1 创建net
1.1 torch.nn.Module()
Base class for all neural network modules
1.1.1 Variables
cuda(device=None)
Moves all model parameters and buffers to the GPU
将所有模型参数和缓冲区移至 GPUeval()
Sets the module in evaluation mode
将模块设置为评估模式 ^evalforward()
Defines the computation performed at every call.
定义每次调用时执行的计算 ^forward1.2 阅读论文后得到net的参数
关注$C_{in}$、$C_{out}$、$kernel_size$、$padding$、$stride$
其中,$stride$需要根据公式计算得出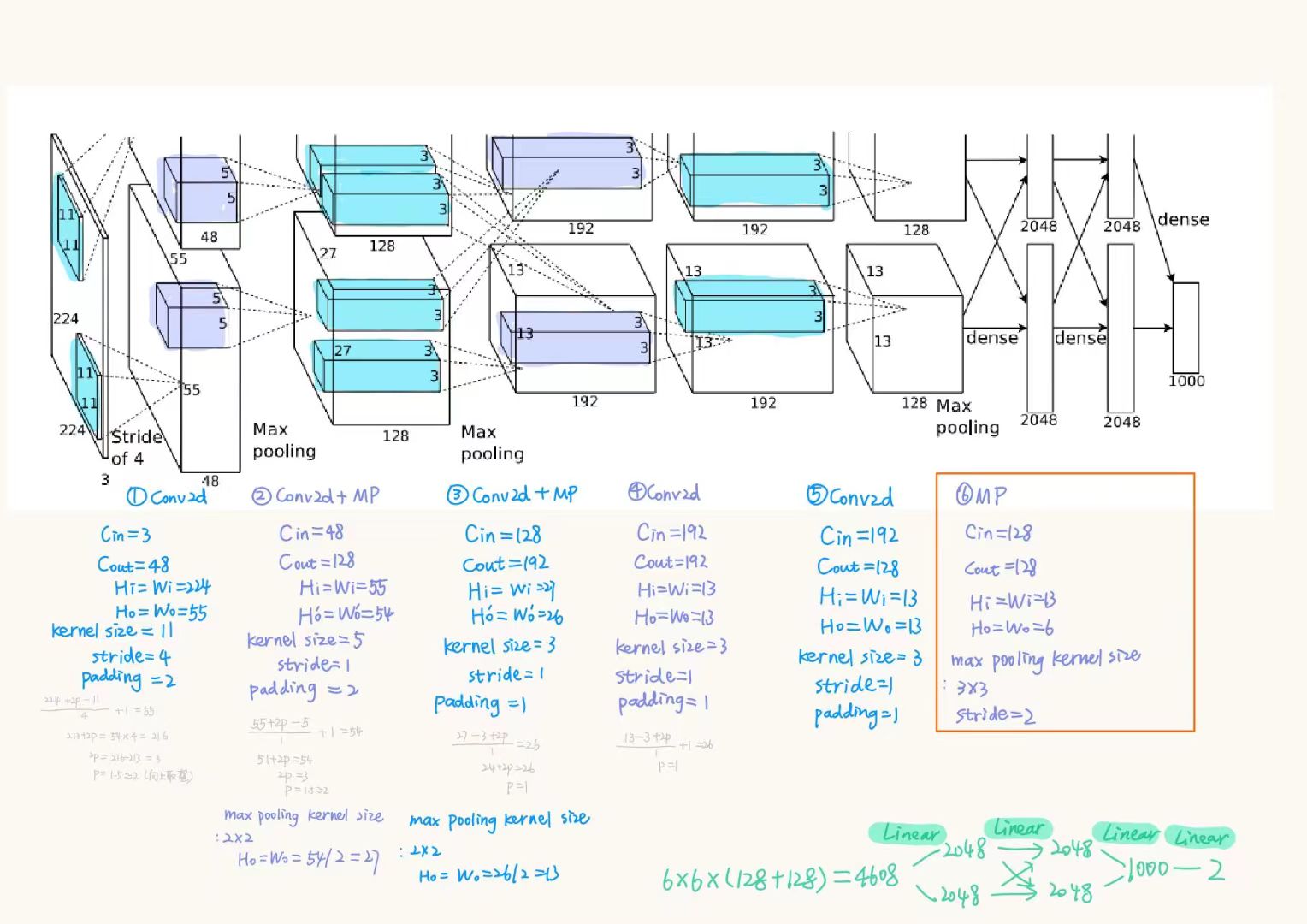 )
)
1.3 编写init
定义每个步骤的具体执行过程
e.g.
self.c1 = nn.Conv2d(in_channels=3, out_channels=48, kernel_size=11, stride=4, padding=2)这里规定c1的执行过程是接收输入通道为$3$的图像,用size为$11$的kernel…最后以输出通道为$48$作为输出
1.4 编写forward
[[#^forward]]
按照卷积的顺序进行x的更迭
1.5 测试
if __name__ == '__main__':
...当这段代码只在直接运行当前脚本时才会执行,如果当前脚本被其他脚本引入作为模块使用,则这部分代码不会执行。
通常会对x和y赋予简单的数字对net进行测试
2 划分数据集
2.1 创建文件
# 如果文件不存在,则创建文件
def mkfile(file):
if not os.path.exists(file):
os.makedirs(file)- 遍历所有类别的图像
images存储了原始data下cla分别为Cat和Dog的图像名称 - 按比例划分为训练集和测试集
eval_index是images中的随机抽取的$\dfrac{2}{10}$的图像名称的集合
随后再次遍历images
- 如果图像的名字在
eval_index中存在,则将这个图像复制到新路径data/val/+cla(val中Cat或Dog的文件下) - 如果不在
eval_index中存在,则复制到data/train/+cla中
3 编写train.py
3.1 用到的库
3.1.1 torchvision.transforms
.Normalize(mean, std, inplace=False)
ps: It’s scriptable transforms, which can’t use [[#^Compose]] :)
归一化处理
output[channel] = (input[channel] - mean[channel] / std[channel])
^normalize.Compose(transforms)
Composes several transforms together.This transform does not support torchscript.
^Compose
3.1 对图像像素归一化处理
[[#^normalize]]
normalize = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) # 减0.5再除0.5最后归一化到[-1, 1]之间3.2 训练集和验证集预处理
# 训练集预处理
train_transform = transforms.Compose([
transforms.Resize((224, 224)), # Resize the input image to the given size.因此将参数设置为论文中网络输入的参数大小
transforms.RandomVerticalFlip(), # 随机垂直旋转,使数据集更多
transforms.ToTensor(), # 转换为张量
normalize # 归一化
])
#验证集预处理
val_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
normalize
])[[#^Compose]]
创建数据集👇
train_dataset = ImageFolder(ROOT_TRAIN, transform=train_transform)
val_dataset = ImageFolder(ROOT_TEST, transform=val_transform)ImageFolder用于创建一个数据集,该数据集包含了图像数据和相应的标签
👇设置批量加载
train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=32, shuffle=True)DataLoader用于从数据集中加载批量数据的工具每批数据有32个样本
shuffle=True表示每个epoch开始前对数据继续随机排序
3.4 使用GPU加载数据
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(device)
model = MyAlexNet().to(device) # 将'MyAlexNet'实例化对象移动到'device'上3.5 定义损失函数和优化器并设置学习率
# 定义一个损失函数
loss_fn = nn.CrossEntropyLoss()
# 定义一个优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9) # 将模型参数传给优化器
# 学习率每隔10轮变为原来的0.5
lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.5) # 帮助优化器再训练过程中逐步减小学习率3.6 定义训练函数和损失函数
①从dataloader中取出图像数据和对应的标签
②计算cur_loss和cur_acc^train
def train(dataloader, model, loss_fn, optimizer):
loss, current, n = 0.0, 0.0, 0
for batch, (x, y) in enumerate(dataloader): # 将数据取出来训练
image, y = x.to(device), y.to(device)
output = model(image)
cur_loss = loss_fn(output, y)
_, pred = torch.max(output, axis=1)
cur_acc = torch.sum(y==pred)/output.shape[0]③反向传播
# 反向传播
optimizer.zero_grad()
cur_loss.backward()
optimizer.step()④计算$\dfrac{所有损失值}{个数}$和$\dfrac{所有正确值}{个数}$
loss += cur_loss.item()
current += cur_acc.item()
n = n+1
train_loss = loss / n
train_acc = current / n
print('train_loss' + str(train_loss))
print('train_acc' + str(train_acc))
return train_loss, train_acc损失函数除了不需要反向传播,其他都和训练函数类似
3.7 定义画图函数
# 定义一个画图函数
def matplot_loss(train_loss, val_loss):
plt.plot(train_loss, label='train_loss')
plt.plot(val_loss, label='val_loss')
plt.legend(loc='best')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.title("训练集和验证集loss值对比图")
plt.show()
def matplot_acc(train_acc, val_acc):
plt.plot(train_acc, label='train_acc')
plt.plot(val_acc, label='val_acc')
plt.legend(loc='best')
plt.ylabel('acc')
plt.xlabel('epoch')
plt.title("训练集和验证集acc值对比图")
plt.show()3.8 开始训练
①初始化四个list,定义epoch和min_acc
loss_train = []
acc_train = []
loss_val = []
acc_val = []
epoch = 20
min_acc = 0 # 最小精确度,找出最好的模型②调用
train和val函数进行训练[[#^train]]
for t in range(epoch):
lr_scheduler.step()
print(f"epoch{t+1}\n-------")
train_loss, train_acc = train(train_dataloader, model, loss_fn, optimizer)
val_loss, val_acc = val(val_dataloader, model, loss_fn)③计算得到的
train_loss、train_acc、val_loss、val_acc分别放入到初始化的四个list中# 列表
loss_train.append(train_loss)
acc_train.append(train_acc)
loss_val.append(val_loss)
acc_val.append(val_acc)④保存最好的权重和最后一轮的权重
# 保存最好的权重
if val_acc > min_acc:
folder = 'save_model'
if not os.path.exists(folder):
os.mkdir('save_model')
min_acc = val_acc
print(f"save best model, 第{t+1}轮")
torch.save(model.state_dict(), 'save_model/best_model.pth')
# 保存最后一轮的权重文件
if t == epoch-1:
torch.save(model.state_dict(), 'save_model/last_model.pth')如果有
val_acc(某一个轮次训练得到的)大于min_acc,则说明该次的训练效果暂时是目前最好的,保存到.save_model/best_model.pth中
3.9 画图
matplot_loss(loss_train, loss_val)
matplot_acc(acc_train, acc_val)4 编写test.py
4.1 训练集和验证集预处理、调用GPU
train_transform = transforms.Compose([
transforms.Resize((224, 224)), # Resize the input image to the given size.因此将参数设置为论文中网络输入的参数大小
transforms.RandomVerticalFlip(), # 随机垂直旋转,使数据集更多
transforms.ToTensor(), # 转换为张量
])
#验证集预处理
val_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
normalize
])
train_dataset = ImageFolder(ROOT_TRAIN, transform=train_transform)
val_dataset = ImageFolder(ROOT_TEST, transform=val_transform)
train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=32, shuffle=True)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(device)
model = MyAlexNet().to(device) # 将'MyAlexNet'实例化对象移动到'device'上4.2 加载模型
加载best_model.pth
model.load_state_dict(torch.load("E:/Project/Cat_and_Dog_Classification/save_model/best_model.pth"))4.3 验证阶段
model.eval()
for i in range(3000, 3010):
x, y = val_dataset[i][0], val_dataset[i][1] # x为第i张照片的的图片,y为第i张图片的标签
show(x).show()
x = Variable(torch.unsqueeze(x, dim=0).float(), requires_grad=True).to(device)
x = torch.tensor(x).to(device)model.eval()
[[#^eval]]torch.unsqueeze(x, dim=0)将x在维度0上添加一个维度,大小为1(批次维度)
在禁止梯度计算的情况下得到predicted和actual
with torch.no_grad():
pred = model(x)
predicted, actual = classes[torch.argmax(pred[0])], classes[y]
print(f'predicted:"{predicted}", Actual:"{actual}"')pred:tensor([[-2.1302, 2.3210]], device='cuda:0')y:0(Cat)或者1(Dog)



