造函数(如果是类对象的话)malloc:只负责分配内存,不会调用构造函数
- 再分配内存
allocator->Malloc- 对
k_cache_buf和v_cache_buf分配内存时,在k_cache_buf分配两倍的内存,再令v_cache_buf的数据指针指向k_cache_buf偏移batch_size * head_num * max_k_len * head_size的地方。这样可以减少一次内存分配
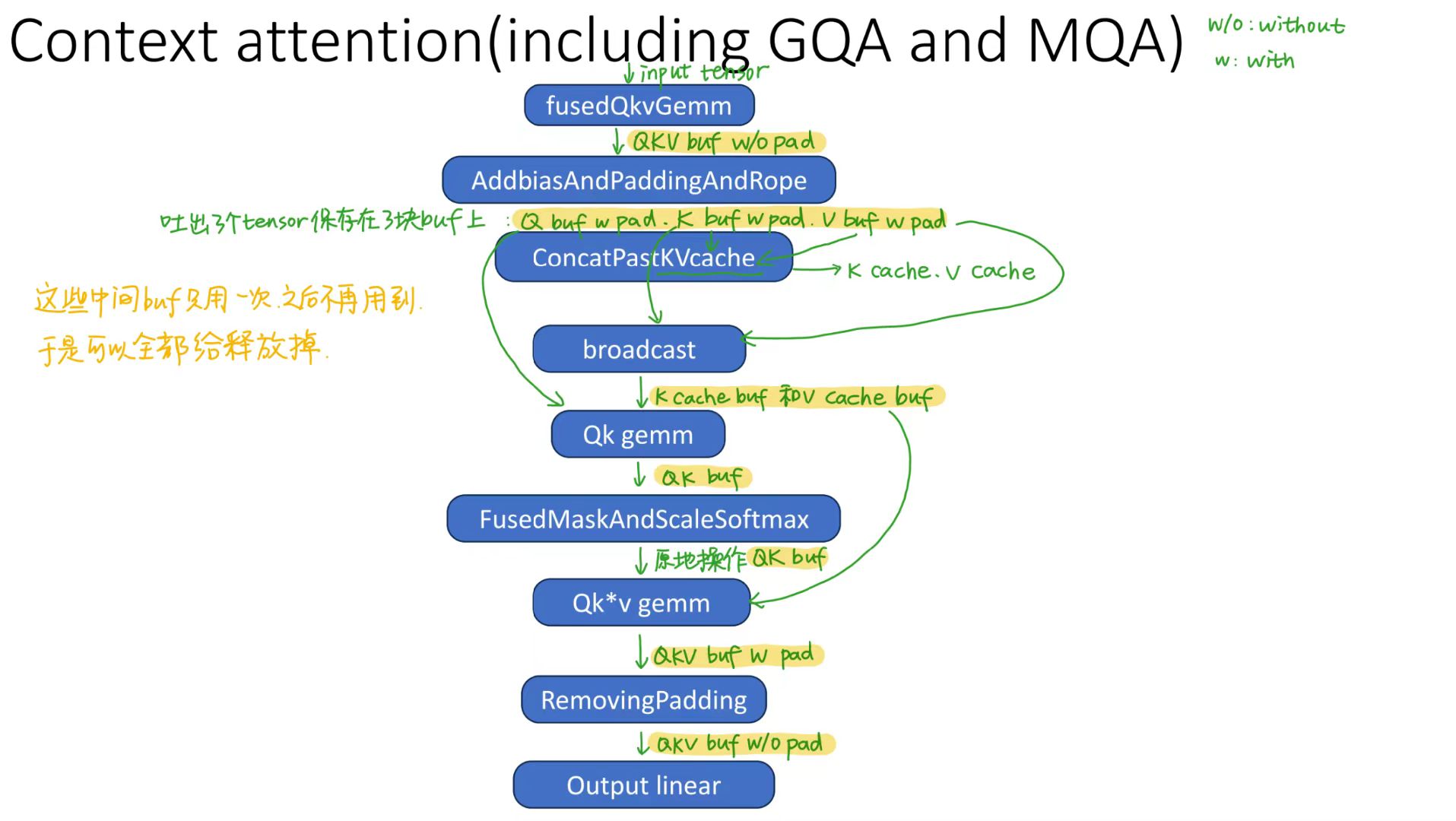
①k_cache_buf->data = allocator->Malloc(k_cache_buf->data, 2 * sizeof(T) * batch_size * head_num * max_k_len * head_size); v_cache_buf->data = (T*)k_cache_buf->data + batch_size * head_num * max_k_len * head_size;fusedQkvGemminput
input tensoroutputqkv_buf_wo_pad:[num_tokens, qkv_head_num, head_size]
作用:做linear将输入的tensor乘上qkv权重,得到qkv
②AddbiasAndPaddingAndRopeoutputq_buf_w_pad:[bs, head_num, max_q_len, head_size]k_buf_w_pad:[bs, kv_head_num, max_q_len, head_size]v_buf_w_pad:[bs, kv_head_num, max_q_len, head_size]
作用:添加偏置,进行padding使同一批次的句子长度相同,进行位置旋转编码
③ConcatPastKVcacheoutputk_cache_buf:[bs, head_num, max_q_len, head_size]v_cache_buf:[bs, head_num, max_q_len, head_size]
作用:将新得到的KV存储到cache中
④qk gemmoutputqk_buf:[bs, head_num, max_q_len, max_k_len]
作用:进行qk相乘,得到$QK^T$
⑤FusedMaskAndScaleSoftmaxoutputqk buf
作用:加上mask并进行scale和softmax,得到$Softmax(\dfrac{QK^T}{\sqrt{d_k}})$
⑥qk*v gemmoutputqkv_buf_w_pad:[bs, head_num, max_q_len, head_size]
作用:得到$Softmax(\dfrac{QK^T}{\sqrt{d_k}})V$
⑦RemovingPaddingoutputqkv_buf_wo_pad_1:[num_tokens, head_num, head_size]
作用:将padding去掉
20.1.3 释放内存
src/utils/macro.h
inline void syncAndCheck(const char* const file, int const line){
cudaDeviceSynchronize();
cudaError_t result = cudaGetLastError();
if (result) {
throw std::runtime_error(std::string("[TM][ERROR] CUDA runtime error: ") + (_cudaGetErrorEnum(result)) + " " + file + ":" + std::to_string(line) + " \n");
}
}
#define DeviceSyncAndCheckCudaError() syncAndCheck(__FILE__, __LINE__) syncAndCheckcudaDeviceSynchronize():确保当前所有 CUDA 操作完成cudaGetLastError():检查CUDA运行时的最后一个错误- 参数:
file:记录发生错误的源文件名称line:记录发生错误的行号
#define DeviceSyncAndCheckCudaError() syncAndCheck(__FILE__, __LINE__)- 调用
syncAndCheck函数,并自动捕获当前的文件名和行号,在调用时不需要显式传递__FILE__和__LINE__
- 调用
释放qkv_buf_wo_pad、q_buf_w_pad、k_cache_buf、qk_buf、qkv_buf_w_pad、qkv_buf_wo_pad_1,在每个Free的后面加上DeviceSyncAndCheckCudaError(),检查是否发生错误
20.1.4 前向传播
src/utils/tensor.h
struct TensorMap{
std::unordered_map<std::string, Tensor*> tensor_map_;
TensorMap() = default;
TensorMap(std::initializer_list<std::pair<std::string, Tensor*>> tensor_map){
for (auto& pair : tensor_map){
if (isValid(pair.second)){
tensor_map_.insert(pair.first, pair.second);
}
else{
LLM_CHECK_WITH_INFO(isValid(pair.second),fmtstr("%s is not a valid tensor, skipping insert into TensorMap", pair.first.c_str()));
}
}
}
TensorMap(const std::unordered_map<std::string, Tensor*>& tensor_map) {
for(auto it = tensor_map.begin(); it != tensor_map.end(); it++){
if (isValid(it->second)) {
tensor_map_.insert(it->first, it->second);
}
else {
// TODO: add a reminder info
}
}
};
// ...
}TensorMap(std::initializer_list<std::pair<std::string, Tensor*>> tensor_map)- 接受一个
std::initializer_list类型的参数,其元素是键值对std::pair<std::string, Tensor*>,适用于初始化容器 - 例子👇
Tensor* tensor1 = new Tensor(); Tensor* tensor2 = nullptr; // 无效指针 TensorMap tmap = {{"key1", tensor1}, {"key2", tensor2}} // 无效,会被跳过
- 接受一个
TensorMap(const std::unordered_map<std::string, Tensor*>& tensor_map)- 接受一个
std::unordered_map<std::string, Tensor*>类型的参数,使用现有哈希表初始化 - 例子👇
std::unordered_map<std::string, Tensor*> umap = {{"key1", tensor1}, {"key2", tensor2}}; TensorMap tmap(umap);
- 接受一个
①入参
template<typename T>
void LLaMAContextAttentionLayer<T>::forward
(TensorMap& inputs,
TensorMap& outputs,
LLaMAattentionWeights<T>& weights,
LLaMAAttentionDynParams& params,
LLaMAAttentionStaticParams& static_params)inputs:元素大概是{"attention_input",tensor1},{"padding_offset",tensor2}- 因为很多函数需要TensorWrapper,而传进去的是Tensor,对于需要Tensor强转为TensorWrapper的情况,用到👇(
src/utils/tensor.h)template<typename T> TensorWrapper<T>* as(){ return static_cast<TensorWrapper<T>*>(this); // Tensor转子类TensorWrapper的下行转换 }
- 因为很多函数需要TensorWrapper,而传进去的是Tensor,对于需要Tensor强转为TensorWrapper的情况,用到👇(
outputs:同上weights:src/weights/llama/attention_weights.h中,内置属性有BaseWeight<T> qkv; BaseWeight<T> output;params:src/models/llama/llama_params.h,内置属性有int batch_size; int num_tokens; int max_q_len; int max_k_len;static_params:src/models/llama/llama_params.h,是关于旋转编码的属性int rotary_embedding_dim; float rotary_embedding_base; int max_position_embeddings; bool use_dynamic_ntk;
②准备内存
使用20.1.2中的分配内存
③qkv linearsrc/kernels/linear.h
launchLinearGemm(attention_input->as<T>(), weights.qkv, qkv_buf_wo_pad, cublas_wrapper)对应
input、weight、output、cublas_wrapper、trans_a、trans_b完成
fusedQkvGemm
④qkv bias and rope and padding
launchAddFusedQKVBiasTransposeAndRoPE(qkv_buf_w_pad,
k_buf_w_pad,
v_buf_w_pad,
qkv_buf_wo_pad,
weights.qkv,
padding_offset->as<int>(),
history_length->as<int>(),
input_length->as<int>(),
static_params);最后在
k_buf_w_pad和v_buf_w_pad得到rope和padding的版本
⑤concat past kv cache
launchConcatKVCache(k_buf_w_pad, v_buf_w_pad,
layer_id->as<int>(),
input_length->as<int>(),
history_length->as<T>(),
all_k_cache->as<T>(),
all_v_cache->as<T>());最后在
all_k_cache和all_v_cache得到kvcache因为
layer_id是在CPU上分配的int layer = layer_id->getVal();因此需要转为TensorWrapper
⑥repeat kv
launchRepeatKVCache(all_k_cache->as<T>(),
all_v_cache->as<T>(),
context_length->as<int>(),
layer_id->as<int>(),
k_cache_buf,
v_cache_buf);input:all_k_cache&all_v_cache: [num_layers, batch_size, kv_head_num, max_seq_len, head_size]output:k_cache_buf&v_cache_buf: [bs, head_num, max_k_len, head_size]作用是将kvcache的
kv_head_num补成head_num
⑦qk
launchLinearStridedBatchGemm(q_buf_w_pad, k_cache_buf, qk_buf, cublas_wrapper, false, true);input:q_buf_w_pad: [bs, head_num, max_q_len, head_size]k_cache_buf: [bs, head_num, max_k_len, head_size](trans_b = true)output:qk_buf: [bs, head_num, max_q_len, max_k_len]
⑧scale + mask + softmax
launchScaleMaskAndSoftmax(qk_buf, attention_mask->as<T>(), qk_buf, scale);给
qk_buf加scale、mask、softmax
⑨qk*v
launchLinearStridedBatchGemm(qk_buf, v_cache_buf, qkv_buf_w_pad, cublas_wrapper, false, false);input:qk_buf: [bs, head_num, max_q_len, max_k_len]v_cache_buf: [bs, head_num, max_k_len, head_size]output:qkv_buf_w_pad: [bs, head_num, max_q_len, head_size]
⑩transpose + removepadding
launchTransposeOutRemovePadding(qkv_buf_w_pad, padding_offset->as<T>(), qkv_buf_wo_pad_1);input:qkv_buf_w_pad: [bs, head_num, max_q_len, head_size]先transpose变成
[bs, max_q_len, head_num, head_size]output:qkv_buf_wo_pad_1: [numtokens, hiddenunits]
①output linear
launchLinearGemm(qkv_buf_wo_pad_1, weights.output, attention_output, cublas_wrapper, false, true);乘上输出的权重
②freebuf
释放所有的缓存
20.2examples/cpp/attention/context_attn_example.cpp
变量:
- 基本参数:
head_num&kv_head_num:前者是q的,后者是k和v的head_sizenum_layersmax_seq_len:kv cache最大的上下文长度hidden_units&q_hidden_units:前者是qkv总和的,后者是q的- 作为初始化每个kernel里大小的参数
- 静态参数:(多数是位置编码的)
rotary_embedding_dimrotary_embedding_basemax_position_embeddingsuse_dynamic_ntk
- 动态参数:
batch_sizenum_tokensmax_q_len&max_k_lenmax_q_len:padding之前同一batch下的最长的句子长度max_k_len:同一个batch中上下文的最大值
- 输入输出值(从主机上获取数据,复制到设备上)
attention_input:[num_tokens,q_hidden_units],是最初的输入qkv_weights:[q_hidden_units, hidden_units],做qkvgemm时用到mask:[batch_size, max_q_len, max_k_len],当前的toekn不能访问到其后面的tokenqkv_bias:[hidden_units],qkv的偏置all_k_cache:[num_layers, batch_size, kv_head_num, max_seq_len, head_size]all_v_cache:[num_layers, batch_size, kv_head_num, max_seq_len, head_size]padding_offset:[num_tokens],每个token都有一个”在该token之前的padding个数的数值“history_length:[batch_size]layer_id:ctx_len:[batch_size],每句话的上下文长度?attention_output:[num_tokens, q_hidden_units]output_weights:[q_hidden_units, q_hidden_units]
Lesson21 mask self attention layer
说是写的GQA部分
区别与context decoder:
- 自回归生成模式,因此不需要mask和padding(和remove padding)
layer搭建顺序和context attention类似
21.1src/layers/attention/masked_self_attentioon.cpp
①分配内存
allocForForward(params);②qkv linear
launchLinearGemm(attention_input->as<T>(), weights.qkv, qkv_buf, cublas_wrapper);同时,这里不需要在后面加上
DeviceSyncAndCheckCudaError();因为cublasWrapper自带了CHECK_CUBLAS(因此涉及到cublas的都不需要再进行检查)③fused decoder self attention
launchDecoderMaskedMHA(qkv_buf, weights.qkv,
layer_id->as<int>(),
k_cache->as<T>(),
v_cache->as<T>(),
finished->as<bool>(),
step->as<int>(),
mha_output->as<T>(),
static_params);最后一个入参是
LLaMAAttentionStaticParams& static_param,是一个含有位置编码属性的结构体
struct LLaMAAttentionStaticParams {
int rotary_embedding_dim;
float rotary_embedding_base;
int max_position_embeddings;
bool use_dynamic_ntk; // for dyn scaling rope
};
template<typename T>
class LLaMASelfAttentionLayer {
private:
LLaMAAttentionStaticParams attn_static_params;
public:
LLaMAAttentionStaticParams& GetAttnStaticParams(){
return attn_static_params; // 这里的返回值是引用,函数的调用不会复制attn_static_params,而是直接返回它的内存地址
}
template<typename T>
void LLaMASelfAttentionLayer<T>::forward(TensorMap& inputs, TensorMap& outputs, LLaMAattentionWeights<T>& weights, LLaMAAttentionDynParams& params){
LLaMAAttentionStaticParams static_params = GetAttnStaticParams();
}- 为什么可以直接使用
LLaMAAttentionStaticParams static_params = GetAttnStaticParams();:- 编译器对引用指向的
attn_static_params执行拷贝构造,生成一个新的LLaMAAttentionStaticParams实例- 局部变量
static_params是一个值类型 GetAttnStaticParams()返回一个指向类中成员变量attn_static_params的引用
- 局部变量
- 如果修改
static_params,不会影响attn_static_params
- 编译器对引用指向的
- 如果是另一种情况
LLaMAAttentionStaticParams& static_params = GetAttnStaticParams();static_params只是attn_static_params的一个别名,编译器不会为static_params分配新的内存空间,他和attn_static_params共用一块内存- 局部变量
static_params是一个引用类型 GetAttnStaticParams()返回一个指向类中成员变量attn_static_params的引用
- 局部变量
- 引用与指针的区别
- 引用:一旦绑定到某个变量就不能再绑定到其他变量;本质上是变量的别名,不需要占用额外的内存
- 指针:可以重新指向其他变量;是一个独立的变量,需要占用内存来存储地址
④output
launchLinearGemm(mha_output, weights.output, attention_output->as<T>, cublas_wrapper);21.2src/examples/cpp/attention/self_attention_example.cpp
变量:
- 基本参数:
head_num&kv_head_num:前者是q的,后者是k和v的head_sizenum_layersmax_seq_len:kv cache最大的上下文长度hidden_units&q_hidden_units:前者是qkv总和的,后者是q的- 作为初始化每个kernel里大小的参数
- 静态参数:(多数是位置编码的)
rotary_embedding_dimrotary_embedding_basemax_position_embeddingsuse_dynamic_ntk
- 动态参数:
batch_size
- 输入输出值(从主机上获取数据,复制到设备上)
attention_input:[num_tokens,q_hidden_units],是最初的输入all_k_cache:[num_layers, batch_size, kv_head_num, max_seq_len, head_size]all_v_cache:`[num_layers, batch_size, kv_head_num, max_seq_len,layer_idfinished:[batch_size]qkv_weights:[q_hidden_units, hidden_units],做qkvgemm时用到output_weights:[q_hidden_units, q_hidden_units]qkv_bias:[hidden_units],qkv的偏置attention_output:[num_tokens, q_hidden_units]
Lesson22 FFN
关于Transformer中feed forward layer理解
Transformer 论文通俗解读:FFN 的作用
22.1 src/layers/ffn/ffn.h
void allocForForward(LLaMAAttentionDynParams& params);
void allocForForward(int batch_size);重载函数
- context attention中在remove padding后数据的第一维是
num_tokens(传入的是params.num_tokens) - self attention中数据的第一维一直是
batch_size([batch_size, 1, ...])
22.2 src/layers/ffn/ffn.cpp
forward()
①确定使用哪种forward的内存分配
if (params.num_tokens > 0) {
allocForForward(params);
} else {
allocForForward(params.batch_size);
}如果存在num_tokens则为context attention,对应
params;如果不存在则为self attention,对应
batch_size
②fusedGateUp projs
launchLinearGemm(ffn_input->as<T>(), weights.gateAndup, SwiGLU_input, cublas_wrapper, false, true);- 输入
ffn_input:[bs(/num_tokens), q_hidden_units] - 权重
weights.gateAndup:[q_hidden_units, 2 * inter_size] - 输出
SwiGLU_input:[bs(/num_tokens), 2 * inter_size] - 经过Gate Linear和Up Linear的输入都是
[bs(/num_tokens), q_hidden_units],因此将他们像fusedQKVGemm一样进行fusedGateUpGemm,输出使用同一块buf - 为啥这里trans_b=true?
③swiGLU
launchAct(SwiGLU_input, down_proj_input);- 输入
SwiGLU_input:[bs(/num_tokens), 2 * inter_size]- 两个大小为
[bs(/num_tokens), inter_size]的Gate数组和Up数组的相同偏移量的数据一起计算,因此最后的输出的第二维大小为原来的一半
- 两个大小为
- 输出
down_proj_input:[bs(/num_tokens), inter_size]
④down proj
launchLinearGemm(down_proj_input, weights.down, ffn_output->as<T>(), cublas_wrapper, false, true);- 输入
down_proj_input:[bs(/num_tokens), inter_size] - 权重
weights.gateAndup:[q_hidden_units, inter_size]trans_b=true - 输出
SwiGLU_input:[bs(/num_tokens), q_hidden_units]
22.3examples/cpp/ffn/ffn_example.cpp
变量:
- 基本参数:
- `head_num
head_sizeinter_size- `hidden_units
- 作为初始化每个kernel里大小的参数
- 动态参数:
num_tokens
- 输入输出值(从主机上获取数据,复制到设备上)
ffn_input:[hidden_units, num_tokens]gate_up:[hidden_units, 2 * inter_size]down:[hidden_units, inter_size]
- 设置为设备参数
ffn_output
22.4 关于CMakeList.txt
src/layers/ffn/CMakList.txt
- 将
ffn.cpp编译到静态库中并命名为Llamaffnadd_library(Llamaffn STATIC ffn.cpp) - 链接
Llamaffn所用到的函数(launchLinearGemm,launchAct)对应的静态库(linear,act)target_link_libraries(Llamaffn PUBLIC -lcudart -lcudadevrt act linear)examples/cpp/ffn/CMakeList.txt - 将
ffn_example.cpp编译到可执行目标文件中并命名为ffnExampleadd_executable(ffnExample ffn_example.cpp) - 链接
ffnExample所用到的函数(ffn.cpp)对应的静态库(Llamaffn)
Lesson23 llama layer weight
讲解了:src/weights/llama/layer_weights.hsrc/weights/llama/layer_weights.ccsrc/weights/llama/CMakelists.txtsrc/utils/weights_utils.hsrc/utils/weights_utils.cusrc/utils/CMakelists.txt
有weight的地方
- llama weights
- Embedding
- LMhead(本质上也是一个linear)
- layer weights
- 特点是有很多transformer堆叠起来
LayerNormWeight<T> attn_norm_weight;- RMSNorm
LLaMAattentionWeights<T> self_attn_weight;- QKVgemm
- output linear
LayerNormWeight<T> ffn_norm_weight;- FusedAddbiasResidualAndRMSNorm
LLaMAFFNWeights<T> ffn_weight;- Gate
- Up
- down
src/utils/weights_utils.cu
在源文件中的模板不是一个函数,只有在实例化后才是一个函数并且可以进行链接
实现了GPUMalloc和GPUFree,目的:在分配内存和释放内存时进行检查
src/weights/llama/layer_weights.h
定义了四个函数
src/weights/llama/layer_weights.cc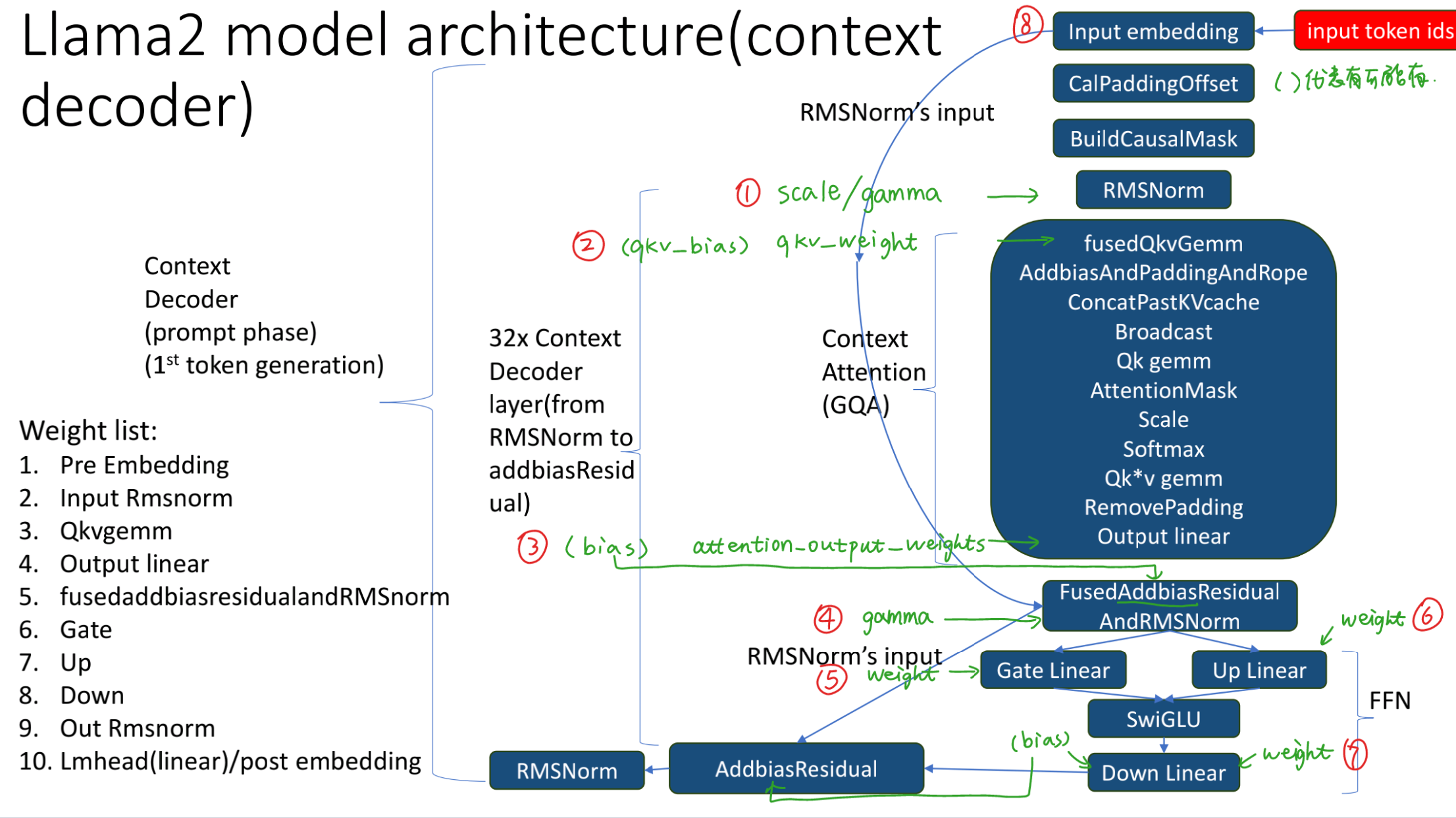
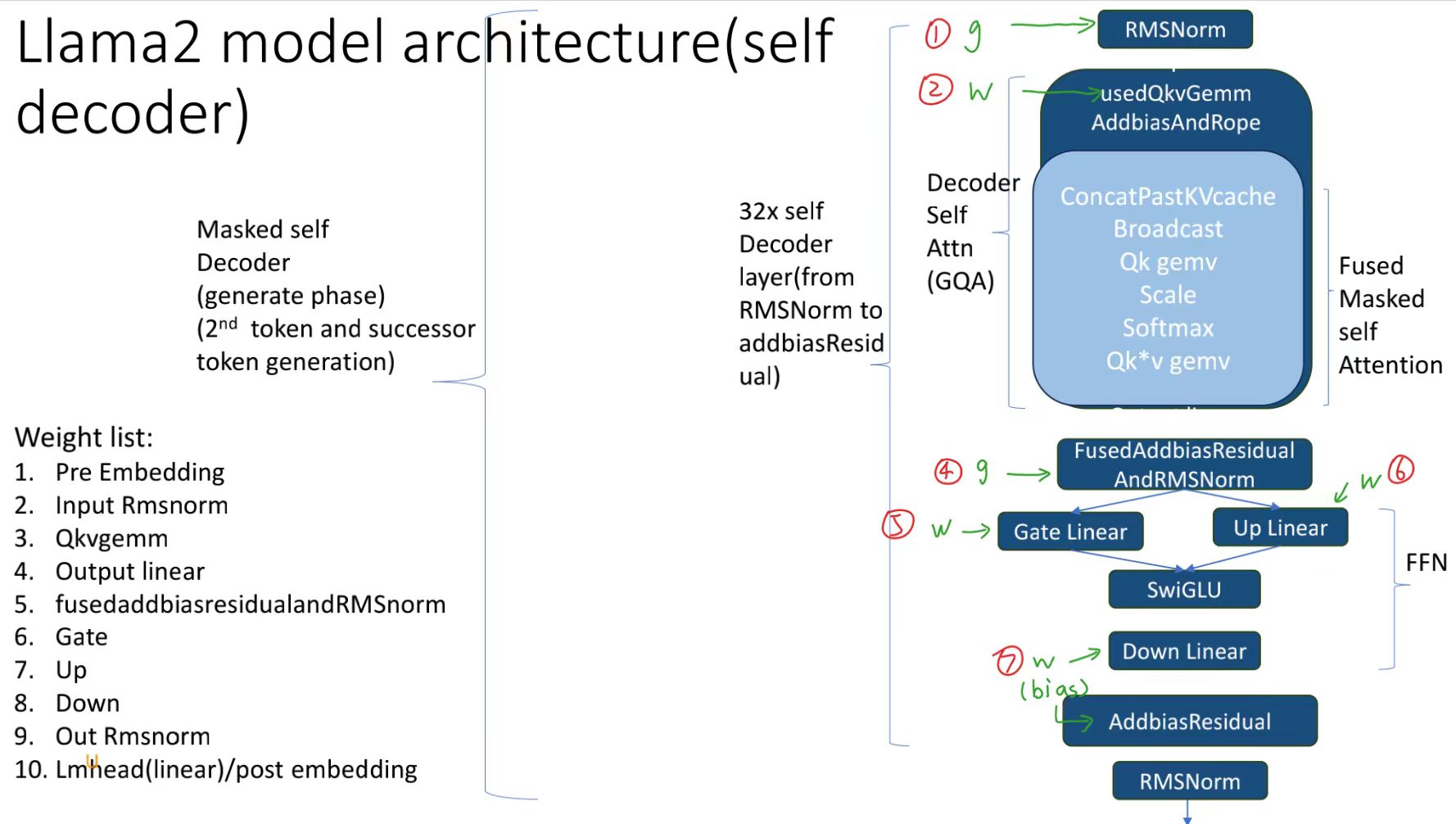
①attn_norm_weight.gamma:context decoder和self decoder共用
- 类型为:
LayerNormWeight<T> - 成员有:
T* gamma
④ffn_norm_weight.gamma:context decoder和self decoder共用
同上
②self_attn_weight.qkv:context decoder和self decoder共用
- 类型为:
BaseWeight<T> - 成员有:
std::vector<int> shape;T* data;WeightType type;T* bias;不一定每个weight都有
③⑤⑥⑦同上
③self_attn_weight.output
⑤ffn_weight.gate:context decoder和self decoder共用
⑥ffn_weight.up:context decoder和self decoder共用
⑦ffn_weight.down:context decoder和self decoder共用
在loadWeights这一步中,可以加入假的数据,省去加载模型这一步,主要用于测试性能,不关注精度
- 流程:
cudaMalloc各种d_weights变量 ->malloc各种h_weights变量 -> h_weights载入假数据 -> 通过cudaMemcpy将h_weights复制到d_weights -> 再将d_weights赋值给
freeWights(BaseWeight<T>& weights):将bias也给释放
最后析构函数中释放所有的缓存
Lesson24 AddBiasResidual
讲解了:src/kernels/add_residual.hsrc/kernels/add_residual.cutests/unittest/test_residual.cu
residual来源FusedAddbiasResidualAndRMSNorm中FusedAddbiasResidual的输出(同时是RMSNorm的输入)decoder_out来源Down Linear
decoder_out += residual
decoder_out:[num_tokens, hidden_units]redisual:[num_tokens, hidden_units]←在context decoder中,在self decoder中第一维是batch_size- 作用:代表了初步融合后的特征,是一种包含原始信息与新特征的信息流,随后会传递到归一化操作(如 RMSNorm)中,以便为下游模块提供稳定的分布。
Vec_t* dout = reinterpret_cast<Vec_t*>(decoder_out + batch_id * hidden_units);
Vec_t* rsd = reinterpret_cast<Vec_t*>(residual + batch_id * hidden_units);将decoder_out和residual转化为向量化类型,并且每个dout/rsd表示每一个token或batch每一行的数据都能被转换为Vec_t类型的指针
一般实现(fp32)和特化实现(专给fp16使用)的区别
for(int i = tid; i < hidden_units/vec_size; i+=blockDim.x){
dout[i].x += rsd[i].x; // dout既是输入也是输出
dout[i].y += rsd[i].y;
dout[i].z += rsd[i].z;
dout[i].w += rsd[i].w;
}
for(int i = tid; i < hidden_units/vec_size; i+=blockDim.x){
dout[i] = __hadd2(dout[i], rsd[i]); // 两个half2做加法
}for循环保证一个block的线程能够遍历完hidden_units的元素
tests/uinttests/test_residual.cu
在CPUresidual中,可以通过AVX-512 kernel + openMP进行性能改善
AVX-512(Advanced Vector Extensions 512)- SIMD
- 支持512位宽的寄存器和矢量操作
- 每次处理可以加载16个浮点数
OpenMP(Open Multi-Processing)- 多线程并行编程接口,用于在共享内存环境中通过任务划分和线程控制实现并行加速
Lesson25 Context Decoder
src/layers/decoder
Input embedding -> RMSNorm -> Context Attention -> FusedAddbiasResidualAndRMSNorm(凡是残差加,残差来自上一个RMSNorm的输入) -> FFN -> AddbiasResidual
四个中间buffer:
decoder_residual:(不同时)存储(两个地方的)残差attention_mask:保存生成的CausalMaskpadding_offsetcum_seqlens:累积句子长度,和padding_offset的生命周期一样
src/layers/decoder/context_decoder.cppLlamaContextDecoder<T>::forward
- 入参:
TensorMap& input_tensors- `const std::vector
TensorMap& output_tensorsLLaMAAttentionDynParams& dyn_params
①内存分配:导入动态变量并分配四个中间buffer的内存
②获得偏移allocForForward(dyn_params);Tensor* seq_lens = input_tensors["input_length"]; launchCalPaddingoffset(padding_offset, cum_seqlens, seq_lens->as<int>());
- 入参:
TensorWrapper<int>* padding_offsetTensorWrapper<int>* cum_seqlens,累积的句子长度,是所有batch的累积TensorWrapper<int>* input_lengths,每个句子的输入长度
③获取掩码长度Tensor* context_length = input_tensors["context_length"]; launchBuildCausalMasks(attention_mask, seq_lens->as<int>(), context_length->as<int>());
- 入参:
TensorWrapper<T>* maskTensorWrapper<int>* q_lens,每个句子的输入长度TensorWrapper<int>* k_lens,每个句子的上下文长度
④搭建32层context decoder layer并进行context attention
为啥:搜“疑问”
1)从函数输入的input_tensors和output_tensors获得相应键值对并取地址,检查是否为空
2)初始化ctx_attn_inputs和ctx_attn_outpus键值对,这里指的是每一层的输入和输出
3)进行32层Layer的context attention
- 从for循环的变量获取
layer_id并更新到ctx_attn_inputs[layer_id]中 - 获取context attntion的输入
- 进行context attention,输出为
ctx_attn_outputs - 进行FusedAddBiasResidualRMSNorm,输出为
decoder_output(ctx_attn_outputs[“attention_output”]的指针) - 进行ffn,输入为
decoder_output,输出直接复用输入的内存区 - 进行AddResidual,该kernel在实现时,残差加的结果放在decoder_out上
- 把当前Layer的输出作为下一层Layer的输入,直接用当前Layer的输出
decoder_output更新到key为”attention_input”的value中
Lesson26 Self Decoder
待解决:llama2是不包含第一个addbias的,所以只剩下RoPE,因为旋转编码的旋转大小是64,所以不能融合到Fused Masked self Attetion里,如果是2就可以
- RoPE没有出现!
- 有的,是在Fused Masked self Attention里
除了一些不需要的变量,步骤方法和context decoder的搭建差不多
Lesson27 llama weights
tools/convert_downloaded_llama_weights.pytools/weights_conver.py
- 在python中
- 下载模型
- 转换
- 将原本的.pth形式的权重,对应输出到每一层的每一个类型的(qkvgemm, gate, down, up等等的)权重
- 合并qkv的权重,合并gate和up的权重,把所有权重文件转为.bin格式的,即转为二进制
src/weights/llama/llama_weights.ccsrc/weights/llama/llama_weights.h
- 读取从python文件中得到的权重,并赋值给已分配好显存的指针
- 四个public成员(llama weights)
llama_layer_weight,有num_layer层out_rmsnorm_weightpost_decoder_embedding_weight(sampling的LMhead)pre_decoder_embedding_weight
src/utils/weights_utils.ccsrc/utils/weights_utils.h
- 当pyhton转换完的权重格式与目标格式不一致时,如half和float,则进行转换再加载二进制文件
llama_layer_weight.reserve(num_layer);- vector.push_back和vector.reserve的区别
- push_back,2->4->6->8->16->32->…,当向量中有2个元素,push_back到3个元素时,vector地址自动重新分配并且容量变为4,后续的增加同理
- reserve,指定容量,不会自动重新分配
Lesson28 llama类
更高层次的抽象
std::function<返回值类型(参数列表)>定义了一个可调用对象的签名
- 可调用对象的签名包括返回值类型和参数列表

src/models/llama/llama.cppsrc/models/llama/llama.h
std::string Llama<T>::Response(const std::vector<std::string> &input, CallBack PrintRes)
- 入参
input:用户输入的类型为字符串向量的句子PrintRes:打印结果
Encodeinput、history_str、total_str- 上面这三个和
MakeInput函数有关 MakeInput中的ret就是Response中的inputtotal_str是所有轮次的input,包括现在和之前的history_str是之前轮次的inputinput是现在轮次的input
- 得到三者的token indexs
- 这三者的长度是
int_params_first_token字典中的值
attn_dyn_paramsllama类模型里动态改变的变量batch_size:硬写为1num_tokens:当前输入的长度max_q_len:batch中q的最大长度,因为一个batch只有一个句子,所以等于num_tokensmax_k_len:动态最大上下文,step的值与其相同(在self decoder中用到)
- 获得所有轮次的token string
- 自定义
self_token_limit firstTokenGen- 入参:
attn_dyn_params、int_params_first_token InitializeForContextDecoder- 传入所有轮次、之前轮次和现在轮次到CPU中,再复制到GPU中
inputEmbedding- 得到输入的句子对应的token在embed table里的词向量
- 包装
decoder_inputs和decoder_outputs这两个TensorMap - 进行推理
- 进行RMSNorm
- 进行LMHead和topkSample
- LMHead
- 如果是context decoder
- 取输出里的最后一个token作为LMHead的输入,经过矩阵相乘得到
probs维度为:[1, vocab_size],就知道这几个vocab的可能性
- 取输出里的最后一个token作为LMHead的输入,经过矩阵相乘得到
- 如果是self decoder
decoder_output就是唯一的token,直接作为LMHead的输入
- 如果是context decoder
- topkSample
*
- LMHead
- 入参:
continueTokenGen
- 自定义
Lesson29
提供接受用户输入或者promt的接口
实现大封装的API,创建C++类
std::unique_ptr
- 独占所有权,不能被共享
- 自动释放内存
- 不可以被复制,所有权可以转让,转让后原来的变为空指针
LLMengine-learn/user_entry.cpp
- 传入模型和tokenizer的地址,直接调用Response
debug思路
- 打印/保存中间数据:将输出存为一个.bin文件,再使用
std::ifstream读取,可以逐一比较(与huggingface的)结果
- fp32两个结果的误差大于$10^{-6}$就说明有误差
DeviceSynAndCheckCudaError
- 检查有没有运行时错误
- 有
cudaDeviceSynchronize():CPU等待GPU上所有任务完成,因此最好在确保项目没有问题时关掉
// CMakeList.txt中
option(PERF
"measure the model inference performance"
OFF)
if(PERF)
add_compile_option(-DPRINT_DATA)
endif()
// context_attention.cpp中
#ifndef PERF
DeviceSynAndCheckCudaError();
#else
#endif- CMake选项定义:
option(选项名称 “选项描述” 默认值) - 如果
PERF是ON,那么在编译选项中添加-DPRINT_DATA,即在编译时添加一个宏PRINT_DATA cmake .. -DPERF=ON时打开不进行Check(即不打开“检查运行时错误“)
- PRINT_DATA
- 通常在首先输入的kernel里需要,检查放在lanuch里
其他
- emm配完annaconda之后内存快炸了,查看任务管理器发现是vmmem的问题,是虚拟机资源分配的问题,这个问题上网查解决方法,不复杂
win+R,输入%UserProfile%- 如果没有
.wslconfig结尾的文件,可以新建一个,可以叫Vmmem.wslconfig - 添加以下内容
#.wslconfig [wsl2] memory=3GB //分配给WSL内存,可以是内存的1/3或1/4 swap=0 //设置交换分区 localhostForwarding=true - 重启WSL:
win+R,输入services.msc,找到LxssManager,重新启动
- 这个vmmem好像是个硬骨头啊!
wsl导致vmmem占用高解决办法 - 知乎
(👆文中借鉴WSL 2 consumes massive amounts of RAM and doesn’t return it - github.com)
按照这个方法做到最后一步发现👇
然后就找到了这个方法👇
drop_cashes无法操作 no such file or directory-CSDN社区
- 先
sudo su进入root - 输入
echo 3 > /proc/sys/vm/drop_caches - 然后再回去
sudo stat -c '%y' /root/drop_caches_last_run就能看到清除缓存的记录了
- vscode疯狂爆红,转clion去了
软件抽象资源和硬件资源的对应关系
【GPU结构与CUDA系列4】GPU存储资源:寄存器,本地内存,共享内存,缓存,显存等存储器细节_gpu内寄存器 - CSDN
如何高效访问gpu全局内存
(解答为什么v是按行连续分布和为什么要那样计算qkvgemm)
越靠近CPU排序:寄存器Register > 缓存Cache > 内存Memory > 硬盘
“C和CUDA中的多维数组元素是根据行优先约定放置在线性寻址的内存空间中的”
- 非按行排列:cublas API接受的输入以及输出的内存排布全部都默认为列主序
- “当线程访问矩阵数据时,如果数据排列的顺序与线程访问顺序匹配,内存带宽的利用率会更高”。这里应该和warp有关
- Fused SelfDecoder Attention kernel中,
block的大小是head_size,grid的大小是head_num*batch_size
👇根据线程访问顺序匹配(从blockIdx到threadIdx,threadIdx的跨度是顺序的)cache_offset = blockIdx.y * kv_head_num * max_seq_len * head_size + blockIdx.x/(head_num/kv_head_num)*max_seq_len*head_size+ threadIdx.x * vec_size;

- Fused SelfDecoder Attention kernel中,
- 一次数据传输的数据量默认情况下是32个字节
- $合并度=\dfrac{线程束请求的字节数}{由该请求导致的所有数据传输处理的字节数}$
- 数据传输对数据地址的要求:在一次数据传输中,从全局内存转移到L2缓存的一片内存首地址一定是一个最小颗粒度(该例子是32)的整数倍。
- 一次传输只取0~31、32~63、64~95……

👇左行右列导致跨越式的非合并访问
- 一次传输只取0~31、32~63、64~95……



